技术特征:
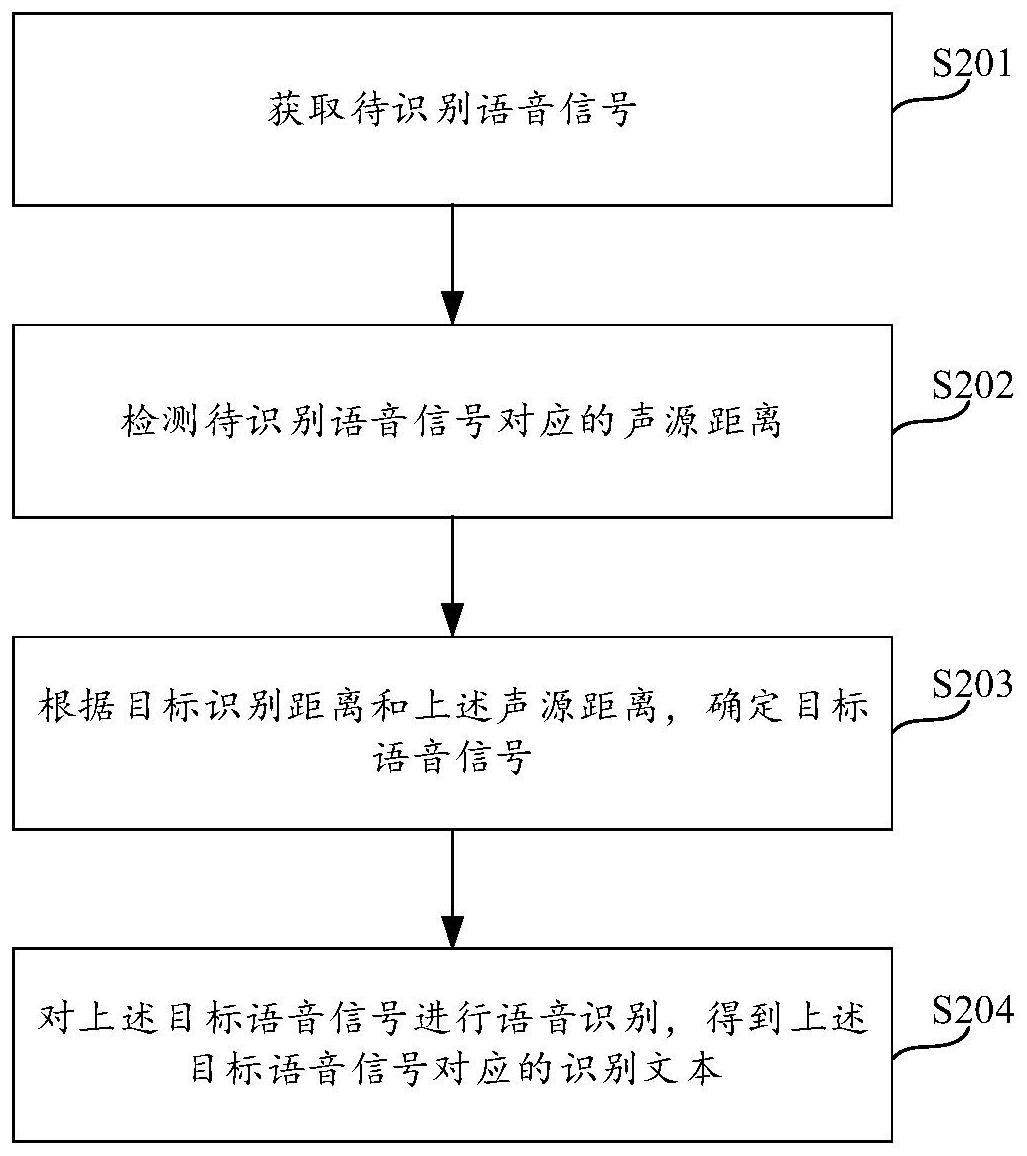
1.一种语音识别方法,应用于电子设备,其特征在于,包括:响应于用户的第一操作,设置语音识别距离;获取第一待识别语音信号;检测所述第一待识别语音信号对应的第一声源距离;根据设置的语音识别距离和所述第一声源距离,从所述第一待识别语音信号中确定第一目标语音信号;对所述第一目标语音信号进行语音识别,得到第一识别文本。2.如权利要求1所述的方法,其特征在于,所述响应于用户的第一操作,设置语音识别距离,包括:显示所述语音识别距离的设置界面,并在所述设置界面中显示多个可选择的距离,所述多个可选择的距离对应多个不同的语音识别距离区间;检测到用户在所述设置界面上的第一操作;响应于所述第一操作,设置所述语音识别距离。3.如权利要求1或2所述的方法,其特征在于,所述检测所述第一待识别语音信号对应的第一声源距离,包括:通过神经网络模型检测所述第一待识别语音信号对应的第一声源距离。4.如权利要求1至3中任一项所述的方法,其特征在于,所述第一待识别语音信号包括多个子语音信号;所述检测所述第一待识别语音信号对应的第一声源距离,包括:检测所述多个子语音信号中每个子语音信号对应的声源距离。5.如权利要求4所述的方法,其特征在于,所述根据设置的语音识别距离和所述第一声源距离,从所述第一待识别语音信号中确定第一目标语音信号,包括:根据设置的语音识别距离和所述每个子语音信号对应的声源距离,从所述多个子语音信号中确定第一目标语音信号。6.如权利要求1至5中任一项所述的方法,其特征在于,所述根据设置的语音识别距离和所述第一声源距离,从所述第一待识别语音信号中确定第一目标语音信号,包括:将所述第一待识别语音信号中所述第一声源距离小于或等于所述设置的语音识别距离的语音信号确定为第一目标语音信号;或者,根据所述语音识别距离确定距离上限值和距离下限值;将所述第一待识别语音信号中所述第一声源距离大于或等于所述距离下限值且小于或等于所述距离上限值的语音信号,确定为第一目标语音信号。7.如权利要求1至5中任一项所述的方法,其特征在于,在所述获取第一待识别语音信号之后,还包括:检测所述第一待识别语音信号对应的语音参数,所述语音参数包括人声概率;所述根据设置的语音识别距离和所述第一声源距离,从所述第一待识别语音信号中确定第一目标语音信号,包括:将所述第一待识别语音信号中所述第一声源距离小于或等于所述设置的语音识别距离且所述人声概率大于或等于预设人声概率阈值的语音信号,确定为第一目标语音信号。8.如权利要求3所述的方法,其特征在于,所述神经网络模型为双目标神经网络模型,
所述双目标神经网络模型包括输入层、卷积子网络和全连接子网络;所述输入层用于接收所述第一待识别语音信号,将所述第一待识别语音信号传递给所述卷积子网络;所述卷积子网络用于通过卷积的方式对所述第一待识别语音信号进行特征提取,得到语音特征,将所述语音特征传递给所述全连接子网络;所述全连接子网络包括第一全连接层和第二全连接层;所述第一全连接层用于对所述语音特征进行识别,输出所述待识别的语音信号对应的第一声源距离;所述第二全连接层用于对所述语音特征进行识别,输出所述第一待识别语音信号对应的人声概率。9.如权利要求1所述的方法,其特征在于,所述第一待识别语音信号包括至少一帧语音帧,所述第一声源距离包括所述至少一帧语音帧对应的声源距离;所述根据设置的语音识别距离和所述第一声源距离,从所述第一待识别语音信号中确定第一目标语音信号,包括:根据设置的语音识别距离和所述至少一帧语音帧对应的声源距离,确定所述至少一帧语音帧对应的帧标签,所述帧标签用于指示所述至少一帧语音帧为有效帧或无效帧;根据所述至少一帧语音帧对应的帧标签,确定目标语音帧。10.如权利要求9所述的方法,其特征在于,所述根据所述至少一帧语音帧对应的帧标签,确定目标语音帧,包括:当所述电子设备处于休眠态时,若检测到有效帧,则进入休眠工作转换态;当所述电子设备处于休眠工作转换态时,开始累计有效帧的帧数;在累计有效帧的过程中,若检测到无效帧,则停止累计有效帧的帧数,返回休眠态;若累计的有效帧的帧数大于或等于第一帧数,则进入工作态,确定一起始点;当所述电子设备处于工作态时,若检测到无效帧,则进入工作休眠转换态;当所述电子设备处于工作休眠转换态时,开始累计无效帧的帧数;在累计无效帧的过程中,若检测到有效帧,则停止累计无效帧的帧数,返回工作态;若累计的无效帧的帧数大于或等于第二帧数,则进入休眠态,确定一结束点;将所述起始点和所述结束点之间的语音帧确定为目标语音帧。11.如权利要求9所述的方法,其特征在于,所述根据所述至少一帧语音帧对应的帧标签,确定目标语音帧,包括:当检测到有效帧时,确定一起始点;当检测到无效帧时,确定一结束点;将所述起始点和所述结束点之间的语音帧确定为目标语音帧。12.如权利要求9所述的方法,其特征在于,所述根据所述至少一帧语音帧对应的帧标签,确定目标语音帧,包括:将所述有效帧确定为目标语音帧。13.如权利要求1至12中任一项所述的方法,其特征在于,所述第一目标语音信号包括多个子目标信号;所述对所述第一目标语音信号进行语音识别,得到第一识别文本,包括:对所述多个子目标信号进行语音识别,得到所述多个子目标信号中每个子目标信号对应的识别文本。
14.如权利要求1至13中任一项所述的方法,其特征在于,在所述得到第一识别文本之后,还包括:响应于用户的第二操作,更改所述语音识别距离;获取第二待识别语音信号;检测所述第二待识别语音信号对应的第二声源距离;根据更改的语音识别距离和所述第二声源距离,从所述第二待识别语音信号中确定第二目标语音信号;对所述第二目标语音信号进行语音识别,得到第二识别文本。15.一种电子设备,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,其特征在于,所述电子设备被配置为执行所述计算机程序时实现如权利要求1至14中任一项所述的方法。16.一种语音识别装置,应用于电子设备,其特征在于,包括:距离设置模块,用于响应于用户的第一操作,设置语音识别距离;语音录制模块,用于获取第一待识别语音信号;距离检测模块,用于检测所述第一待识别语音信号对应的第一声源距离;语音确定模块,用于根据设置的语音识别距离和所述第一声源距离,从所述第一待识别语音信号中确定第一目标语音信号;语音识别模块,用于对所述第一目标语音信号进行语音识别,得到第一识别文本。17.如权利要求16所述的装置,其特征在于,所述距离设置模块,具体用于实施以下步骤:显示所述语音识别距离的设置界面,并在所述设置界面中显示多个可选择的距离,所述多个可选择的距离对应多个不同的语音识别距离区间;检测到用户在所述设置界面上的第一操作;响应于所述第一操作,设置所述语音识别距离。18.如权利要求16或17所述的装置,其特征在于,所述距离检测模块,具体用于通过神经网络模型检测所述第一待识别语音信号对应的第一声源距离。19.如权利要求16至18中任一项所述的装置,其特征在于,所述第一待识别语音信号包括多个子语音信号;所述距离检测模块,具体用于检测所述多个子语音信号的每个子语音信号对应的声源距离。20.如权利要求19所述的装置,其特征在于,所述语音确定模块,具体用于根据设置的语音识别距离和所述每个子语音信号对应的声源距离,从所述多个子语音信号中确定第一目标语音信号。21.一种计算机可读存储介质,所述计算机可读存储介质被配置为存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现如权利要求1至14中任一项所述的方法。22.一种芯片系统,其特征在于,所述芯片系统包括存储器和处理器,所述处理器被配置为执行所述存储器中存储的计算机程序,以实现如权利要求1至14中任一项所述的方法。
技术总结
本申请适用于语音识别技术领域,提供了一种语音识别方法、电子设备及计算机可读存储介质。在本申请提供的语音识别方法中,电子设备可以响应于用户的第一操作,设置语音识别距离。后续,当电子设备获取到第一待识别语音信号时,电子设备可以检测第一待识别语音信号对应的第一声源距离。然后,电子设备可以根据设置的语音识别距离和上述第一声源距离,从第一待识别语音信号中确定第一目标语音信号并进行语音识别,得到第一识别文本。通过上述方法,电子设备可以根据用户设置的语音识别距离间接控制语音识别模型的灵敏度,使得相同的语音识别模型可以适用于不同的语音交互场景,有效提高了用户的使用体验,具有较强的易用性和实用性。用性。用性。
技术研发人员:陈家胜 朱星宇
受保护的技术使用者:华为技术有限公司
技术研发日:2022.01.29
技术公布日:2023/8/8
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。