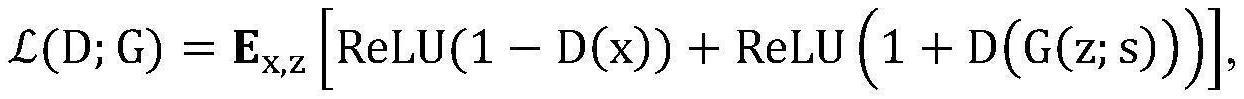技术特征:
1.一种音频发生器(10),被配置为从输入信号(14)和目标数据(12)生成音频信号(16),目标数据(12)表示音频信号(16),音频发生器(10)包括:第一处理块(40,50,50a-50h),被配置为接收从输入信号(14)得出的第一数据(15,59a)并输出第一输出数据(69),其中第一输出数据(69)包括多个通道(47),以及第二处理块(45),被配置为作为第二数据接收第一输出数据(69)或从第一输出数据(69)得到的数据;其中,第一处理块(50)对于第一输出数据的每个通道包括:可学习层(71,72,73)的条件集,被配置为处理目标数据(12)以获得条件特征参数(74,75),目标数据(12)从文本得到;以及样式元件(77),被配置为将条件特征参数(74,75)应用于第一数据(15,59a)或归一化的第一数据(59,76’);以及其中,第二处理块(45)被配置为将第二数据(69)的多个通道(47)组合以获得音频信号(16)。2.根据权利要求1所述的音频发生器,其中目标数据(12)是谱图。3.根据上述权利要求中任一项所述的音频发生器,其中目标数据(12)是梅尔谱图。4.根据上述权利要求中任一项所述的音频发生器,其中目标数据(12)包括从文本获得的对数谱图或mfcc和梅尔谱图或另一类型的谱图中的至少一个声学特征。5.根据上述权利要求中任一项所述的音频发生器,被配置为通过将文本或文本元素形式的输入转换(1110)为至少一个声学特征来获得目标数据(12)。6.根据上述权利要求中任一项所述的音频发生器,被配置为通过将至少一个语言学特征转换(1114)为至少一个声学特征来获得目标数据(12)。7.根据上述权利要求中任一项所述的音频发生器,其中目标数据(12)包括从文本获得的音素、单词韵律、语调、短语中断和填充停顿中的至少一个语言学特征。8.根据权利要求7所述的音频发生器,被配置为通过将文本或文本元素形式的输入转换(1110)为至少一个语言学特征来获得目标数据(12)。9.根据上述权利要求中任一项所述的音频发生器,其中目标数据(12)包括从文本获得的字符和单词中的至少一个。10.根据上述权利要求中任一项所述的音频发生器,其中目标数据(12)使用执行文本分析和/或使用声学模型的统计模型从文本(112)得出。11.根据上述权利要求中任一项所述的音频发生器,其中目标数据(12)使用执行文本分析和/或使用声学模型的可学习模型从文本(112)得出。12.根据上述权利要求中任一项所述的音频发生器,其中目标数据(12)使用执行文本分析和/或声学模型的基于规则的算法从文本(112)得出。13.根据上述权利要求中任一项所述的音频发生器,被配置为通过至少一个确定性层得出目标数据。14.根据上述权利要求中任一项所述的音频发生器,被配置为通过至少一个可学习层得出目标数据。15.根据上述权利要求中任一项所述的音频发生器,其中可学习层的条件集由一个或至少两个卷积层(71-73)组成。
16.根据权利要求15所述的音频发生器,其中第一卷积层(71-73)被配置为使用第一激活函数对目标数据(12)或上采样的目标数据进行卷积以获得第一卷积数据(71’)。17.根据上述权利要求中任一项所述的音频发生器,其中可学习层(71-73)的条件集和样式元件(77)是包括一个或多个残差块(50,50a-50h)的神经网络的残差块(50,50a-50h)中的权重层的一部分。18.根据权利要求1至17中任一项所述的音频发生器,其中音频发生器(10)进一步包括被配置为归一化第一数据(59a,15)的归一化元件(76)。19.根据权利要求1至18中任一项所述的音频发生器,其中音频信号(16)为语音音频信号。20.根据权利要求1至19中任一项所述的音频发生器,其中目标数据(12)以至少2的因子被上采样。21.根据权利要求20所述的音频发生器,其中所述目标数据(12)通过非线性插值被上采样(70)。22.根据权利要求16或引用权利要求16时的权利要求17至21中任一项所述的音频发生器,其中第一激活函数是渗漏整流线性单元,渗漏relu,函数。23.根据权利要求1至22中任一项所述的音频发生器,其中卷积操作(61a,61b,62a,62b)以最大膨胀因子2运行。24.根据权利要求1至23中任一项所述的音频发生器,包括八个第一处理块(50a-50h)和一个第二处理块(45)。25.根据权利要求1至24中任一项所述的音频发生器,其中第一数据(15,59,59a,59b)具有比音频信号更低的维数。26.一种用于通过音频发生器(10)从输入信号(14)和目标数据(12)生成音频信号(16)的方法,目标数据(12)表示音频信号(16)并且从文本得到,方法包括:通过第一处理块(50,50a-50h)接收从输入信号(14)得到的第一数据(16559,59a,59b);对于第一输出数据(59b,69)的每个通道:通过第一处理块(50)的可学习层(71,72,73)的条件集处理目标数据(12),以获得条件特征参数(74、75);以及通过第一处理块(50)的样式元件(77)将条件特征参数(74,75)应用于第一数据(15,59)或归一化的第一数据(76’);通过第一处理块(50)输出包括多个通道(47)的第一输出数据(69);通过第二处理块(45)作为第二数据接收第一输出数据(69)或从第一输出数据(69)得出的数据;以及通过第二处理块(45)将第二数据的多个通道(47)组合以获得音频信号(16)。27.根据权利要求26所述的用于生成音频信号的方法,其中目标数据(12)包括从文本获得的对数谱图或mfcc和梅尔谱图或另一类型的谱图中的至少一个声学特征。28.根据权利要求26或27所述的用于生成音频信号的方法,包括通过将文本或文本元素形式的输入转换(1110)为至少一个声学特征来获得目标数据(12)。29.根据权利要求26、27或28所述的用于生成音频信号的方法,包括通过将至少一个语
言学特征转换(1114)为至少一个声学特征来获得目标数据(12)。30.根据权利要求26-29中任一项所述的用于生成音频信号的方法,其中目标数据(12)包括从文本获得的音素、单词韵律、语调、短语中断和填充停顿中的至少一个语言学特征。31.根据权利要求30所述的用于生成音频信号的方法,包括通过将文本或文本元素形式的输入转换(1110)为至少一个语言学特征来获得目标数据(12)。32.根据权利要求26-31中任一项所述的用于生成音频信号的方法,其中目标数据(12)包括从文本获得的字符和单词中的至少一个。33.根据权利要求26-32中任一项所述的用于生成音频信号的方法,进一步包括使用执行文本分析和/或使用声学模型的统计模型得出目标数据(12)。34.根据权利要求26-33中任一项所述的用于生成音频信号的方法,进一步包括使用执行文本分析和/或使用声学模型的可学习模型得出目标数据(12)。35.根据权利要求26-34中任一项所述的用于生成音频信号的方法,进一步包括使用执行文本分析和/或声学模型的基于规则的算法得出目标数据(12)。36.根据权利要求26-35中任一项所述的用于生成音频信号的方法,进一步包括通过至少一个确定性层得出目标数据(12)。37.根据权利要求26-35中任一项所述的用于生成音频信号的方法,进一步包括通过至少一个可学习层得出目标数据(12)。38.根据权利要求26-37中任一项所述的用于生成音频信号的方法,其中可学习层(71-73)的条件集由一个或两个卷积层组成。39.根据权利要求38所述的用于生成音频信号的方法,其中通过可学习层(71-73)的条件集的处理包括通过第一卷积层(71)使用第一激活函数对目标数据(12)或上采样的目标数据进行卷积以获得第一卷积数据(71’)。40.根据权利要求26至39中任一项所述的用于生成音频信号的方法,其中可学习层(71-73)的条件集和样式元件(77)是包括一个或多个残差块(50,50a-50h)的神经网络的残差块(50,50a-50h)中的权重层的一部分。41.根据权利要求26至40中任一项所述的用于生成音频信号的方法,其中方法进一步包括通过归一化元件(76)对第一数据(15,59)进行归一化。42.根据权利要求26至41中任一项所述的用于生成音频信号的方法,其中音频信号(16)为语音音频信号。43.根据权利要求26至42中任一项所述的用于生成音频信号的方法,其中目标数据(12)以2的因子被上采样(70)。44.根据权利要求26至43中任一项所述的用于生成音频信号的方法,其中目标数据(12)通过非线性插值被上采样(70)。45.根据权利要求26至44中任一项所述的用于生成音频信号的方法,其中第一激活函数是渗漏整流线性单元,渗漏relu,函数。46.根据权利要求26至45中任一项所述的用于生成音频信号的方法,其中卷积操作(61a,62a,61b,62b)以最大膨胀因子2运行。47.根据权利要求26至46中任一项所述的用于生成音频信号的方法,包括执行第一处理块(50,50a-50h)的步骤八次,以及执行第二处理块(45)的步骤一次。
48.根据权利要求26至47中任一项所述的用于生成音频信号的方法,其中第一数据(15,59)具有比音频信号更低的维数。49.根据权利要求26至48中任一项所述的用于生成音频信号的方法,进一步包括从文本得出目标数据。50.根据权利要求26至49中任一项所述的用于生成音频信号的方法,其中目标数据(12)是谱图。51.根据权利要求50所述的方法,其中谱图是梅尔谱图。52.一种用于训练(100)根据权利要求1至25中任一项所述的音频发生器(10)的方法,其中训练(100)包括重复权利要求26至51中任一项所述的步骤一次或多次。53.根据权利要求52所述的方法,进一步包括:通过至少一个评估器(132)评估(130)生成的音频信号(14,16),以及根据评估(130)的结果调整音频发生器(10)的权重(74,75)。54.根据权利要求53所述的方法,其中至少一个评估器(132)是神经网络。55.根据权利要求53或54所述的方法,进一步包括:根据评估的结果调整评估器的权重。56.根据权利要求52至55中任一项所述的方法,其中训练(130)包括优化损失函数(140)。57.根据权利要求56所述的方法,其中优化(130)损失函数包括计算生成的音频信号(16)和参考音频信号(104)之间的固定度量。58.根据权利要求57所述的方法,其中计算固定度量包括计算生成的音频信号(16)和参考音频信号(104)之间的一个或多个频谱失真。59.根据权利要求58所述的方法,其中对生成的音频信号(16)和参考音频信号(104)的频谱表示的幅度或对数幅度执行计算一个或多个频谱失真。60.根据权利要求58或59所述的方法,其中对生成的音频信号(16)和参考音频信号(104)的不同时间或频率分辨率执行计算一个或多个频谱失真。61.根据权利要求56至60中任一项所述的方法,其中优化损失函数(140)包括通过由一个或多个评估器(132)随机提供和评估生成的音频信号(16)的表示或参考音频信号(104)的表示来得出一个或多个对抗度量,其中评估包括将提供的音频信号(16,132)分类成预定数量的类别,预定数量的类别指示音频信号(14,16)的自然度的预训练分类水平。62.根据权利要求56至61中任一项所述的方法,其中优化损失函数包括通过一个或多个评估器(132)计算固定度量和得出对抗度量。63.根据权利要求62所述的方法,其中音频发生器(10)首先使用固定度量进行训练。64.根据权利要求61至63中任一项所述的方法,其中四个评估器(132a-132d)得出四个对抗度量。65.根据权利要求61或64中任一项所述的方法,其中评估器(132)在通过滤波器组(110)对生成的音频信号(16)的表示或参考音频信号(104)的表示进行分解(110)后操作。66.根据权利要求61至65中任一项所述的方法,其中评估器(132a-132d)中的每个接收生成的音频信号(16)的表示或参考音频信号(104)的表示的一个或多个部分(105a-105d)作为输入。
67.根据权利要求66所述的方法,其中通过使用随机窗口函数从输入信号(14)采样随机窗口(105a-105d)生成信号部分。68.根据权利要求66或67所述的方法,其中随机窗口(105a-105d)的采样对每个评估器(132a-132d)重复多次。69.根据权利要求67或68所述的方法,其中对于每个评估器(132a-132d),采样随机窗口(105a-105d)的次数与生成的音频信号的表示或参考音频信号(104)的表示的长度成比例。70.一种计算机程序产品,包括用于处理设备的程序,程序包括当程序在处理设备上运行时用于执行权利要求26至69所述的步骤的软件代码部分。71.根据权利要求70所述的计算机程序产品,其中计算机程序产品包括存储软件代码部分的计算机可读介质,其中程序可直接加载到处理设备的内部存储器中。72.一种用于生成音频信号(16)的方法,包括数学模型,其中数学模型被配置为从表示要生成的音频数据(16)的输入序列(12)以给定时间步长输出音频样本,其中,数学模型被配置为对噪声向量(14)进行整形,以便使用输入代表序列(12)创建输出音频样本,其中输入代表序列从文本得出。73.根据权利要求72所述的方法,其中使用音频数据训练数学模型。74.根据权利要求72至73中任一项所述的方法,其中数学模型是神经网络。75.根据权利要求74所述的方法,其中网络为前馈网络。76.根据权利要求74或75所述的方法,其中网络是卷积网络。77.根据权利要求72至76中任一项所述的方法,其中噪声向量(14)具有比要生成的音频信号(16)更低的维数。78.根据权利要求72至77中任一项所述的方法,其中使用时间自适应去归一化(tade)技术(60)用于调节使用输入代表序列(12)的数学模型,并因此用于对噪声向量(14)进行整形。79.根据权利要求74至78中任一项所述的方法,其中修改的softmax门控tanh(63a,64a,63b,64b,46)激活神经网络的每一层。80.根据权利要求76至79中任一项所述的方法,其中卷积操作以最大膨胀因子2运行。81.根据权利要求72至80中任一项所述的方法,其中对噪声向量(14)以及输入代表序列(12)进行上采样(70,30),以以目标采样率获得输出音频(16)。82.根据权利要求81所述的方法,其中在数学模型的不同层中依次执行上采样(70)。83.根据权利要求82所述的方法,其中每层的上采样因子为2或2的倍数。84.根据权利要求72至83中任一项所述的方法,其中输入代表序列是文本。85.根据权利要求72至83中任一项所述的方法,其中输入代表序列是谱图。86.根据权利要求85所述的方法,其中谱图是梅尔谱图。87.一种训练用于音频生成的神经网络的方法,其中,神经网络从表示要生成的音频数据(16)的输入序列(12)以给定的时间步长输出音频样本:其中,神经网络被配置为对噪声向量(14)进行整形,以便使用输入代表序列(12)创建
输出音频样本(16);其中,神经网络根据权利要求63至77中任一项所述被设计,以及其中,训练被设计为优化损失函数(140)。88.根据权利要求87所述的方法,其中损失函数包括在生成的音频信号(16)和参考音频信号(104)之间计算的固定度量。89.根据权利要求88所述的方法,其中固定度量是在生成的音频信号(16)和参考音频信号(104)之间计算的一个或多个频谱失真。90.根据权利要求89所述的方法,其中在生成的音频信号(16)和参考音频信号(104)的频谱表示的幅度或对数幅度上计算一个或多个频谱失真。91.根据权利要求89或90所述的方法,其中在不同的时间或频率分辨率上计算形成固定度量的一个或多个频谱失真。92.根据权利要求87至91中任一项所述的方法,其中损失函数包括由附加判别神经网络得出的对抗度量;其中,判别神经网络接收生成的音频信号(16)的表示或参考音频信号(104)的表示作为输入,以及其中,判别神经网络被配置为评估生成的音频信号(16)是否真实。93.根据权利要求87至92中任一项所述的方法,其中损失函数包括固定度量和由附加判别神经网络得出的对抗度量。94.根据权利要求88至93中任一项所述的方法,其中生成音频样本的神经网络首先仅使用固定度量进行训练。95.根据权利要求92或93或94所述的方法,其中对抗度量由4个判别神经网络(132a-132d)得出。96.根据权利要求92或93或94或95所述的方法,其中判别神经网络在通过滤波器组对输入音频信号进行分解后操作。97.根据权利要求92至96中任一项所述的方法,其中每个判别神经网络(132)接收输入音频信号的一个或多个随机加窗版本作为输入。98.根据权利要求97所述的方法,其中随机窗口(105a-105d)的采样对每个判别神经网络(132)重复多次。99.根据权利要求98所述的方法,其中对于每个判别神经网络(132),采样随机窗口(105a-105d)的次数与输入音频样本的长度成比例。100.根据权利要求72至99中任一项所述的方法,其中输入代表序列包括至少一个语言学特征。101.根据权利要求72至100中任一项所述的方法,其中输入代表序列包括至少一个文本特征。102.根据权利要求72至101中任一项所述的方法,其中输入代表序列包括至少一个声学特征。
技术总结
公开了用于生成音频信号和训练音频发生器的技术。音频发生器(10)可以从表示音频信号(16)的目标数据(12)和输入信号(14)生成音频信号(16)。目标数据(12)从文本得出。音频发生器包括:第一处理块(40,50,50a-50h),接收从输入信号(14)得出的第一数据(15,59a)并输出第一输出数据(69);第二处理块(45),作为第二数据接收第一输出数据(69)或从第一输出数据(69)得出的数据。第一处理块(50)包括:可学习层(71,72,73)的条件集,被配置为处理目标数据(12)以获得条件特征参数(74,75);以及样式元件(77),被配置为将条件特征参数(74,75)应用于第一数据(15,59a)或归一化的第一数据(59,76')。76')。
技术研发人员:艾哈迈德
受保护的技术使用者:弗劳恩霍夫应用研究促进协会
技术研发日:2021.10.13
技术公布日:2023/8/29
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。