1.本发明属于物理技术领域,更进一步涉及分布式机器学习领域中的一种面向异构分布式机器学习集群的任务配置方法。本发明可用于大规模异构分布式机器学习集群中通过合理的任务配置,充分利用集群节点计算资源。
背景技术:
2.随着大数据时代的到来,用于训练机器学习模型的数据集呈现爆炸增长的趋势。训练速度快,动态灵活的分布式机器学习集群成为了大规模机器学习发展的必然趋势。分布式机器学习通过参数服务器把模型训练的任务放置到众多具有计算性能的集群节点上,缩短整个模型训练的时间。然而,大多数现有的节点资源不一致,是一种异构分布式机器学习集群,如果采用的固定任务配置,使其任务配置粒度过大,导致异构分布式机器学习集群节点资源利用效率低。为了解决现有问题,根据节点资源进行任务配置的方法应运而生。与传统的配置方法相比,该方法实现了对节点差异化配置任务,有效的地提高了异构分布式机器学习集群节点资源的利用率,具有广阔的应用前景。为了进一步提高异构分布式机器学习集群的训练效率,灵活的为每个节点配置任务,实现节点资源利用的最大化。面向异构分布式机器学习集群的任务放置方法就是用于解决这一问题的优化方法。
3.北京工业大学在其申请的专利文献“一种面向分布式机器学习的数据划分方法”(专利申请号cn202110035224.6,申请公布号cn 112732444 a)中提出了一种基于强化学习的分布式机器学习任务分配方法。该方法主要包括六个步骤。第一,初始化经验回放内存,网络和环境状态表。第二,神经网络训练,同时把各个时间的状态写入经验内存。第三,状态选取,采用轮循的方式从整个经验回放内存里抽取各个状态,若抽取状态优于当前状态,放入状态表中。第四,批尺寸管理器根据环境状态信息计算出每个工作节点应配置的批尺寸大小,第四,每个工作节点从批尺寸管理器拉取相应批尺寸大小的数据进行本地训练,将各自的梯度参数发送给参数服务器。第六,参数服务器进行梯度聚合后各个工作节点拉取相应的参数进行下一次迭代计算。通过更新状态表,为各个计算节点动态的分配任务,该方法存在的不足之处是,更新节点配置任务需要维护一个庞大的经验内存,内存的大小会限制异构分布式机器学习集群的规模。此外,因为状态表更新具有延时特性,任务分配与节点实时计算资源匹配度差,导致节点计算资源利用效率低。
4.ferdinand在其发表的论文“anytime exploitation of stragglers in synchronous st
‑
ochastic gradient descent”(machine learnin and applications,2017.12.10.1109)提出了一种基于节点工作完成度的任务分配的方法,该方法的主要包含以下步骤,在每次迭代结束后,工作节点将更新的参数矢量发送到参数服务器进行聚合,同时参数服务器根据各个工作节点完成的任务量来更新任务分配权重,确保下次迭代过程中各个节点计算资源得到充分利用。该方法的的优点是充分考虑每个计算节点的计算资源差异,一定程度上解决节点的任务数和节点性能匹配性的问题,提高模型的训练速度。该方法存在的不足之处是,由于每次迭代过程中都需要统计各个工作节点完成任务量,增加分布
式机器学习集群模型训练的时间。此外,该方法在任务配置的过程中未考虑突发因素的影响,导致计算节点配置任务与节点计算能力匹配度很大程度取决于集群的稳定程度,造成部分异构分布式机器学习集群中的节点空闲。
技术实现要素:
5.本发明的目的在于针对上述现有技术的不足,提出一种基面向异构分布式机器学习集群的任务配置方法,用于解决异构分布式机器学习集群节点资源利用率低和参数服务器为异构分布式机器学习集群中每个节点配置任务时间开销大的问题。。
6.实现本发明目的的思路是:本发明将每个节点资源的特征参数输入到构建的随机森林模型中,输出每个节点推断训练时间,计算为异构分布式机器学习集群中每个节点配置任务数,对资源越多的节点配置越多的任务,使每个节点训练卷积神经网络所需时间一致,防止训练较快的节点等待训练较慢的节点,可解决异构分布式机器学习集群节点资源利用率低的问题。本发明通过用发生变化节点资源的特征参数替代其变化前节点资源的特征参数,动态的为每个节点配置任务,与传统方法相比,无需统计每个节点训练完成的任务数,解决参数服务器为异构分布式机器学习集群中每个节点配置任务时间开销大的问题。
7.本发明的具体步骤如下:
8.步骤1,构建异构分布式机器学习集群:
9.将一个参数服务器和至少4个节点组成一个异构分布式机器学习集群;
10.步骤2,生成训练集和预测集:
11.(2a)参数服务器选取至少10000个图像组成的图像集,每个图像至少包含一个目标;
12.(2b)对每张图像中的每个目标进行标注,并为每个标注后的图像生成一个标签文件,将所有的标签文件组成标签集;
13.(2c)将图像集和标签集组成训练集;
14.(2d)从训练集中随机抽取至多1000个样本组成预测集;参数服务器将预测集下发至异构分布式机器学习集群中的每个节点;
15.步骤3,对卷积神经网络进行预训练:
16.(3a)异构分布式机器学习集群中的每个节点将其接收到的预测集输入到卷积神经网络中,利用随机梯度下降法迭代更新网络参数,直到损失函数收敛为止,得到每个节点对应预训练好的卷积神经网络并记录预训练时间;
17.(3b)将每个节点资源的特征参数、网络参数和预训练时间上传至参数服务器;
18.步骤4,生成参数服务器的随机森林训练样本子集:
19.使用bagging随机采样法,参数服务器对由所有节点的特征参数组成的特征参数集进行至少5次随机采样,将每次采样后部分节点的部分特征参数和节点的预训练时间组成该次采样的随机森林训练样本子集;
20.步骤5,构建随机森林模型:
21.参数服务器构建与每个随机森林训练样本子集对应的决策树,将所有的决策树组成随机森林模型;
22.步骤6,生成每个节点的推断训练时间:
23.将每个节点资源的特征参数发送给参数服务器,参数服务器将每个节点资源的特征参数依次输入到随机森林模型中,输出每个节点的推断训练时间;
24.步骤7,为每个节点配置任务:
25.(7a)按照下式,计算参数服务器为异构分布式机器学习集群中每个节点拟配置的任务数:
[0026][0027]
其中,r
α
表示参数服务器为异构分布式机器学习集群中第α个节点拟配置的任务数,h
α
表示第α个节点的推断训练时间,∑表示求和操作,i表示异构分布式机器学习集群中节点的序号,h
i
表示第i个节点的推断训练时间,*表示相乘操作,m表示训练集中所有样本数据的大小,v表示训练卷积神经网络的最大次数,该最大次数的取值为训练集中所有样本数据的大小与异构分布式机器学习集群中所有节点中内存最小值的比值。
[0028]
(7b)按照参数服务器为异构分布式机器学习集群中每个节点拟配置的任务数,给每个节点配置对应的任务;
[0029]
步骤8,更新预训练好的卷积神经网络:
[0030]
参数服务器对异构分布式机器学习集群中所有节点网络参数求均值,并将该均值作为全局网络参数,用该全局网络参数更新每个节点预训练好的卷积神经网络中的网络参数,得到每个节点更新后的卷积神经网络;
[0031]
步骤9,训练卷积神经网络:
[0032]
将每个节点配置任务输入到其对应的更新后的卷积神经网络中,卷积神经网络利用随机梯度下降法迭代更新网络参数,直到损失函数收敛为止,得到该节点训练好的卷积神经网络,并将该网络参数上传至参数服务器;
[0033]
步骤10,判断每个节点对应的卷积神经网络的训练次数是否达到最大次数,若是,则执行步骤12;否则,执行步骤11;
[0034]
步骤11,判断分布式机器学习集群中是否有节点资源特征参数发生变化,若是,则用发生变化节点资源的特征参数替代其变化前节点资源的特征参数后执行步骤6,否则,执行步骤7;
[0035]
步骤12,结束训练。
[0036]
本发明与现有技术相比较,具有以下优点:
[0037]
第一,本发明将每个节点资源的特征参数输入到构建的随机森林模型中,输出每个节点推断训练时间,计算每个节点应配置的任务数,克服了现有技术中未考虑威胁在异构分布式机器学习机器的不同节点间资源差异性的缺点,使得本发明更适用于实际的训练情况,提高了参数服务器为异构分布式机器学习集群中每个节点配置的任务与节点资源匹配度。
[0038]
第二,本发明通过用发生变化节点资源的特征参数替代其变化前节点资源的特征参数,动态的为每个节点配置任务,克服了现有技术中参数服务器为异构分布式机器学习集群中每个节点配置任务时,需要统计每个节点训练完成的任务数,导致时间开销大的问
题,使得本发明能够能够更快根据每个节点资源变化,动态的为每个节点配置任务。
[0039]
第三,本发明构建的随机森林模型不用删选特征值,对数据集适应性强,且输出的节点推断训练时间是真实训练时间的无偏估计,模型精度高。克服了现有技术中未考虑统计数据的偶然性的缺点,使得本发明能够更加精确为异构分布式机器学习集群中为每个节点配置任务。
附图说明
[0040]
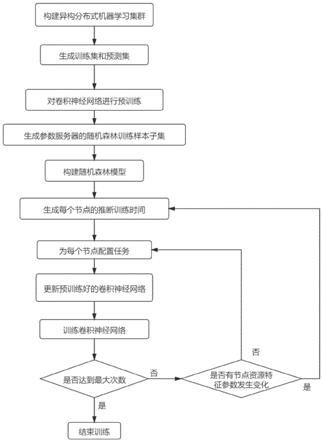
图1为本发明的流程图;
[0041]
图2是本发明异构分布式机器学习集群的架构图。
具体实施方式
[0042]
下面结合附图1对本发明做进一步的描述。
[0043]
参照图1对本发明实现的具体步骤做进一步的描述。
[0044]
步骤1,构建异构分布式机器学习集群。
[0045]
将一个参数服务器和至少4个节点组成一个异构分布式机器学习集群。
[0046]
参照图2,对本发明实施例构建的由一个参数服务器和8个节点组成的异构分布式机器学习集群做进一步的描述。
[0047]
步骤2,生成训练集和预测集。
[0048]
参数服务器选取至少10000个图像组成的图像集,每个图像至少包含一个目标。
[0049]
本发明的实施例中的图像来源于开源的cifar10数据集,共选取了20000个图像。每张图像包含一个飞机图像。
[0050]
对每张图像中的每个飞机图像进行标注,并为每个标注后的图像生成一个标签文件,将所有的标签文件组成标签集。
[0051]
将图像集和标签集组成训练集。
[0052]
从训练集中随机抽取至多1000个样本组成预测集;参数服务器将预测集下发至异构分布式机器学习集群中的每个节点。
[0053]
本发明的实施例中预测集是从20000个图像中随机抽取了500样本组成的。
[0054]
步骤3,对卷积神经网络进行预训练。
[0055]
异构分布式机器学习集群中的每个节点将其接收到的预测集输入到卷积神经网络中,利用随机梯度下降法迭代更新网络参数,直到损失函数收敛为止,得到每个节点对应预训练好的卷积神经网络并记录预训练时间。
[0056]
所述卷积神经网络的结构依次为:第一个卷积层,第一个池化层,第二个卷积层,第二个池化层,第三个卷积层,第三个池化层,第四个卷积层,第四个池化层,第一个全连接层。
[0057]
设置卷积神经网络结构各层参数如下:将第一至第四卷积层中卷积核的个数分别设置为16,16,8,8,卷积核的大小分别设置3
×
3,5
×
5,3
×
3,5
×
5,卷积步长均设置为1;第一至第四池化层均采用平均池化的方式,池化区域大小分别设置为1
×
4,1
×
4,1
×
1,1
×
1,步长均设置为1;将第一全连接层的神经元个数设置为2;
[0058]
所述损失函数如下:
[0059][0060]
其中,mse表示损失函数值,y
i
表示预测集中第i个样本的预测值,y
i
'表示预测集中第i个样本的真实值。
[0061]
将每个节点资源的特征参数、网络参数和预训练时间上传至参数服务器。
[0062]
所述节点资源的特征参数包括,可使用cpu核心的个数,可使用gpu sm的个数,cpu缓存的容量,内存的容量,pcie数据通路的总线带宽。
[0063]
步骤4,生成参数服务器的随机森林训练样本子集。
[0064]
使用bagging随机采样法,参数服务器对由所有节点的特征参数组成的特征参数集进行至少5次随机采样,将每次采样后部分节点的部分特征参数和节点的预训练时间组成该次采样的随机森林训练样本子集。
[0065]
步骤5,构建随机森林模型。
[0066]
参数服务器构建与每个随机森林训练样本子集对应的决策树,将所有的决策树组成随机森林模型。
[0067]
本发明的实施例中构建每个随机森林训练样本子集对应的决策树采用的算法为c4.5算法。
[0068]
本发明的实施例中将所有的决策树组成随机森林模型的方法为:将所有决策树的输入取并集,将该并集作为随机森林模型的输入,将所有决策树的输出取均值,将该均值作为随机森林模型的输出。
[0069]
步骤6,生成每个节点的推断训练时间。
[0070]
将每个节点资源的特征参数发送给参数服务器,参数服务器将8个节点资源的特征参数依次输入到随机森林模型中,输出8个节点的推断训练时间。
[0071]
步骤7,为每个节点配置任务。
[0072]
按照下式,计算参数服务器为异构分布式机器学习集群中每个节点拟配置的任务数:
[0073][0074]
其中,r
α
表示参数服务器为异构分布式机器学习集群中第α个节点拟配置的任务数,h
α
表示第α个节点的推断训练时间,∑表示求和操作,i表示异构分布式机器学习集群中节点的序号,h
i
表示第i个节点的推断训练时间,*表示相乘操作,m表示训练集中所有图像数据的大小,v表示训练卷积神经网络的最大次数,该最大次数的取值为训练集中所有样本数据的大小与异构分布式机器学习集群中每个节点中内存最小值的比值。
[0075]
本发明的实施例中将训练卷积神经网络的最大次数设置为25,其理由是由于本发明的实施例中训练集中的20000个飞机图像数据大小之和为40g,8个节点中最小内存为2g。为了保证即使将所有训练任务配置在该节点上也不会造成内存溢出,将每次训练的所有飞机图像数据的大小之和设置为2g,训练完所有飞机图像需要25次,所以将本发明训练卷积神经网络的最大次数设置为25次。
[0076]
按照参数服务器为异构分布式机器学习集群中每个节点拟配置的任务数,给每个节点配置对应的任务。
[0077]
本发明的实施例中给每个节点配置对应的任务时使用随机采样法,参数服务器从训练集中进行8次采样,每次采集k个任务,将每次采样到的k个任务下发给第i个节点,完成了对该节点的任务配置,其中,p的取值与异构分布式机器学习集群中节点的总数相等,k的取值与异构分布式机器学习集群中每个节点拟配置的任务数相等,i的取值与k的取值相等。
[0078]
步骤8,更新预训练好的卷积神经网络。
[0079]
参数服务器对异构分布式机器学习集群中8个节点网络参数求均值,并将该均值作为全局网络参数,用该全局网络参数更新每个节点预训练好的卷积神经网络中的网络参数,得到每个节点更新后的卷积神经网络。
[0080]
步骤9,训练卷积神经网络。
[0081]
将每个节点配置任务输入到其对应的更新后的卷积神经网络中,卷积神经网络利用随机梯度下降法迭代更新网络参数,直到损失函数收敛为止,得到该节点训练好的卷积神经网络,并将该网络参数上传至参数服务器。
[0082]
所述损失函数如下:
[0083][0084]
其中,f(θ)表示损失函数值,m表示任务数据集的样本总数,z
i
表示任务数据集中第i个样本的预测值,z
i
'表示任务数据集中第i个样本的真实值。
[0085]
步骤10,判断每个节点对应的卷积神经网络的训练次数是否达到25次,若是,则执行步骤12;否则,执行步骤11。
[0086]
步骤11,判断分布式机器学习集群中是否有节点资源特征参数发生变化,若是,则用发生变化节点资源的特征参数替代其变化前节点资源的特征参数后执行步骤6,否则,执行步骤7。
[0087]
本发明的实施例中判断分布式机器学习集群中是否有节点资源特征参数发生变化的方法是判断节点资源特征参数的相对变化量是否大于阈值。因为节点资源特征参数的相对变化量小于10%时,更新特征参数对节点任务配置影响不大,所以本发明将阈值设置为10%。
[0088]
步骤12,结束训练。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。