技术特征:
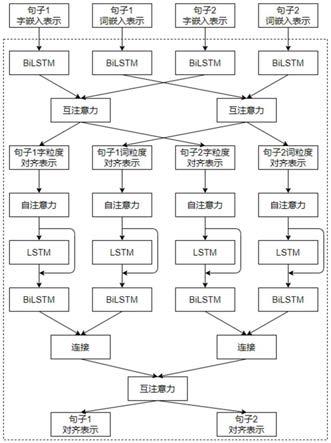
1.一种面向高考咨询基于多视角注意力的智能语义匹配方法,其特征在于,该方法通过构建并训练由多粒度嵌入模块、多视角语义匹配模块、特征比对模块及标签预测模块所构成的语义匹配模型,捕获句子对在同一粒度上的语义对齐信息,通过自注意力机制获取句子中重要的语义成分,并进行句子间互注意力操作,得到句子级别的语义对齐表示,同时对两个句子进行相似性衡量,以判断句子对所蕴含的语义意图是否一致;具体如下:多粒度嵌入模块对输入的句子以字粒度和词粒度分别进行嵌入操作,得到句子的字词嵌入表示;多视角语义匹配模块对句子的字词嵌入表示依次进行互注意力与自注意力操作以及句子级别的互注意力操作,得到句子级别的高层次语义对齐表示;特征比对模块对句子级别的高层次语义对齐表示进行比较并进行一维最大池化操作,得到句子对的语义匹配向量;标签预测模块将句子对的语义匹配张量映射为指定区间上的一个浮点型数值,将其作为匹配值与预设的阈值进行比较,根据比较结果,判定句子对的语义意图是否一致。2.根据权利要求1所述的面向高考咨询基于多视角注意力的智能语义匹配方法,其特征在于,所述多粒度嵌入模块用于构建字词映射转换表、构建输入模块、构建字词向量映射层;其中,构建字词映射转换表:映射规则为以数字1为起始,随后按照每个字或词被录入字词表的顺序依次递增排序,从而形成字词映射转换表;其后,再使用word2vec训练字词向量模型,得到各字词的字词向量矩阵;构建输入模块:输入层包括四个输入,对于训练数据集中的每一个句子对或待预测的句子对,对其进行断字和分词预处理,分别获取sentence1_char、sentence2_char、sentence1_word和sentence2_word,其中后缀char、word分别表示对相应句子进行断字或分词处理而得,将其形式化为:(sentence1_charsentence2_char,sentence1_word,sentence2_word);对于输入句子中的每个字和词都按照字词映射转换表转化为相应的数字标识;构建字词向量映射层:加载构建字词映射转换表步骤中训练所得的字词向量矩阵来初始化当前层的权重参数;针对输入句子sentence1_char、sentence2_char、sentence1_word和sentence2_word得到其相应句子向量sentence1_char_embed、sentence2_char_embed、sentence1_word_embed和sentence2_word_embed。3.根据权利要求1所述的面向高考咨询基于多视角注意力的智能语义匹配方法,其特征在于,所述多视角语义匹配模块的构建过程具体如下:字词粒度语义特征表示的提取:首先使用bilstm编码器对两个句子的字嵌入表示和词嵌入表示进行编码,得到两句子的字粒度语义特征表示和词粒度语义特征表示;对于句子1,公式如下:公式如下:其中,l为句子的长度,p
ic
和分别表示句子1在第i个位置处的字嵌入表示和字粒度语义特征表示,和分别表示句子1在第m个位置处的词嵌入表示和词粒度语义特征表示;
对于句子2,公式如下:公式如下:其中公式(3)和(4)的符号含义与公式(1)和(2)大致相同,区别在于,q表示句子2,j表示句子2在字粒度下的第j个位置,n表示句子2在词粒度下的第n个位置,其余表示可以类比表示;句子对同一粒度的互注意力操作:对得到的两个句子的字粒度语义特征表示和词粒度语义特征表示进行同一粒度的互注意力操作,即在字粒度下进行句子1和句子2的互注意力操作,得到字粒度级别的句子1与句子2的对齐表示,在词粒度下进行句子1和句子2的互注意力操作,得到词粒度级别的句子1与句子2的对齐表示;对于字粒度级别的句子对的互注意力机制,公式如下:公式如下:公式如下:其中,tanh为激活函数,exp为指数函数,s1
ij
为在字粒度级别下句子1的第i个位置和句子2第j个位置的相似度权重,w
c1
和w
c2
为可训练的权重参数,和的含义与公式(1)、(3)一致,为句子1在字粒度级别下第i个位置处的字粒度语义对齐表示,是根据相似度权重对句子2中每个字的字粒度语义特征表示加权求和得到的,同理表示句子2在字粒度级别下第j个位置处的字粒度语义对齐表示;对于词粒度级别的互注意力机制,公式如下:公式如下:公式如下:其中各符号含义可以类比公式(5)
‑
(7),此处只是将用于代表字的上标或下标c改为用于代表词的上标或下标w,和分别表示在词粒度级别下句子1在第m个位置处的词粒度语义特征表示和词粒度语义对齐表示,和分别表示在词粒度级别下句子2在第n个位置处的词粒度语义特征表示和词粒度语义对齐表示;句子字词粒度的自注意力操作:对进行互注意力机制操作后得到的句子对的字词粒度语义对齐表示进行自注意力操作,即对句子1的字粒度和词粒度分别进行自注意力操作,得到句子1在字粒度级别下的重要语义特征与词粒度级别下的重要语义特征,可以以此类推
句子2的相关处理;对于句子1的字粒度和词粒度下的自注意力机制操作以及重要特征的提取,公式如下:公式如下:公式如下:公式如下:其中,c
p1
和c
p2
表示句子1在字粒度级别下可训练的权重参数,w
p1
和w
p2
表示句子1在词粒度级别下可训练的权重参数,和分别表示句子1在字粒度和词粒度级别下的语义对齐表示的集合,分别由公式(6)中的和公式(9)中的组成,p
c'
和p
w'
分别表示句子1在字粒度和词粒度级别下的注意力矩阵,和分别表示句子1在字粒度和词粒度级别下所包含的重要语义特征,该重要语义特征的个数是一个超参数;同理可提取出句子2在字词粒度下所包含的重要语义特征,公式如下:公式如下:公式如下:公式如下:其中,c
q1
和c
q2
表示句子2在字粒度级别下可训练的权重参数,w
q1
和w
q2
表示句子2在词粒度级别下可训练的权重参数,和分别表示句子2在字粒度和词粒度级别下的语义对齐表示的集合,分别由公式(7)中的和公式(10)中的组成,q
c'
和q
w'
分别表示句子2在字粒度和词粒度级别上的注意力矩阵,和分别表示句子2在字粒度和词粒度级别下所包含的重要语义特征,该重要语义特征的个数是一个超参数,代表重要语义特征的个数;基于上下文的特征感知:为了更好地感知上下文特征,对于上述提取的重要语义特征使用lstm编码器进行编码以得到浅层编码表示,同时将重要语义特征与浅层编码表示连接之后再送入bilstm编码器进行再次编码,得到深层编码表示,公式如下:公式如下:公式如下:公式如下:其中,(;)表示concatenate连接操作,和表示句子1在字粒度下提取的重要语义
特征和词粒度下提取的重要语义特征,分别由公式(12)和(14)计算所得,和表示句子2在字粒度下提取的重要语义特征和词粒度下提取的重要语义特征,分别由公式(16)和(18)计算所得,和分别表示句子1字粒度和词粒度的深层编码表示,和分别表示句子2字粒度和词粒度的深层编码表示;句子级别的互注意力操作:为了得到句子级别的高层次语义对齐表示,首先将句子对的字词粒度深层编码表示以句子为单位进行连接,随后进行句子级别的互注意力机制,以得到句子级别的高层次语义对齐表示,公式如下:公式如下:公式如下:和分别表示句子1字粒度和词粒度的深层编码表示,分别由公式(19)和(20)计算所得,和分别表示句子2字粒度和词粒度的深层编码表示,分别由公式(21)和(22)计算所得,表示将句子1的字粒度和词粒度的深层编码表示进行连接后得到的句子级别的深层编码表示,表示将句子2的字粒度和词粒度的深层编码表示进行连接后得到的句子级别的深层编码表示;随后对两个句子进行互注意力机制,得到两个句子相互感知的句子级别的高层次语义对齐表示,此处操作与两个句子在同一粒度的互注意力机制较为相似,省略其公式描述,仅给出句子级别的高层次语义对齐表示和4.根据权利要求1所述的面向高考咨询基于多视角注意力的智能语义匹配方法,其特征在于,所述特征比对模块的构建过程具体如下:首先使用绝对值函数强调两个句子之间的绝对差异,同时使用哈达玛积来计算两个句子之间的相似程度,随后将句子对的绝对差异表示与相似程度表示进行连接并将连接结果进行一维最大池化以得到句子对语义匹配张量;公式如下:公式如下:sim=(abs;mul)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(27)sim
pool
=globalmaxpooling(sim)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(28)其中,(;)表示concatenate连接操作,和分别表示句子1和句子2的高层次语义对齐表示,abs为绝对值函数运算的结果,mul为哈达玛积运算的结果,随后将这两个结果进行连接得到sim,最后对该结果sim进行一维最大池化操作得到句子对语义匹配张量sim
pool
。5.根据权利要求1所述的面向高考咨询基于多视角注意力的智能语义匹配方法,其特征在于,所述标签预测模块构建过程如下:将句子对语义匹配张量作为输入,标签预测模块包含三层全连接网络;前两层是维度
为600、激活函数为relu函数的全连接网络,最后一层是维度为1、激活函数为sigmoid函数的全连接网络;得到一个处于[0,1]之间的匹配度数值,记为y
pred
,最终通过与设定的阈值0.5进行比较,从而判断句子对的语义意图是否一致;即若y
pred
≥0.5时,预测该句子对的语义意图是一致的,否则,不一致;当句子对语义匹配模型尚未充分训练时,需要在根据语义匹配知识库而构建的训练数据集上进行训练,以优化模型参数;当模型训练完毕时,标签预测模块可预测目标句子对的语义意图是否一致。6.根据权利要求1所述的面向高考咨询基于多视角注意力的智能语义匹配方法,其特征在于,所述句子对语义匹配知识库构建具体如下:收集数据:收集高考咨询的常见问题句子,作为句子对语义匹配知识库的原始数据;预处理原始数据:预处理用于构建句子对语义匹配知识库的原始数据,对其中的每个句子均进行断字操作、分词操作,得到句子对语义匹配断字处理知识库、分词处理知识库;汇总子知识库:汇总句子对语义匹配断字处理知识库和句子对语义匹配分词处理知识库,构建句子对语义匹配知识库;所述句子对语义匹配模型通过使用训练数据集进行训练而得到,训练数据集的构建过程如下:构建训练正例:将句子对语义匹配知识库中将两个句子语义一致的句子对构建为正例;构建训练负例:选中一个句子s1,再从句子对语义匹配知识库中随机选择一个与句子s1不匹配的句子s2,将s1与s2进行组合,构建负例;构建训练数据集:将经过构建训练正例和构建训练负例操作后所获得的全部的正例样本句子对和负例样本句子对进行组合,并打乱其顺序,构建最终的训练数据集;所述句子对语义匹配模型构建完成后通过训练数据集进行句子对语义匹配模型的训练与优化,具体如下:构建损失函数:由标签预测模块构建过程可知,y
pred
是经过句子对语义匹配模型处理后得到的匹配度计算数值,y
true
是两个句子语义是否匹配的真实标签,其取值仅限于0或1,采用交叉熵作为损失函数;优化训练模型:使用adam优化函数;在训练数据集上,对句子对语义匹配模型进行优化训练。7.一种面向高考咨询基于多视角注意力的智能语义匹配装置,其特征在于,该装置包括句子对语义匹配知识库构建单元、训练数据集生成单元、句子对语义匹配模型构建单元、句子对语义匹配模型训练单元,分别实现权利要求1
‑
6所描述的面向高考咨询基于多视角注意力的智能语义匹配方法的步骤。8.一种存储介质,其中存储有多条指令,其特征在于,所述指令有处理器加载,执行权利要求1
‑
6中所述的面向高考咨询基于多视角注意力的智能语义匹配方法的步骤。9.一种电子设备,其特征在于,所述电子设备包括:权利要求8所述的存储介质;以及处理器,用于执行所述存储介质中的指令。
技术总结
本发明公开了一种面向高考咨询基于多视角注意力的智能语义匹配方法与装置,属于人工智能、自然语言处理技术领域。本发明要解决的技术问题为判断句子对蕴含的语义意图是否一致,采用的技术方案为:通过构建并训练由多粒度嵌入模块、多视角语义匹配模块、特征比对模块及标签预测模块所构成的语义匹配模型,捕获句子对在同一粒度上的语义对齐信息,通过自注意力机制获取句子中重要的语义成分,并进行句子间互注意力操作,得到句子级别的语义对齐表示,同时对两个句子进行相似性衡量,以判断句子对所蕴含的语义意图是否一致。该装置包括句子对语义匹配知识库构建单元、训练数据集生成单元、句子对语义匹配模型构建单元及句子对语义匹配模型训练单元。义匹配模型训练单元。义匹配模型训练单元。
技术研发人员:鹿文鹏 左有慧 赵鹏宇 于瑞
受保护的技术使用者:齐鲁工业大学
技术研发日:2021.08.27
技术公布日:2021/11/28
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。