技术特征:
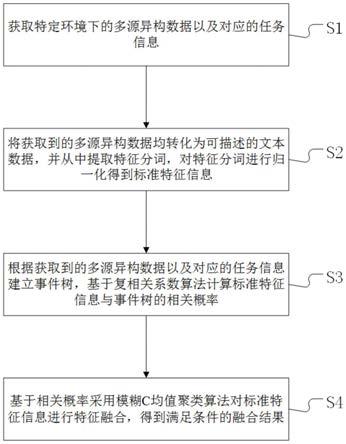
1.一种基于模糊c均值聚类算法的多源异构数据融合方法,其特征在于,所述方法包括:s1,获取特定环境下的多源异构数据以及对应的任务信息;s2,将获取到的多源异构数据均转化为可描述的文本数据,并从中提取特征分词,对特征分词进行归一化得到标准特征信息;s3,根据获取到的多源异构数据以及对应的任务信息建立事件树,基于复相关系数算法计算标准特征信息与事件树的相关概率;s4,基于相关概率采用模糊c均值聚类算法对标准特征信息进行特征融合,得到满足条件的融合结果。2.如权利要求1所述的一种基于模糊c均值聚类算法的多源异构数据融合方法,其特征在于,步骤s1具体包括:所述多源异构数据包括多个来源的数据集和多个模态的数据集,还包括文本数据集、语音数据集、图像数据集以及视频数据集。3.如权利要求2所述的一种基于模糊c均值聚类算法的多源异构数据融合方法,其特征在于,步骤s2中,将获取到的多源异构数据均转化为可描述的文本数据,并从中提取特征分词具体包括:获取语音数据集的音频帧,记录每一帧中发出的声音的实体对象生成声音特征,结合对应帧的音频内容生成语音的文本数据;采用卷积神经网络提取图像数据集中的图像特征,并用文本的形式描述出来,得到图像的文本数据;获取视频数据集中需要处理的图像帧,识别图像帧中各实体对象,并记录各实体对象的特征,得到图像特征,获取视频数据集中的音频信号以及需要处理的音频帧,记录每一帧中发出的声音的实体对象生成声音特征,结合音频内容、字幕内容以及图像特征得到音频的文本数据;对文本数据集、语音的文本数据、图像的文本数据以及音频的文本数据进行行分词处理和去停用词处理,采用tf-idf特征提取方法提取特征分词。4.如权利要求3所述的一种基于模糊c均值聚类算法的多源异构数据融合方法,其特征在于,步骤s2中,对特征分词进行归一化得到标准特征信息具体包括:所述特征分词中有n条特征数据,表示为x={x1,x2,
…
,x
n
};对特征分词中的每一条特征数据求标准差,其计算公式为:其中,i=1,2,
…
,n,表示特征数据的均值,对特征分词中的每一条特征数据进行z-score归一化处理,其计算公式为
其中,x
i
为原始的特征数据,x
′
i
为归一化后的特征数据,即标准特征信息。5.如权利要求4所述的一种基于模糊c均值聚类算法的多源异构数据融合方法,其特征在于,步骤s3中,根据获取到的多源异构数据以及对应的任务信息建立事件树具体包括:将获取到的多源异构数据作为根节点,将标准特征信息作为子节点,对应的任务信息作为叶子节点建立事件树。6.如权利要求5所述的一种基于模糊c均值聚类算法的多源异构数据融合方法,其特征在于,步骤s3中,基于复相关系数算法计算标准特征信息与事件树的相关概率具体包括:所述复相关系数算法的计算公式为:其中,r表示复相关系数,y表示对应的任务信息,表示对应的任务信息中子数据的均值,x
′
i
表示标准特征信息,代表回归系数,n表示事件树中叶子节点的数量。7.如权利要求1所述的一种基于模糊c均值聚类算法的多源异构数据融合方法,其特征在于,步骤s4具体包括:设置一个相关概率阈值,将大于及等于相关概率阈值的标准特征信息保留下来,采用模糊c均值聚类算法进行特征融合;将小于相关概率阈值的标准特征信息舍弃。8.如权利要求7所述的一种基于模糊c均值聚类算法的多源异构数据融合方法,其特征在于,采用模糊c均值聚类算法进行特征融合具体包括:s401,获取标准特征信息,表示为x
′
={x
′1,x
′2,
…
,x
′
n
},确定聚类数c,将标准特征信息分为c个组,初始化每组的聚类中心c
j
,确定加权指数m、终止误差ε以及最大迭代次数max;s402,初始化由隶属度函数确定的隶属度矩阵;s403,在每次迭代过程中,更新隶属度矩阵的隶属值和每组的聚类中心;s404,当两次迭代过程中的隶属度矩阵的隶属值变化小于终止误差ε或者达到最大迭代次数max时,算法终止,否则,重复步骤s403。9.如权利要求8所述的一种基于模糊c均值聚类算法的多源异构数据融合方法,其特征在于,步骤s403具体包括:第t次迭代过程中,隶属度矩阵的隶属值计算公式为:其中,i=1,2,
…
,n,j=1,2,
…
,c,c
jt-1
为第t-1次迭代过程中每组的聚类中心,m为加权指数,x
′
i
为第i个标准特征信息;第t次迭代过程中,每组聚类中心的计算公式为:
其中,u
ijt
表示第t次迭代过程中的隶属度矩阵的隶属值。10.一种基于模糊c均值聚类算法的多源异构数据融合系统,其特征在于,所述系统包括:数据获取模块,获取特定环境下的多源异构数据以及对应的任务信息;特征提取模块,将获取到的多源异构数据均转化为可描述的文本数据,并从中提取特征分词,对特征分词进行归一化得到标准特征信息;相关概率计算模块,根据获取到的多源异构数据以及对应的任务信息建立事件树,基于复相关系数算法计算标准特征信息与事件树的相关概率;融合模块,基于相关概率采用模糊c均值聚类算法对标准特征信息进行特征融合,得到满足条件的融合结果。
技术总结
本发明提出了一种基于模糊C均值聚类算法的多源异构数据融合方法及系统,其方法包括:获取特定环境下的多源异构数据以及对应的任务信息;将获取到的多源异构数据均转化为可描述的文本数据,并从中提取特征分词,对特征分词进行归一化得到标准特征信息;根据获取到的多源异构数据以及对应的任务信息建立事件树,基于复相关系数算法计算标准特征信息与事件树的相关概率;基于相关概率采用模糊C均值聚类算法对标准特征信息进行特征融合,得到满足条件的融合结果。本发明先提取标准特征信息再采用模糊C均值聚类算法进行融合,实现了数据类型复杂且数据维数大情况下的多源异构数据的有效融合,提高了多源异构数据融合方法在实际应用中的利用率。际应用中的利用率。际应用中的利用率。
技术研发人员:杜登斌 杜乐 杜小军
受保护的技术使用者:武汉东湖大数据交易中心股份有限公司
技术研发日:2022.01.21
技术公布日:2022/4/12
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。