技术特征:
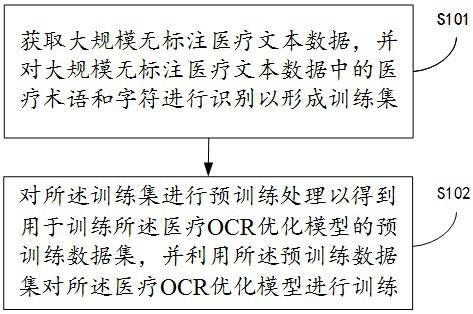
1.一种医疗ocr优化模型训练方法,其特征在于,包括:获取大规模无标注医疗文本数据,并对所述大规模无标注医疗文本数据中的医疗术语和字符进行识别以形成训练集;对所述训练集进行预训练处理以得到用于训练所述医疗ocr优化模型的预训练数据集,并利用所述预训练数据集对所述医疗ocr优化模型进行训练;其中,所述预训练处理包括:对所述训练集中的低频术语和低频字符进行数据增广处理;将所述训练集中的第一目标字符随机替换为错误字符;对所述训练集中的第二目标字符进行遮挡;以及将所述训练集切分为多个文本段落,得到用于训练所述医疗ocr优化模型的预训练数据集。2.根据权利要求1所述的方法,其特征在于,在所述对所述训练集中的低频术语和低频字符进行数据增广处理之前,进一步包括:统计识别出的所述训练集中的每个医疗术语和字符的频次,根据相应的低频阈值来确定所述训练集中的低频术语和低频字符。3.根据权利要求1所述的方法,其特征在于,在所述形成训练集之后,进一步包括:利用医疗知识图谱对所述训练集进行医疗术语的表示学习,并在表示空间进行映射。4.根据权利要求1所述的方法,其特征在于,所述将所述训练集中的第一目标字符随机替换为错误字符,进一步包括:从所述训练集中的医疗术语和字符中筛选第一目标字符,其中所述第一目标字符包括字形相似字典中所包含的字符和/或医疗常用字符。5.根据权利要求1或4所述的方法,其特征在于,所述利用所述预训练数据集对所述医疗ocr优化模型进行训练,进一步包括:在已将所述第一目标字符随机替换为错误字符之后,将当前训练集作为第一数据集,迭代地根据当前上下文提取所述第一数据集中的所述错误字符,并预测与所述错误字符相对应的所述第一目标字符以训练所述医疗ocr优化模型的字符纠错能力。6.根据权利要求1所述的方法,其特征在于,所述利用所述预训练数据集对所述医疗ocr优化模型进行训练,进一步包括:在已遮挡所述第二目标字符之后,将当前训练集作为第二数据集,迭代地根据当前上下文预测与所述第二数据集中的被遮挡位置相对应的所述第二目标字符以训练所述医疗ocr优化模型识别遮挡内容的能力。7.根据权利要求1所述的方法,其特征在于,所述利用所述预训练数据集对所述医疗ocr优化模型进行训练,进一步包括:迭代地根据当前上下文预测所述预训练数据集中的段落结束语句以训练所述医疗ocr优化模型自动分段的能力。8.一种医疗ocr数据优化方法,其特征在于,包括:获取目标医疗图像,并对目标医疗图像进行ocr识别,得到待优化文本数据;将所述待优化文本数据输入医疗ocr优化模型,以使所述医疗ocr优化模型输出与所述待优化文本数据对应的医疗术语和字符识别结果;
其中,所述医疗ocr优化模型预先基于权利要求1至7任一所述的医疗ocr优化模型训练方法得到。9.一种电子设备,其特征在于,包括处理器和存储器,所述存储器存储有多条指令,所述处理器用于读取所述指令并执行如权利要求1至7任一所述的医疗ocr数据优化模型训练方法,或者执行如权利要求8所述的医疗ocr数据优化方法。10.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质存储有多条指令,所述多条指令可被处理器读取并执行如权利要求1至7任一所述的医疗ocr数据优化模型训练方法,或者执行如权利要求8所述的医疗ocr数据优化方法。
技术总结
本发明公开一种医疗OCR数据优化模型训练方法、优化方法及设备,训练方法包括:获取大规模无标注医疗文本数据,对文本数据中的医疗术语和字符进行识别以形成训练集;对训练集进行预训练处理以得到用于训练医疗OCR优化模型的预训练数据集,并利用预训练数据集对医疗OCR优化模型进行训练;所述预训练处理包括:对训练集中的低频术语和低频字符进行数据增广处理;将训练集中的第一目标字符随机替换为错误字符;对训练集中的第二目标字符进行遮挡;以及训练集切分为多个文本段落,得到用于训练医疗OCR优化模型的预训练数据集。本发明利用医疗领域预训练语言模型对医疗OCR结果进行结构化提取、错误识别及优化,提升了医疗OCR的准确率。率。率。
技术研发人员:安波
受保护的技术使用者:北京智源人工智能研究院
技术研发日:2022.03.24
技术公布日:2022/4/22
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。