ice[j].journal ofclimate,1999,12(6):1814
‑
1829.
[0009]
[4]markus t,cavalieri d j,gasiewski a j,et al.microwave signatures ofsnow on sea ice:observations[j].ieee transactions on geoscience and remote sensing,2006,44(11):3081
‑
3090.
技术实现要素:
[0010]
针对目前北极积雪深度反演的以下几个问题:在积雪深度反演之前需要提前知道一年冰和多年冰的范围,这两者在边界确定上依然有很大的不确定性,这会导致积雪深度反演的误差。在预处理阶段需要提前海冰密集度和开放水的典型亮温对亮温进行校正以消除开放水对亮温的影响,因此以往的算法中海冰密集度和开放水典型亮温的选取也是影响算法精度的重要组成部分。在积雪深度反演阶段,需要对亮温和积雪深度拟合两个回归方程以分别反演多年冰和一年冰上的积雪深度,且北极积雪深度与亮温之间主要表现为非线性关系。
[0011]
本发明提出一种机器学习方法以学习亮温和积雪深度之间的非线性关系。这种机器学习方法不需要先确定一年冰和多年冰,且不需要利用海冰密集度和开放水的典型亮温对亮温进行校正,且不需要对多年冰和一年冰上的积雪深度分别建模。
[0012]
本发明所要解决的问题是提供一种基于机器学习的北极积雪深度方法,其既不需要额外辅助参数,又高于其他算法的精度。
[0013]
步骤1:获取冰桥行动(operation ice bridge,oib)北极积雪深度即oib积雪深度数据,oib积雪深度数据记录有北极上测量的经纬度、时间和相应的积雪深度,oib积雪深度数据和北极积雪深度有很好的一致性因此适合用于数据建模。amsr2 l1r是amsr2轨道亮温数据,每个轨道扫描轨道为一个hdf5文件包括不同通道的亮温,并记录在每个轨道的扫描时间。amsr2 l1r分有升轨和降轨数据。
[0014]
步骤2:根据oib积雪深度数据中的经纬度和amsr2 l1r亮温的经纬度数据,对两数据进行匹配,两数据的经纬度之间最短距离即为匹配点。每个oib积雪深度分别匹配到升轨和降轨的亮温数据,根据oib积雪深度的记录时间和amsr2 l1r中记录的时间选择时间最接近的亮温即为最终匹配点。
[0015]
步骤3:低频通道的垂直亮温梯度比对多年冰和一年冰上的积雪深度较为敏感,计算最终匹配点的垂直亮温的梯度比(gradient ratio,gr),分别为gr(10v/7v)、gr(19v/7v)、gr(19v/10v)、gr(37v/7v)、gr(37v/10v)、gr(37v/19v)。这里不再使用海冰密集度和开放水典型亮温对各个通道的亮温进行校正,因此gr的公式为
[0016][0017]
其中,tb
mv
为m通道的垂直亮温,tb
nv
为n通道的垂直亮温。
[0018]
步骤4:构建积雪深度的训练样本集和测试样本集,按照步骤3计算的亮温梯度比作为输入自变量,相对应的积雪深度作为输出应变量。oib积雪不仅在分布在多年冰上也分布在一年冰上。在训练样本和测试样本中不仅要包含多年冰积雪深度而且要包含一年冰积雪深度,将前70%的输入自变量以及对应的输出应变量划分为积雪深度训练样本集,剩余的后30%的输入自变量以及对应的输出应变量作为积雪深度测试样本集。
[0019]
步骤5:建立积雪深度机器学习来映射亮温梯度比和oib积雪深度之间的非线性关系。采用在步骤4中建立的积雪深度训练样本集分别训练多层感知器和随机森林,以比较哪种机器学习模型更适合积雪深度反演。多层感知器模型包括数据输入层,3个隐藏层和一个输出层。随机森林模型包括多个决策树每个决策树包括多个叶子。对于关于积雪深度的多层感知器训练算法需要选择为levenberg
‑
marquardt算法。训练终止目标(即收敛阈值)设置为0.0001。最大迭代学习次数设置为2000。损失函数选择为平均绝对误差。对于关于积雪深度的随机森林在训练时,可以绘制误差曲线不断调整决策树和叶子的大小。
[0020]
在设置参数中,可以设置如下参数:关于积雪深度的多层感知器的学习速率设置为0.05,每层神经元个数分别设置为25、20和15。对于积雪深度的随机森林选择200棵决策树和5个叶子。
[0021]
步骤6:挑选模拟积雪深度较好的机器学习模型,随机森林和多层感知器都对初始输入的权值敏感,不同随机输入的初始权值会带来对模拟的积雪深度产生不同的影响。不断重复训练积雪深度多层感知器和随机森林以选择最优模型,使用均方根误差(rmse)、最优拟合度(r2)和偏差(bias)来评价模拟的积雪深度和实际的积雪深度之间的误差以挑选模拟积雪深度较好的模型,公式如下:
[0022][0023][0024][0025]
f为预测的积雪深度,y为oib积雪深度,n为积雪深度观测点的个数。
[0026]
两种关于积雪深度的机器学习模型分别训练200次并保存每次的网络结构和记录均方根误差、最优拟合度以及偏差,这样就形成了200个积雪深度多层感知器和200个随机森林。首先利用最优拟合度对积雪深度模拟结果进行评价,因为最优拟合度越大,均方根误差和偏差就越小。分别在200个积雪深度多层感知器和随机森林中挑选最优拟合度最大的多层感知器和随机森林网络。然后对挑选出来的多层感知器和最优随机森林进行以上3个评价参数的对比,找出模拟结果最好的积雪深度模型。
[0027]
本发明所要解决的技术问题是提供一种基于机器学习的北极积雪深度自动化反演。其既解决了传统线性回归方程中无法反演复杂的非线性关系而导致模型不确定性,具有能学习复杂非线性关系降低积雪深度不确定性的特点。也解决了传统方法中需要额外确定多年冰、一年冰以及海冰密集度等辅助参数等需要复杂的辅助输入数据等问题,具有输入数据简单易实现的特点。
附图说明
[0028]
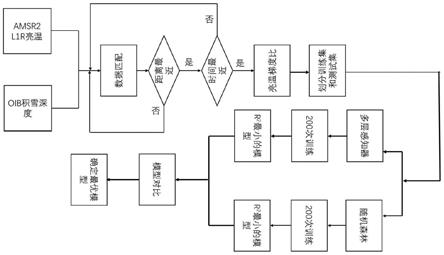
图1:本发明方法整体的技术实施路线流程图。
[0029]
图2中,(a)训练样本分布和(b)测试样本分布。无论在训练样本还是测试样本中都包含了一年冰和多年冰上的积雪深度。
[0030]
图3中,(a)200个多层感知器序列最优拟合度分布,(b)200个随机森林序列最优拟合度分布。
[0031]
图4:(a)在测试集中最优多层感知器模拟的积雪深度和oib积雪深度比对,(b)在测试集中最优随机森林模拟的积雪深度与oib积雪深度对比。
具体实施方式
[0032]
下面结合附图和具体实施方式对本发明做更进一步的说明。
[0033]
图1为本发明的技术路线流程图,本发明利用在2013到2015年冰桥行动期间采样机载雪雷达收集的北极多年冰和一年冰上的积雪深度以及amsr2 l1r轨道亮温使用两个机器学习模型反演北极积雪深度。具体步骤如下:
[0034]
收集2013年到2015年冰桥行动期(oib)间的北极积雪深度,oib数据同时也记录也数据采集时间和相对应的经纬度。收集同时期的amsr2 l1r轨道亮温,该轨道亮温是一个hdf5文件,里面存储着升轨和降轨亮温,以及相对应的经纬度。此外也记录了轨道扫描时间。美国宇航局(nasa)在2009年到2015年春季利用在飞机上搭载的机载雪雷达测量了北极多年冰和一年冰上的积雪深度。获取2013年到2015年春季与oib数据以及同时期的amsr2被动微波辐射计l1r亮温数据。
[0035]
首先利用matlab软件中distance函数,根据每个oib积雪深度点记录的经纬度分别计算与amsr2 l1r升轨和降轨亮温之间的距离,然后找出分别在升轨和降轨中找出距离最近的点即为匹配点。然后找出在匹配的点中,升轨亮温和降轨亮温所记录的时间与相对应的oib积雪深度时间最接近的点,即为最终匹配点。
[0036]
分别计算匹配点的垂直亮温梯度比(gradient ratio,gr),分别为gr(10v/7v)、gr(19v/7v)、gr(19v/10v)、gr(37v/7v)、gr(37v/10v)、gr(37v/19v)。gr的公式为
[0037]
gr的公式为
[0038][0039]
其中tb
mv
为m通道的垂直亮温,tb
nv
为n通道的垂直亮温。在这一步中不需要获取海冰密集度以及相应垂直亮温的特征开放水亮温对gr进行校正。
[0040]
构建数据训练样本集和测试样本集,按照(3)计算的梯度比作为输入自变量,相对应的积雪深度作为输出应变量。然后将前70%的输入自变量以及对应的输出应变量划分为训练样本,剩余的后30%的输入自变量以及对应的输出应变量作为测试样本集。最终划分结果如图2所示,可以看到训练样本和测试样本中都包含了一年冰和多年冰区域的积雪深度。
[0041]
使用matlab软件分别使用newff和treebagger函数,采用在(4)中建立的训练样本集分别训练多层感知器和随机森林以比较哪种机器学习模型更适合积雪深度反演。多层感知器模型包括数据输入层,3个隐藏层和一个输出层。随机森林模型包括多个决策树每个决
策树包括多个叶子。对于多层感知器的训练算法需要选择为levenberg
‑
marquardt算法,训练终止目标(即收敛阈值)设置为0.0001。最大迭代学习次数设置为2000。损失函数选择为平均绝对误差。学习速率设置为0.01,每个隐藏层分别设置为25,20,15个神经元。对于随机森林选择200棵决策树和5个叶子。
[0042]
使用均方根误差(rmse)、最优拟合度(r2)和偏差(bias)选择最优模型。不断重复训练多层感知器和随机森林200次并保存每次的网络结构,这样就形成了200个多层感知器和200个随机森林。然后把每个网络应用到测试样本中,分别记录相应均方根误差,最优拟合度以及偏差。利用最优拟合度分别对200个多层感知器和200个随机森林对模型进行评价,因为最优拟合度越大,均方根误差和偏差就越小。图3分别展示了200个多层感知器和200个随机森林模拟测试集中积雪深度的最优拟合度。分别在200个多层感知器和200个随机森林中挑选最优拟合度最高的模型,即为最优多层感知器和最优随机森林模型。最后对这两者最优模型利用以上3个评价指标进行评估选出最优模型。图4分别为最优多层感知器和最优随机森林在测试样本中模拟的积雪深度与oib实际积雪深度之间的对比,可以看到多层感知器模型更适合对北极积雪深度进行建模。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。