技术特征:
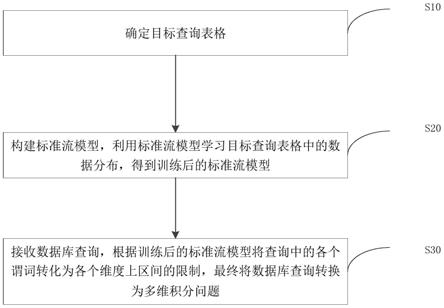
1.一种数据库对查询进行基数估计的方法,其特征在于,该方法包括以下步骤:确定目标查询表格;构建标准流模型,利用标准流模型学习所述目标查询表格中的数据分布,得到训练后的标准流模型;接收数据库查询,根据所述训练后的标准流模型将查询中的各个谓词转化为各个维度上区间的限制,最终将所述数据库查询转换为多维的积分问题。2.根据权利要求1中所述的方法,其特征在于,所述利用标准流模型学习所述目标查询表格中的数据分布,包括:分别将所述目标查询表格中各种类型的数据编码转换为相同维度的连续型数值;将多维连续型数值作为训练数据输入到标准流模型,使用最大似然估计对标准流模型进行训练,以使标准流模型学习到连续型数值以联合概率密度形式表达的数据分布。3.根据权利要求2中所述的方法,其特征在于,所述根据所述训练后的标准流模型将查询中的各个谓词转化为各个维度上区间的限制,最终将所述数据库查询转换为多维的积分问题,包括:将所述概率密度形式表达的数据分布作为被积函数,构建蒙特卡洛积分方法以快速计算积分;所述将所述概率密度形式表达的数据分布作为被积函数,构建蒙特卡洛积分方法以快速计算积分,包括:对每一维度数据分桶来表示数据分布,利用桶的宽度表示不同维度数据不同取值范围的稀疏程度;在每个桶内均匀采样,得到不同批次的采样点,将不同批次的采样点输入至标准流模型,输出每个批次的采样点的概率密度,利用各个批次的采样点的概率密度对各个维度的桶的宽度进行调整;在判断桶宽度的变化小于一定阈值时,利用各个批次的采样点及标准流模型计算的概率密度完成对积分的估计;在判断桶宽度的变化不小于一定阈值时,重复上述按照桶的宽度生成采样点和更新桶的宽度的步骤,直至收敛时整合完整迭代过程中采集到的点,得到积分的估计。4.根据权利要求3中所述的方法,其特征在于,在得到积分的估计之后,还包括:将估计的选择度与全表基数的乘积作为对基数的估计返回给优化器或用户。5.根据权利要求2-4任一项中所述的方法,其特征在于,所述分别将所述目标查询表格中各种类型的数据编码转换为相同维度的连续型数值,包括:对于类别型数据,将各个类别离散化为整数形式,通过去量化方法对每个离散数值在离散间距内生成噪声进行调整,以将离散形式转变为连续形式;对于数值型数据,在数值型数据为离散型时,利用上述方式将离散型的数值型数据通过去量化方式变换为连续型的数值型数据,在数值型数据为连续型时,利用上述方式中对离散型数据进行去量化相同的方法添加噪声;对于字符串数据,利用完整的字符串数据简历字典树结构,按照深度优先遍历序将字典树中的作为字符串数据中任意字符串结尾的节点编号,利用编号实现将任意字符串数据中的字符串转换为离散形式的整数,再利用上述步骤中的方法将转换后的整数去量化,转
化为连续形式。6.根据权利要求5中所述的方法,其特征在于,所述构建标准流模型,利用标准流模型学习所述目标查询表格中的数据分布,得到训练后的标准流模型,包括:构建标准流模型,所述标准流模型由多个耦合层组成,每个耦合层包括一个由多层全连接神经网络决定变换系数的变换函数,每个耦合层的输入输出维度相同;将所述目标查询表格中的原始数据按照上述编码方式进行处理转换为连续形式的数据,再将连续形式的数据输入至标准流模型,在标准流模型中经过各个耦合层,传给每个耦合层对应的全连接神经网络,以使全连接神经网络输出得到耦合层变换的参数;重复上述步骤,直至经过所有耦合层,得到最终的输出结果,使用最大似然估计作为标准流模型的损失函数,通过梯度下降与反向传播更新标准流模型中各个全连接神经网络的参数;对训练得到的标准流模型进行验证,其中,将所述目标查询表格中所有条目编码输入到标准流模型,得到每一个条目的概率密度的估计,计算所有概率密度的对数之和,在所有概率密度的对数之和大于历史最大值时,将标准流模型作为最优标准流模型;重复上述步骤,直至达到指定的训练次数,或者,标准流模型达到收敛。7.一种数据库对查询进行基数估计的装置,其特征在于,包括:确定模块,用于确定目标查询表格;训练模块,用于构建标准流模型,利用标准流模型学习所述目标查询表格中的数据分布,得到训练后的标准流模型;查询模块,用于接收数据库查询,根据所述训练后的标准流模型将查询中的各个谓词转化为各个维度上区间的限制,最终将所述数据库查询转换为多维的积分问题。8.一种计算机设备,其特征在于,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时,实现如权利要求1-6中任一所述的方法。9.一种非临时性计算机可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现如权利要求1-6中任一所述的方法。
技术总结
本发明提出一种数据库中对查询进行基数估计的方法及装置,其中,该方法包括:确定目标查询表格,并构建标准流模型,利用标准流模型学习目标查询表格中的数据分布,得到训练后的标准流模型,之后接收数据库查询,根据训练后的标准流模型将查询中的各个谓词转化为各个维度上区间的限制,最终将数据库查询转换为多维的积分问题。该方法利用蒙特卡洛采样方法,通过采样实现对基数的准确估计。通过直接学习数据的分布,保证了模型可以支持各种类型各种分布的查询,提高了方法的通用性。提高了方法的通用性。提高了方法的通用性。
技术研发人员:李国良
受保护的技术使用者:清华大学
技术研发日:2021.11.19
技术公布日:2022/4/12
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。