技术特征:
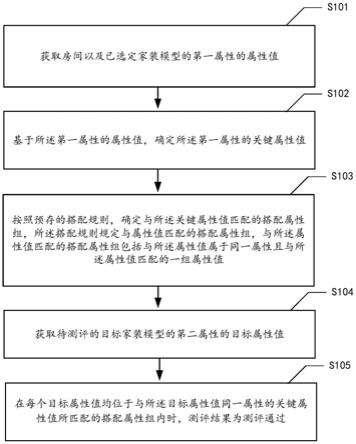
1.一种柴油机数据识别方法,其特征在于:包括模型构建、模型应用两部分,所述模型构建包括如下步骤:s1:基于领域的通识认知建立通识规则库、基于专家的领域知识建立规则库;s2:读取容量不低于4g且字段信息完整的数据表,将其高斯滤波后的数据作为训练样本;s3:结合专家知识规则库准则将训练样本分为a、b、c三类训练样本;s4:分别针对a、b、c三类训练样本进行特征提取,并对特征数据进行标签处理;s5:将特征数据与标签作为最终训练集导入随机森林分类器,以标签作为分类类型对随机森林分类器进行训练分别得到a、b、c子分类器;模型应用部分包括以下步骤:p1:读取数据条目高于5000条的待识别柴油机数据表,然后按照所述s2的方法完成高斯平滑降噪,如果数据处理完成后的数据条目不足,则跳过本次数据识别过程,p2~p5不执行;p2:基于步骤s1中已内置的通识规则库识别导入数据中的时间戳字段、编号序列字段;按照所述s3的步骤完成a、b、c三类训练数据集归并;p3:按照所述步骤s4中分别针对a、b、c三类训练样本进行特征提取形成特征数据样本;p4:分别将a、b、c三类特征数据样本输入a、b、c子分类器,a、b、c子分类器将分别输出其多个字段数据所对应的标签值;p5:根据预测标签值给原始导入数据表单添加列名,形成带有表头信息的规整的数据表格。2.根据权利要求1所述的一种柴油机数据识别方法,其特征在于:所述s1中建立的领域知识规则库的具体方法为:在知识规则库内部预置入3条数据分类规则条件,分别为:
①
满足如下条件的归为a类数据,使a类数据包含要求转速、实际转速、要求齿杆:x(i)>=800,x(i)指的是a类数据内的任一变量的数据序列;所述规则普遍适应运行状态正常的大功率增压柴油机,但不排除存在极少数的随机异常数据的出现,下式引入的滤波算子能够消除该随机因素:∑sgnx(x(i)-800)>0.99*n,n为差分序列长度,0.99为滤波算子;
②
满足如下条件归为c类数据,使c类数据包括大气压力、进气温度、水温、电压值:x(i)<110,x(i)指的是c类数据内的任一变量形成的数据序列;所述规则普遍适应运行状态正常的大功率增压柴油机,但不排除存在极少数的随机异常数据的出现,下式引入的滤波算子能够消除该随机因素:∑sgnx(110-x(i))>0.99*n,n为差分序列长度,0.99为滤波算子;
③
不满足
①
、
②
的归为b类数据,使b类数据包括机油压力、进气压力、排气温度。3.根据权利要求1所述的一种柴油机数据识别方法,其特征在于:所述s1的通识规则库至少包括2条通识规则条件,一是时间戳字符串编码格式必须符合国际编码方式才判定为时间戳字段,如无符合条件字段则不输出;二是编号序列以整形变量形式进行存储,且变量数值升序排列,升序增量为1,该规则同样引入滤波算子平滑随机噪声:∑sgnx(diff_x(i))>0.99*n其中,diff_x为编号序列形成的差分序列,n为差分序列长度,0.99为滤波算子;满足所
述条件才判定为编号序列字段,如无符合条件字段则不输出。4.根据权利要求1所述的一种柴油机数据识别方法,其特征在于:所述s2具体包括:针对容量高于4g的导入数据的各列数据序列,采用指定模板大小为3
×
3,标准差为0.8的高斯滤波器完成各序列的平滑降噪。5.根据权利要求1所述的一种柴油机数据识别方法,其特征在于:所述s3具体包括:按照步骤s1内置的领域知识规则库进行数据的划分,所述的规则能够保证将要求转速、实际转速、要求齿杆作为训练样本a;将机油压力、进气压力、排气温度作为训练样本b;将进气温度、大气压力、水温、15v电压、24v电压作为训练样本c。6.根据权利要求1所述的一种柴油机数据识别方法,其特征在于:所述步骤s4的具体方法为:s41:确定特征集合,针对训练样本a的各列数据样本,每5000条数据序列作为1个单位时窗数据xa分别计算其最大值、最小值、平均值、信噪比、功率谱密度、一阶主频、均方根;上述7维特征形成1条训练样本,并将该数据序列列名作为其标签值;s42:根据所确定特征集合,针对训练样本b的各列数据样本,每5000条数据序列作为1个单位时窗数据xb分别计算其平均值、最大值、峰度、偏度、峭度、中位值、最小值、一阶差分;上述8维特征形成1条训练样本,并将该数据序列列名作为其标签值;s43:根据所确定特征集合,针对训练样本c的各列数据样本,每5000条数据序列作为1个单位时窗数据xc分别计算其平均值、标准差、中位值、一阶差分值、最小值;上述5维特征形成1条训练样本,并将该数据序列列名作为其标签值。
技术总结
本发明提供了一种柴油机数据识别方法,包括顺序进行的模型构建、模型应用两部分,模型构建包括:S1:基于领域的通识认知建立通识规则库、基于专家的领域知识建立规则库;S2:读取容量不低于4G且字段信息完整的数据表,将其高斯滤波后的数据作为训练样本;S3:结合专家知识规则库准则将训练样本分为A、B、C三类训练样本;S4:分别针对A、B、C三类训练样本进行特征提取,并对特征数据进行标签处理;S5:将特征数据与标签作为最终训练集导入随机森林分类器,分别得到A、B、C子分类器;模型应用部分主要应用上述步骤形成数据表格。本发明所述的柴油机数据识别方法,针对大功率增压柴油机实采数据具备较佳的数据识别匹配的准确性。备较佳的数据识别匹配的准确性。备较佳的数据识别匹配的准确性。
技术研发人员:智海峰 阴晋冠 褚全红 张春 李菲菲 关卓威 肖维 吕慧 张振宇
受保护的技术使用者:中国北方发动机研究所(天津)
技术研发日:2021.12.28
技术公布日:2022/5/10
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。