sars-cov-2 s蛋白特异性抗体或其片段及其应用
技术领域
1.本发明属于抗体工程领域,具体涉及一种针对冠状病毒的单抗及其应用, 特别是涉及一种sars-cov-2 s蛋白特异性抗体或其片段、制备方法及应用。
背景技术:
2.尽管康复患者血浆疗法在临床上取得了一定的成效,然而由于抗原患者血 浆来源有限、纯化抗体安全隐患高、特异性抗体效价不稳定。效价高、性能稳 定、安全性好的单克隆抗体对于控制新冠状病毒疫情具有良好的应用前景。目 前现有文献已经公开或教导了针对新冠病毒rbd制备保护性中和单抗的报道。 利用新冠病毒刺突蛋白rbd产生抗新冠病毒的保护性中和抗体(如:biorxiv,
ꢀ“
sars-cov-2 and sars-cov spike-rbd structure and receptor bindingcomparison and potential implications on neutralizing antibody and vaccinedevelopment”,20200220)。sars刺突蛋白rbd和新冠病毒刺突蛋白rbd存 在交叉中和表位肽,抗sars的单克隆抗体cr3022能够结合新冠病毒刺突蛋 白rbd(emerging microbes&infections,9(1):382-385,20200217)。采用同源建 模的方法明确了新冠病毒病毒ctd1/人ace2复合物的蛋白-蛋白相互作用界面 的热点和关键残基,筛选靶向ctd1区域与ace2结合表面的候选抑制剂,阻 断病毒与人体ace2蛋白的识别与结合。
3.随着抗sars-cov-2疫苗和治疗性抗体研究的持续推进,最近有报道表明 部分治疗性抗体用于sars-cov-2治疗时可产生ade现象。所谓的ade,是 指抗体依赖的增强作用,某些病毒在特异性抗体协助下复制或感染能力显著增 强,在感染过程中会引发更严重病理损伤。通俗的解释就是,抗体不能中和病 毒,反而充当了“特洛伊木马”,让病毒感染免疫细胞的能力更强,产生更多的 子代病毒,造成严重症状。
4.迄今为止,阻断新冠病毒结合宿主ace2的单克隆抗体仍停留在理论研究 阶段,尚没有序列结构清楚、阻断新冠病毒结合功能明确的单克隆抗体的现有 技术报道。另外,现有技术中关于抗sars-cov-2 s蛋白抗体的研究发现在 sars-cov-2感染宿主细胞过程中存在着抗体依赖的增强效应(ade),为sars-cov-2疫苗和治疗性抗体的研究带来困难。
[0005][0006]
技术实现要素:
[0007]
为解决上述问题,本发明从新冠病毒感染后康复人员pbmc中分离冠状病 毒纤突蛋白rbd特异性记忆b细胞、扩增获得抗体轻重链可变区序列,连接导 入载体、重组表达获得重组人源单抗,从中选择出与sars-cov-2纤突蛋白rbd 亲和力高、对sars-cov-2纤突蛋白rbd与宿主受体aceii阻断力强、对病毒 侵染细胞的中和活力强的单抗,进而对所述单抗的ade效应的进行筛选,最终 获得一株不产生ade现象的抗sars-cov-2 s蛋白特异性抗体mw07。具体而 言:
[0008]
第一方面,本发明提供一种sars-cov-2 s蛋白特异性抗体或其片段,其特 征在于
所述抗体或其片段的特异性结合的抗原表位是存在于sars-cov-2 s1蛋 白上的抗原表位,并且不存在于sars-cov s1蛋白、mers-cov s1蛋白上。
[0009]
进一步,本发明所述sars-cov-2 s蛋白特异性抗体或其片段,其特征在于 所述抗体或其片段特异性结合的抗原表位位于sars-cov-2的受体结合域rbd。
[0010]
进一步,本发明所述sars-cov-2 s蛋白特异性抗体或其片段,其特征在于 所述抗体或其片段以剂量依赖的方式抑制sars-cov-2感染宿主细胞。
[0011]
进一步,本发明所述sars-cov-2 s蛋白特异性抗体或其片段,其特征在于 所述抗体或其片段用于治疗sars-cov-2感染时,不会导致明显的抗体依赖的增 强效应(ade)。
[0012]
进一步,本发明所述sars-cov-2 s蛋白特异性抗体或其片段,其特征在于 所述抗体或其片段能够通过阻断sars-cov-2与宿主细胞受体aceii的结合而发 挥中和作用,其中阻断sars-cov-2与宿主细胞受体aceii结合的ic50小于 500ng/ml,例如小于200ng/ml,优选小于100ng/ml,更优选小于80ng/ml。
[0013]
进一步,本发明所述sars-cov-2 s蛋白特异性抗体或其片段,其特征在于 所述抗体或其片段的重链可变区cdr1-3分别与seq id no:10所示重链可变区的 cdr1-3具有100%的序列同源性;轻链可变区cdr1-3分别与seq id no:9所示 轻链可变区的cdr1-3具有100%的序列同源性。
[0014]
进一步,本发明所述sars-cov-2 s蛋白特异性抗体或其片段,其特征在于 所述抗体或其片段的重链可变区cdr1-3的氨基酸序列分别为seq id no:14-16, 轻链可变区cdr1-3的氨基酸序列分别为seq id no:11-13。
[0015]
进一步,本发明所述sars-cov-2 s蛋白特异性抗体或其片段,其特征在于 所述抗体或其片段的重链可变区与seq id no:10具有70%以上的序列同源性; 轻链可变区与seq id no:9具有70%以上的序列同源性。
[0016]
第二方面,本发明提供一种sars-cov-2 s蛋白特异性抗体或其片段,其特 征在于:通过fortebio表位竞争结合实验检测,所述单抗或其片段与本发明第 一方面所述抗体或其片段具有竞争关系。
[0017]
进一步,本发明所述抗体或其片段,包括鼠抗体、兔抗体、山羊抗体、绵 羊抗体、骆驼抗体、羊驼抗体、嵌合抗体、人抗体、人源化抗体、fab、f(ab’)2、 fv、scfv、fd、重链抗体、纳米抗体等。
[0018]
第三方面,本发明提供一种组合物,其包含一种或多种sars-cov-2 s蛋白 特异性抗体或其片段,所述抗体或其片段选自由本发明第一方面所述 sars-cov-2 s蛋白特异性抗体或其片段组成的组。
[0019]
进一步,本发明所述组合物,其特征在于还包含药学上可接受的载体,并 作为药物组合物使用,优选所述药物组合物为水剂、针剂、粉针剂。
[0020]
第四方面,本发明提供抗体或其片段在制备治疗冠状病毒感染药物中的应 用,其特征在于:所述抗体或其片段包含一种或多种选自由本发明第一方面所 述sars-cov-2 s蛋白特异性抗体或其片段组成的组。
[0021]
进一步,本发明所述的应用,其特征在于所述冠状病毒感染包括sars-cov-2 感染。
[0022]
第五方面,本发明提供一种多核苷酸,其编码本发明第一方面所述 sars-cov-2 s
蛋白特异性抗体或其片段。
[0023]
第六方面,本发明提供载体,其包含本发明第五方面所述的多核苷酸。
[0024]
第七方面,本发明提供宿主细胞,其包含本发明第五方面所述的多核苷酸 或本发明第六方面所述的载体。
[0025]
第八方面,本发明提供一种制备sars-cov-2 s蛋白特异性抗体或其片段的 方法,其包括以下步骤:
[0026]
(1)在适合表达重组sars-cov-2 s蛋白特异性抗体或其片段的条件下培养 本发明第七方面所述宿主细胞;
[0027]
(2)从细胞培养物中分离纯化sars-cov-2 s蛋白特异性抗体或其片段。。
[0028]
为更好理解本发明,首先定义一些术语。其他定义则贯穿具体实施方式部 分而列出。
[0029]
术语“冠状病毒”是指套式病毒目(nidovirales)、冠状病毒科 (coronaviridae)、冠状病毒属(coronavirus)的成员。本发明所述冠状病毒 主要涉及感染人的冠状病毒,包括hcov-229e、hcov-oc43、hcov-nl63、 hcov-hku1、sars-cov、mers-cov、sars-cov-2(2019-ncov),本发明 所述冠状病毒特别涉及sars-cov、mers-cov、sars-cov-2(2019-ncov)。
[0030]
术语“特异性”是指在蛋白和/或其他生物异质群体中确定是否存在所述蛋 白,例如本发明所述单抗与sars-cov-2 rbd蛋白的结合反应。因此,在所指 定的条件下,特定的配体/抗原与特定的受体/抗体结合,并且并不以显著的量与 样本中存在的其它蛋白结合。
[0031]
本文中的术语“抗体”意在包括全长抗体及其任何抗原结合片段(即,抗原结 合部分)或单链。全长抗体是包含至少两条重(h)链和两条轻(l)链的糖蛋白,重 链和轻链由二硫键连接。各重链由重链可变区(简称vh)和重链恒定区构成。重 链恒定区由三个结构域构成,即ch1、ch2和ch3。各轻链由轻链可变区(简 称vl)和轻链恒定区构成。轻链恒定区由一个结构域cl构成。vh和vl区还 可以划分为称作互补决定区(cdr)的高变区,其由较为保守的框架区(fr)区分隔 开。各vh和vl由三个cdr以及四个fr构成,从氨基端到羧基端以fr1、 cdr1、fr2、cdr2、fr3、cdr3、fr4的顺序排布。重链和轻链的可变区包 含与抗原相互作用的结合域。抗体的恒定区可以介导免疫球蛋白与宿主组织或 因子的结合,包括多种免疫系统细胞(例如,效应细胞)和传统补体系统的第一 组分(c1q)。
[0032]
术语“单克隆抗体”或“单抗”或“单克隆抗体组成”是指单一分子组成的抗体 分子制品。单克隆抗体组成呈现出对于特定表位的单一结合特异性和亲和力。
[0033]
本文中的术语,抗体的“抗原结合片段”(或简称为抗体部分),是指抗体的保 持有特异结合抗原能力的一个或多个片段。已证实,抗体的抗原结合功能可以 通过全长抗体的片段来实施。包含在抗体的“抗原结合部分”中的结合片段的例 子包括(i)fab片段,由vl、vh、cl和ch1构成的单价片段;(ii)f(ab
′
)2片段, 包含铰链区二硫桥连接的两个fab片段的二价片段;(iii)由vh和ch1构成的 fd片段;(iv)由抗体单臂vl和vh构成的fv片段;(v)由vh构成的dab片段 (ward et al.,(1989)nature 341:544-546);(vi)分离的互补决定区(cdr);以及(vii) 纳米抗体,一种包含单可变结构域和两个恒定结构域的重链可变区。此外,尽 管fv片段的两个结构域vl和vh由不同的基因编码,它们可以通过重组法经 由使两者成为单蛋白链的合成接头而连接,其中vl和vh区配对形成单价分 子(称为单链fc(scfv);参见例如bird et al.,(1988)science 242:423-426;and huston et al.,(1988)
proc.natl.acad.sci.usa 85:5879-5883)。这些单链抗体也意 在包括在术语涵义中。这些抗体片段可以通过本领域技术人员已知的常用技术 而得到,且片段可以通过与完整抗体相同的方式进行功能筛选。
[0034]
本发明的抗原结合片段包括能够特异性结合冠状病毒rbd的那些。抗体结 合片段的实例包括例如但不限于fab、fab'、f(ab')2、fv片段、单链fv(scfv) 片段和单结构域片段。
[0035]
fab片段含有轻链的恒定结构域和重链的第一恒定结构域(ch1)。fab'片 段与fab片段的不同之处在于在重链ch1结构域的羧基末端处的少数残基的添 加,包括来自抗体铰链区的一个或多个半胱氨酸。通过切割在f(ab')2胃蛋 白酶消化产物的铰链半胱氨酸处的二硫键产生fab'片段。抗体片段的另外化学 偶联是本领域普通技术人员已知的。fab和f(ab')2片段缺乏完整抗体的片 段可结晶(fc)区,从动物的循环中更快速地清除,并且可能具有比完整抗体 更少的非特异性组织结合(参见例如,wahl等人,1983,j.nucl.med.24:316)。
[0036]
如本领域通常理解的,“fc”区是不包含抗原特异性结合区的抗体的片段 可结晶恒定区。在igg、iga和igd抗体同种型中,fc区由两个相同的蛋白质 片段组成,衍生自抗体的两条重链的第二和第三恒定结构域(分别为ch2和ch3 结构域)。igm和ige fc区在每条多肽链中含有三个重链恒定结构域(ch2、 ch3和ch4结构域)。
[0037]“fv”片段是含有完整靶识别和结合位点的抗体的最小片段。该区域由以 紧密的非共价结合的一个重链和一个轻链可变结构域的二聚体(vh-vl二聚体) 组成。在该构型中,每个可变结构域的三个cdr相互作用,以限定在vh-vl二 聚体的表面上的靶结合位点。通常,六个cdr对抗体赋予靶结合特异性。然而, 在一些情况下,甚至单个可变结构域(或仅包含对于靶特异性的三个cdr的fv 的一半)可以具有识别且结合靶的能力,尽管其亲和力低于整个结合位点。
[0038]“单链fv”或“scfv”抗体结合片段包含抗体的vh和vl结构域,其中这 些结构域存在于单条多肽链中。一般地,fv多肽进一步包含在vh和vl结构域 之间的多肽接头,其致使scfv能够形成有利于靶结合的结构。
[0039]“单结构域片段”由对冠状病毒rbd显示出足够亲和力的单个vh或vl结 构域组成。在一个具体实施方案中,单结构域片段是骆驼化的(参见例如, riechmann,1999,journal ofimmunological methods 231:25
–
38)。
[0040]
本发明的抗冠状病毒rbd的抗体包括衍生化抗体。例如,衍生化抗体通常 通过糖基化、乙酰化、聚乙二醇化、磷酸化、酰胺化、通过已知保护/封闭基团 的衍生化、蛋白酶解切割、与细胞配体或其它蛋白质的连接来修饰。可以通过 已知技术进行众多化学修饰中的任一种,所述技术包括但不限于特定的化学切 割、乙酰化、甲酰化、衣霉素的代谢合成等。另外,衍生物可以含有一种或多 种非天然氨基酸,例如,使用ambrx技术(参见例如,wolfson,2006,chem.biol. 13(10):1011-2)。
[0041]“人源抗体”包括具有人免疫球蛋白的氨基酸序列的抗体,并且包括从人 免疫球蛋白文库或动物中分离的抗体,所述动物对于一种或多种人免疫球蛋白 是转基因的,并且不表达内源免疫球蛋白。人抗体可以通过本领域已知的各种 方法制备,所述方法包括使用衍生自人免疫球蛋白序列的抗体文库的噬菌体展 示方法。参见美国专利号4,444,887和4,
716,111;以及pct公开wo 98/46645; wo 98/50433;wo 98/24893;wo 98/16654;wo 96/34096;wo96/33735;和 wo 91/10741。还可以使用不能表达功能性内源免疫球蛋白,但可以表达人免 疫球蛋白基因的转基因小鼠来产生人抗体。参见例如,pct公开wo 98/24893; wo 92/01047;wo 96/34096;wo 96/33735;美国专利号5,413,923;5,625,126; 5,633,425;5,569,825;5,661,016;5,545,806;5,814,318;5,885,793;5,916,771; 和5,939,598。另外,使用与上述类似的技术,公司例如lakepharma,inc. (belmont,ca)或creative biolabs(shirley,ny)可以从事于提供针对所选 抗原的人抗体。可以使用被称为“引导选择”的技术生成识别所选表位的全人 抗体。在该方法中,选择的非人单克隆抗体,例如小鼠抗体,用于引导识别相 同表位的完全人抗体的选择(参见,jespers等人,1988,biotechnology12:899-903)。
[0042]
术语“识别抗原的抗体”以及“对抗原特异的抗体”在本文中与术语“特异结合 抗原的抗体”交替使用。
[0043]
术语“高亲和性”对于igg抗体而言,是指对于抗原的kd为1.0x 10-6
m以下, 优选5.0x 10-8
m以下,更优选1.0x 10-8
m以下、5.0x 10-9
m以下,更优选1.0x 10-9
m 以下。对于其他抗体亚型,“高亲和性”结合可能会变化。例如,igm亚型的“高 亲和性”结合是指kd为10-6
m以下,优选10-7
m以下,更优选10-8
m以下。
[0044]
术语“kassoc”或“ka”是指特定抗体-抗原相互作用的结合速率,而术语
ꢀ“
kdis”或“kd”是指特定抗体-抗原相互作用的离解速率。术语“kd”是指解离常 数,由kd与ka比(kd/ka)得到,并以摩尔浓度(m)表示。抗体的kd值可以通 过领域内已知的方法确定。优选的确定抗体kd的方式是使用表面等离子共振 仪(spr)测得的,优选使用生物传感系统例如biacoretm系统测得。
[0045]
术语“ec50”,又叫半最大效应浓度,是指引起50%最大效应的抗体浓度。
[0046]
与现有技术相比,本发明的技术方案具有以下优点:
[0047]
第一,本发明提供的sars-cov-2 s蛋白特异性抗体或其片段,氨基酸序 列结构明确、对冠状病毒rbd亲和力高、抑制或阻断冠状病毒rbd与宿主细 胞结合的效果确切,用作药物时具有较低的异源性和较高的临床应用潜力。
[0048]
第二,本发明提供的sars-cov-2 s蛋白特异性抗体或其片段能够特异性结 合sars-cov-2,而不结合sars-cov、mers-cov-2。特别是,用于治疗 sars-cov-2感染时不产生可检测到的抗体依赖的增强效应(ade),安全性优于 其它抗sars-cov-2 s蛋白特异性抗体。
[0049]
第三,本发明提供的sars-cov-2 s蛋白特异性抗体或其片段是从大量候选 人源抗体中分离获得的,能够与宿主细胞aceii竞争结合sars-cov-2,从而 中和sars-cov-2对宿主细胞的侵染。根据分子机理、封闭阻断实验、中和实 验的效果能够预期本发明提供的sars-cov-2中和性单抗或其片段可通过降低 sars-cov-2的病毒载量,发挥治疗covid-19的作用。
附图说明
[0050]
通过阅读下文优选实施方式的详细描述,各种其他的优点和益处对于本领 域普通技术人员将变得清楚明了。附图仅用于示出优选实施方式的目的,而并 不认为是对本发
明的限制。而且在整个附图中,用相同的参考符号表示相同的 部件。在附图中:
[0051]
图1:sars-cov-2 s1蛋白rbd与his的融合表达。
[0052]
图2:sars-cov-2 s1蛋白rbd与mfc的融合表达。
[0053]
图3:sars-cov-2 s1蛋白与mfc的融合表达。
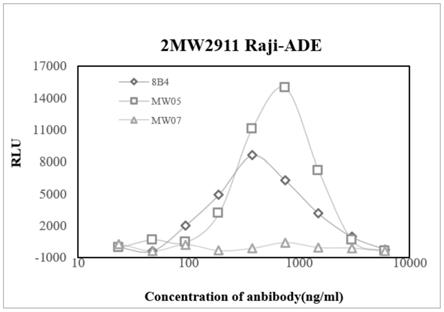
[0054]
图4:人ace2与人fc的融合表达。
[0055]
图5:mw07与重组蛋白sars-cov2-s1rbd-his的亲和力分析。
[0056]
图6:mw07与冠状病毒s蛋白的交叉反应性分析。
[0057]
图7:mw07对s1rbd-mfc与aceii-hfc结合的阻断作用曲线图。
[0058]
图8:mw07对s1rbd-his与aceii-his结合的阻断作用。
[0059]
图9:mw07对假病毒感染huh7细胞的体外中和活性。
[0060]
图10:wtlgg抗体介导假病毒感染raji细胞的ade作用观察。
具体实施方式
[0061]
下面将参照附图更详细地描述本公开的示例性实施方式。虽然附图中显示 了本公开的示例性实施方式,然而应当理解,可以以各种形式实现本公开而不 应被这里阐述的实施方式所限制。相反,提供这些实施方式是为了能够更透彻 地理解本公开,并且能够将本公开的范围完整的传达给本领域的技术人员。
[0062]
实施例1:sars-cov-2抗原及宿主受体的重组表达
[0063]
将全合成的基因s1rbd(accession:qhd43416.1,319-541aa),通过酶切 方法分别克隆入c端带有his标签或mfc标签的真核瞬时表达载体中,将获得 的表达质粒,转入大肠杆菌扩增,分离获得s1rbd-his和s1rbd-mfc表达质粒, 并根据转染试剂293fectin(cat:12347019,gibco)的操作说明,将质粒转入 hek293细胞中重组表达。细胞转染后5-6天,取培养上清,s1rbd-mfc利用proa 亲和层析柱对表达上清进行纯化,获得s1rbd-mfc蛋白。s1rbd-his利用histraphp柱亲和层析柱对表达上清进行纯化,获得s1rbd-his蛋白。并将获得的重组 蛋白通过sds-page检测纯度(图1-2)。s1rbd-his的编码核酸序列如seq id no:1 所示,氨基酸序列如seq id no:2所示;s1rbd-mfc的编码核酸序列如seq id no:3 所示,氨基酸序列如seq id no:4所示。
[0064]
通过pcr的方法从购买的全长sars-cov-2表达载体(cat:vg40589-ut,北 京义翘神州)中克隆出s1基因(accession:qhd43416.1,1-685aa),并通过酶 切方法分别克隆入c端带有mfc标签的真核瞬时表达载体中,将获得的表达质 粒,转入大肠杆菌扩增,分离获得s1-mfc表达质粒,并根据转染试剂293fectin (cat:12347019,gibco)的操作说明,将质粒转入hek293细胞中重组表达。细 胞转染后5-6天,取培养上清,s1-mfc利用proa亲和层析柱对表达上清进行纯 化,获得s1-mfc蛋白。并将获得的重组蛋白通过sds-page检测纯度(图3)。 s1-mfc的编码核酸序列如seq id no:5所示,氨基酸序列如seq id no:6所示。
[0065]
通过pcr的方法从购买的全长人aceii表达载体(cat:hg10108-acr,北京 义翘神州)中克隆出aceii胞外区基因aceii(1-615)(accession:np_068576.1,1-615aa),并通过酶切方法分别克隆入c端带有hfc标签的真核瞬时表达载体 中,将获得的表达质粒,转入大肠杆菌扩增,分离获得,aceii(1-615)-hfc表 达质粒,并根据转染试剂293fectin(cat:12347019,gibco)的操作说明,将质 粒转入hek293细胞中重组表达。细胞转染后5-6天,取
培养上清,利用proa 亲和层析柱对表达上清进行纯化,获得aceii(1-615)-hfc蛋白,并将获得的重组 蛋白通过sds-page检测纯度(图4)。aceii(1-615)-hfc的编码核酸序列如seq idno:7所示,氨基酸序列如seq id no:8所示。
[0066]
实施例2:b细胞筛选获得抗新冠状病毒s1rbd特异性抗体
[0067]
利用fitc-s1rbd-hfc为抗原,对新型冠状病毒感染康复患者的特异性记忆 b细胞进行分选。单细胞pcr技术(方法和引物参考文献new biotechnology,2010. volume 27,number 2,p110-117以及human monoclonal antibodies书中第114 至117页)扩增抗体轻重链基因,并进行测序分析。将测序正确的抗体轻重链 可变区基因合成后克隆入含有轻链恒定区的瞬时表达载体pkn019和含有重链 恒定区igg1基因的瞬时表达载体pkn041,利用hek293系统进行瞬时表达纯化 获得重组抗体mw07。
[0068]
单细胞pcr扩增抗体轻重链基因的方法如下:
[0069]
首先,采用rna磁珠(南京诺唯赞)提取单b细胞的rna,反转录成cdna。
[0070]
1.每孔分装5μl catch buffer b(tcl 1%β-me),分选单个记忆性b细胞。
[0071]
2.贴膜,2000rpm离心1min。
[0072]
3.每孔加入10μl h2o和33μl beads,吹吸混匀,室温作用10min。
[0073]
4.置磁力架,室温5min,弃上清。
[0074]
5.用200μl无核酸酶水新鲜配置的80%乙醇漂洗磁珠,室温30s,弃上 清。
[0075]
6.重复漂洗一次,弃上清,风干3min。
[0076]
7.移下磁力架,每孔加12μl mix 1,吹吸5次,室温作用5min。
[0077]
8.置磁力架,室温2min,转移10μl至新板,300g离心30s,运行程序 1。
[0078]
9.每孔加10μl mix 2,混匀、离心,运行程序2。
[0079]
10.合成好的cdna尽快进行pcr。
[0080]
mix 1:310μl h2o 50μl dntp 20μl random 6 20μl oligo_dt
[0081]
mix 2:170μl h2o 160μl buffer 40μl dtt 20μl rnase i 10μl rtase iv (cat:en0601 and 18090010,thermofisher)
[0082]
程序1:65℃ 5min
→
4℃ ∞
[0083]
程序2:23℃ 10min
→
50℃ 30min
→
80℃ 10min
→
4℃ ∞
[0084]
然而,采用两步pcr扩增抗体重链以及轻链(kappa)可变区基因。引物序 列源自于human monoclonal antibodies书中第114至117页。
[0085]
第一轮pcr(ig-vh1、ig-vk1),反应体系(20μl):
[0086][0087]
运行程序:
[0088]
94℃ 5min
→
(94℃ 30s
→
51℃ 30s
→
72℃ 55s)
×
15cycles
[0089]
→
(94℃ 30s
→
56℃ 30s
→
72℃ 55s)
×
30cycles
[0090]
→
72℃ 8min
[0091]
→
4℃ ∞
[0092]
第二轮pcr(ig-vh2、ig-vk2),反应体系(20μl):
[0093][0094]
运行程序:
[0095]
94℃ 5min
→
(94℃ 30s
→
57℃ 30s
→
72℃ 45s)
×
50cycles
[0096]
→
72℃ 10min
[0097]
→
4℃ ∞
[0098]
琼脂糖凝胶电泳分离纯化pcr产物并进行抗体轻、重链可变区测序。
[0099]
mw07可变区氨基酸序列如下所示。
[0100]
>mw07-vl(seq id no:9,lcdr1-3分别为seq id no:11-13)
[0101]
diqmtqspsslsasvgdrvtitcrasqgisnslawyqqkpgkapklllyaastlesgvpsrfsgsgsg tdftltisslqpedfatyycqqfystprtfgqgtkveik
[0102]
>mw07-vh(seq id no:10,hcdr1-3分别为seq id no:14-16)
[0103]
evqlvesggglvqpggslrlscaasgftfssywmswvrqapgkglewvanikqdasekyyldslkgrf tisrdnaknslylqmnslraedtavyycardlgilwfgdypwgqgtlvtvss
[0104]
实施例3.mw07与s1rbd亲和力
[0105]
应用fortebio蛋白相互作用系统测定抗体与s1-rbd蛋白抗原结合的亲和 力。主要步骤如下:
[0106]
利用fortebio公司的octet qke system,采用抗人抗体fc段的捕获抗体 (ahc)生物探针捕获不同浓度的测定抗体与单价s1rbd的结合和解离变化。 测定时将4种不同浓度的mw07(45nm、30nm、15nm、7.5nm)流经ahc探针 (cat:18-5060,pall)表面,时间为120s。不同浓度稀释的s1rbd-his作为流 动相。结合时间为300s,解离时间为300s。实验完毕,扣除空白对照响应值, 用软件进行1∶1langmuir结合模式拟合,计算抗原抗体结合的动力学常数。 结果如图5所示。拟合mw07与sars-cov-2 s1rbd的亲和力常数,kd=0.424nm, 高于mw01-mw06(另案申请)的亲和力。
[0107]
实施例4.mw07的特异性和交叉反应
[0108]
将sars-cov-2 s1rbd-his重组蛋白(科诺信诚科技有限公司表达, lot:20200213a)、sars-cov-2 s1-his重组蛋白(科诺信诚科技有限公司表达, lot:20200221h)、重组蛋白sars s1-his:(北京义翘神州,cat:40150-v08b1)、 重组蛋白mers-cov s1-his(北京义翘神州,cat:40069-v08h)以及阴性对照 nc-his以浓度1μg/ml;4℃包被过夜,用5%bsa于37℃恒温培养箱封闭60 min。加入待测抗体(起始浓度为10μg/ml,3倍连续稀释,12个梯度),37℃ 恒温培养箱反应60min后。pbst洗板4次;然后加入1∶5000稀释的 hrp-anti-human fc(cat:109-035-098,jackson immuno research),反应45min, 加入tmb(cat:me142,北京泰天河生物)底物显色15min,2m hcl终止后读 板。以630nm为参比波
长,读取并记录波长450nm下孔板的吸光度值 od450nm-630nm。
[0109]
结果如图6所示。mw07仅特异性结合新冠状病毒sars-cov-2的s蛋白(s1rbd 和s1),而不结合sars s1-his、mers-cov s1-his、以及阴性对照nc-his。
[0110]
实施例3.mw07对s1rbd/aceii的阻断活性
[0111]
3.1elsia分析抗体对aceii-hfc与s1rbd-mfc结合的阻断作用
[0112]
将human aceii-hfc(1-615aa)重组蛋白,浓度0.75μg/ml,100μl/孔,4℃ 包被过夜,用5%bsa于37℃恒温培养箱封闭120min后,pbst洗板4次。将 待测抗体mw01和mw07(起始浓度为40μg/ml,1.5倍连续稀释,12个梯度) 和与s1-rbd-mfc 70ng/ml,各取100ul等体积混匀,37℃放置50min后,每个 样本取两个100μl平行加入到ace2-hfc包被孔;37℃恒温培养箱反应60min 后,pbst洗板4次;然后加入1∶5000稀释的hrp-anti-mouse igg (cat:115-035-071,jackson immuno research),反应45min,pbst洗板4次; 加入tmb(cat:me142,北京泰天河生物)底物显色15min,2m hcl终止后读 板。读取并记录波长450nm。
[0113]
结果如图7所示,抗体mw07能够有效阻断s1rbd与aceii的结合,阻断活 性高于抗体mw01。
[0114]
3.2fortebio竞争结合实验分析抗体对aceii-his与s1rbd-his结合的阻断作用
[0115]
采用ahc生物探针捕获待分析抗体mw01、mw07、cr3022 (us2010172917a1公开的一株抗sars-cov rbd的单抗,与新冠s1rbd有交 叉结合),pbs平衡后与100nm的s1rbd-his作为流动性,充分结合240s,进一 步以aceii-his作为第二结合相,充分结合300s后,转入pbs中进行解离。
[0116]
结果如图8所示,抗体mw07能够有效阻断s1rbd与aceii的结合。
[0117]
实施例4.mw07对新冠状病毒假病毒感染huh7细胞的中和活性
[0118]
采用中检院的新冠假病毒感染huh7细胞中和活性实验观察。将不同浓度的 待评估抗体与750tcid50/孔的假病毒颗粒(转染荧光素酶报告基因)在37℃进 行中和反应后,分别接种2x104/孔huh7细胞,置于37℃的co2培养箱内培养 20-28h。20-28h后取出细胞板每孔加入100μl荧光素酶检测试剂,避光反应2min, 荧光检测仪读数,计算中和抑制率,并根据中和抑制率结果,利用reed-muench 法计算ic50。
[0119]
结果如图9所示,mw07能够剂量依赖地抑制假病毒颗粒进入宿主细胞,经 过reed-muench法计算,ic50值为62ng/ml,远高于mw01(ic50,281ng/ml)的 中和活性。
[0120]
实施例5.mw07对sars-cov-2感染raji细胞的ade作用
[0121]
采用中检院的新冠假病毒颗粒感染raji细胞进行抗体的ade检测。将不同 浓度的待评估新冠抗体与750 tcid
50
/孔的假病毒颗粒(转染荧光素酶报告基 因)在37℃进行中和反应后,分别接种1x105/孔raji细胞,置于37℃的co2培养 箱内培养20-28h。20-28h后取出细胞板每孔加入100μl荧光素酶检测试剂,避 光反应2min,荧光检测仪读数,根据荧光信号强度评价ade的强弱。
[0122]
结果如图10所示,wtlgg1形式的mw07在10-10000ng/ml的浓度范围内均 未观察到ade现象,而wtlgg1形式的mw05和mw01(8b4)两个抗体在一定的 浓度范围内(100-1500ng/ml)产生了较强的ade现象。
[0123]
注:所述抗体8b4(mw01)参见第cn202010178099.x号发明专利申请。 所述抗体mw05参见第cn202010298015.6号发明专利申请。
[0124]
本发明中涉及的抗原分子氨基酸和核苷酸序列如下:
[0125]
>s1 rbd-his
[0126]
核苷酸序列seq id no:1(划线部分为标签部分)
[0127]
atgcctctgctgctgctgctgcctctgctgtgggctggagccctggctcgggtgcag cccaccgagtccatcgtgcggttccccaacatcaccaacctgtgccccttcggcgaggtgt tcaacgccacccggttcgcctccgtgtacgcctggaaccggaagcggatctccaactgcgt ggccgactactccgtgctgtacaactccgcctccttctccaccttcaagtgctacggcgtgt ctcccaccaagctgaacgacctgtgcttcaccaacgtgtacgccgactccttcgtgatcag aggcgacgaggtgcggcagatcgctcctggccagaccggcaagatcgccgactacaacta caagctgcccgacgacttcaccggctgcgtgatcgcctggaactccaacaacctggactc caaggtgggaggcaactacaactacctgtaccggctgttccggaagtccaacctgaagcc cttcgagcgggacatctccaccgagatctaccaggctggctccacaccctgcaacggcgt ggagggcttcaactgctacttccctctgcagtcctacggcttccagcccaccaacggcgtg ggctaccagccctaccgggtggtggtgctgtccttcgagctgctgcacgctcctgccaccg tgtgcggacccaagaagtccaccaacctggtgaagaacaagtgcgtgaacttcgctagcg gatcccatcaccatcaccatcac
[0128]
>s1 rbd-his
[0129]
氨基酸序列seq id no:2(划线部分为标签部分)
[0130]
mplllllpllwagalarvqptesivrfpnitnlcpfgevfnatrfasvyawnrkrisncv adysvlynsasfstfkcygvsptklndlcftnvyadsfvirgdevrqiapgqtgkiadynyklpd dftgcviawnsnnldskvggnynylyrlfrksnlkpferdisteiyqagstpcngvegfncyf plqsygfqptngvgyqpyrvvvlsfellhapatvcgpkkstnlvknkcvnfasgshhhhhh
[0131]
>s1 rbd-mfc
[0132]
核苷酸序列seq id no:3(划线部分为标签部分)
[0133]
atgcctctgctgctgctgctgcctctgctgtgggctggagccctggctcgggtgcag cccaccgagtccatcgtgcggttccccaacatcaccaacctgtgccccttcggcgaggtgt tcaacgccacccggttcgcctccgtgtacgcctggaaccggaagcggatctccaactgcgt ggccgactactccgtgctgtacaactccgcctccttctccaccttcaagtgctacggcgtgt ctcccaccaagctgaacgacctgtgcttcaccaacgtgtacgccgactccttcgtgatcag aggcgacgaggtgcggcagatcgctcctggccagaccggcaagatcgccgactacaacta caagctgcccgacgacttcaccggctgcgtgatcgcctggaactccaacaacctggactc caaggtgggaggcaactacaactacctgtaccggctgttccggaagtccaacctgaagcc cttcgagcgggacatctccaccgagatctaccaggctggctccacaccctgcaacggcgt ggagggcttcaactgctacttccctctgcagtcctacggcttccagcccaccaacggcgtg ggctaccagccctaccgggtggtggtgctgtccttcgagctgctgcacgctcctgccaccg tgtgcggacccaagaagtccaccaacctggtgaagaacaagtgcgtgaacttcgctagcg tgcccagggattgtggttgtaagccttgcatatgtacagtcccagaagtatcatctgtcttc atcttccccccaaagcccaaggatgtgctcaccattactctgactcctaaggtcacgtgtgt tgtggtagacatcagcaaggatgatcccgaggtccagttcagctggtttgtagatgatgtg gaggtgcacacagctcagacgcaaccccgggaggagcagttcaacagcactttccgctc agtcagtgaacttcccatcatgcaccaggactggctcaatggcaaggagttcaaatgcag ggtcaacagtgcagctttccctgcccccatcgagaaaaccatctccaaaaccaaaggcag accgaaggctccacaggtgtacaccattccacctcccaaggagcagatggccaaggataa agtcagtctgacctgcatgataacagacttcttccctgaagacattactgtggagtggcag tggaatgggcagccagcggagaactacaagaacactcagcccatcatggacacag
ctggctgtctgattggagcagagcatgtgaacaactcctatgagtgtgacatcccaattgg agcaggcatctgtgcctcctaccagacccagaccaacagcccaaggagggcaagggcta gcgtgcccagggattgtggttgtaagccttgcatatgtacagtcccagaagtatcatctgtc ttcatcttccccccaaagcccaaggatgtgctcaccattactctgactcctaaggtcacgtg tgttgtggtagacatcagcaaggatgatcccgaggtccagttcagctggtttgtagatgat gtggaggtgcacacagctcagacgcaaccccgggaggagcagttcaacagcactttccg ctcagtcagtgaacttcccatcatgcaccaggactggctcaatggcaaggagttcaaatgc agggtcaacagtgcagctttccctgcccccatcgagaaaaccatctccaaaaccaaaggc agaccgaaggctccacaggtgtacaccattccacctcccaaggagcagatggccaaggat aaagtcagtctgacctgcatgataacagacttcttccctgaagacattactgtggagtggc agtggaatgggcagccagcggagaactacaagaacactcagcccatcatggacacagat ggctcttacttcgtctacagcaagctcaatgtgcagaagagcaactgggaggcaggaaat actttcacctgctctgtgttacatgagggcctgcacaaccaccatactgagaagagcctct cccactctcctggtaaa
[0140]
>s1-mfc
[0141]
氨基酸序列seq id no:6(划线部分为标签部分)
[0142]
mfvflvllplvssqcvnlttrtqlppaytnsftrgvyypdkvfrssvlhstqdlflpffsn vtwfhaihvsgtngtkrfdnpvlpfndgvyfasteksniirgwifgttldsktqsllivnnat nvvikvcefqfcndpflgvyyhknnkswmesefrvyssannctfeyvsqpflmdlegkqgn fknlrefvfknidgyfkiyskhtpinlvrdlpqgfsaleplvdlpiginitrfqtllalhrsyltpg dsssgwtagaaayyvgylqprtfllkynengtitdavdcaldplsetkctlksftvekgiyqts nfrvqptesivrfpnitnlcpfgevfnatrfasvyawnrkrisncvadysvlynsasfstfkcyg vsptklndlcftnvyadsfvirgdevrqiapgqtgkiadynyklpddftgcviawnsnnldsk vggnynylyrlfrksnlkpferdisteiyqagstpcngvegfncyfplqsygfqptngvgyqp yrvvvlsfellhapatvcgpkkstnlvknkcvnfnfngltgtgvltesnkkflpfqqfgrdiad ttdavrdpqtleilditpcsfggvsvitpgtntsnqvavlyqdvnctevpvaihadqltptwr vystgsnvfqtragcligaehvnnsyecdipigagicasyqtqtnsprrarasvprdcgckpci ctvpevssvfifppkpkdvltitltpkvtcvvvdiskddpevqfswfvddvevhtaqtqpreeq fnstfrsvselpimhqdwlngkefkcrvnsaafpapiektisktkgrpkapqvytipppkeqm akdkvsltcmitdffpeditvewqwngqpaenykntqpimdtdgsyfvysklnvqksnwe agntftcsvlheglhnhhtekslshspgk
[0143]
>ace2 1-615-hfc
[0144]
核苷酸序列seq id no:7(划线部分为标签部分)
[0145]
atgtcaagctcttcctggctccttctcagccttgttgctgtaactgctgctcagtccac cattgaggaacaggccaagacatttttggacaagtttaaccacgaagccgaagacctgtt ctatcaaagttcacttgcttcttggaattataacaccaatattactgaagagaatgtccaaaa catgaataatgctggggacaaatggtctgcctttttaaaggaacagtccacacttgcccaa atgtatccactacaagaaattcagaatctcacagtcaagcttcagctgcaggctcttcagca aaatgggtcttcagtgctctcagaagacaagagcaaacggttgaacacaattctaaataca atgagcaccatctacagtactggaaaagtttgtaacccagataatccacaagaatgcttatt acttgaaccaggtttgaatgaaataatggcaaacagtttagactacaatgagaggctctgg gcttgggaaagctggagatctgaggtcggcaagcagctgaggccattatatgaagagtat gtggtcttgaaaaatgagatggcaagagcaaatcattatgaggactatggggattattgga gaggagactatgaagtaaatggggtagatggctatgactacagccgcggccagttgattg aagatgtggaacatacctttgaagagattaaaccattatatgaacatcttcatgcctatgtga gggcaaagttgatgaatgcctatccttcctatatcagtccaattggatgcctccctgctcatt tgcttggtgatatgtgggg
tagattttggacaaatctgtactctttgacagttccctttgga cagaaaccaaacatagatgttactgatgcaatggtggaccaggcctgggatgcacagaga atattcaaggaggccgagaagttctttgtatctgttggtcttcctaatatgactcaaggatt ctgggaaaattccatgctaacggacccaggaaatgttcagaaagcagtctgccatcccaca gcttgggacctggggaagggcgacttcaggatccttatgtgcacaaaggtgacaatggac gacttcctgacagctcatcatgagatggggcatatccagtatgatatggcatatgctgcaca accttttctgctaagaaatggagctaatgaaggattccatgaagctgttggggaaatcatg tcactttctgcagccacacctaagcatttaaaatccattggtcttctgtcacccgattttcaa gaagacaatgaaacagaaataaacttcctgctcaaacaagcactcacgattgttgggactc tgccatttacttacatgttagagaagtggaggtggatggtctttaaaggggaaattcccaa agaccagtggatgaaaaagtggtgggagatgaagcgagagatagttggggtggtggaa cctgtgccccatgatgaaacatactgtgaccccgcatctctgttccatgtttctaatgattac tcattcattcgatattacacaaggaccctttaccaattccagtttcaagaagcactttgtcaa gcagctaaacatgaaggccctctgcacaaatgtgacatctcaaactctacagaagctggac agaaactgttcaatatgctgaggcttggaaaatcagaaccctggaccctagcattggaaaa tgttgtaggagcaaagaacatgaatgtaaggccactgctcaactactttgagcccttattta cctggctgaaagaccagaacaagaactcttttgtgggatggagtaccgactggagtccat atgcagacgctagcgagcccaaatcttgtgacaaaactcacacatgcccaccgtgcccagc acctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctc atgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccct gaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagcc gcgggaggagcagtacaacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcacca ggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccc catcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccct gcctccatctcgggatgagctgaccaagaaccaggtcagcctgacctgcctggtcaaagg cttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaacta caagaccacgcctcccgtgctggactccgacggctccttcttcctctatagcaagctcacc gtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggct ctgcacaaccactacacgcagaagagcctctccctgtctccgggtaaa
[0146]
>ace2 1-615-hfc氨基酸序列seq id no:8(划线部分为标签部分)
[0147]
msssswlllslvavtaaqstieeqaktfldkfnheaedlfyqsslaswnyntniteenvq nmnnagdkwsaflkeqstlaqmyplqeiqnltvklqlqalqqngssvlsedkskrlntiln tmstiystgkvcnpdnpqeclllepglneimansldynerlwaweswrsevgkqlrplyeey vvlknemaranhyedygdywrgdyevngvdgydysrgqliedvehtfeeikplyehlhayv raklmnaypsyispigclpahllgdmwgrfwtnlysltvpfgqkpnidvtdamvdqawda qrifkeaekffvsvglpnmtqgfwensmltdpgnvqkavchptawdlgkgdfrilmctkv tmddfltahhemghiqydmayaaqpfllrnganegfheavgeimslsaatpasepkscdkt htcppcpapellggpsvflfppkpkdtlmisrtpevtcvvvdvshedpevkfnwyvdgvevh naktkpreeqynstyrvvsvltvlhqdwlngkeykckvsnkalpapiektiskakgqprepqv ytlppsrdeltknqvsltclvkgfypsdiavewesngqpennykttppvldsdgsfflyskltvd ksrwqqgnvfscsvmhealhnhytqkslslspgk
[0148]
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局 限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易 想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护 范围应以所述权利要求的保护范围为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。