技术特征:
1.一种面向多智能体任务规划的复杂优化方法,其特征在于,所述多智能体任务规划基于马尔可夫决策和博弈论理论实现,包括多目标任务分配和多智能体路径规划;所述多目标任务分配采用双向竞标,即由智能体竞标目标任务和由目标任务竞标智能体的循环竞标策略;记所有智能体的状态量为全局状态量,所述多智能体路径规划是采用多智能体交互模块对所述全局状态量进行降维,降维后的状态量经动作决策,得到最优动作集合,即最优路径规划结果;其中,为第m个智能体在t时刻的状态量,,其任务规划结果是获得最优动作;所述多智能体交互模块包括依次连接的相关性排序单元和循环交互单元;所述相关性排序单元用于进行相关性排序,所述循环交互单元采用循环递推结构对所述相关性排序单元输出的状态量进行降维,所述循环交互单元的输出记为,与的拼接记为紧凑全局状态量;任意给定输入和,输出,所述智能体m循环交互单元的循环递推结构的表达式为:
ꢀꢀꢀ
(1)
ꢀꢀꢀ
(2)
ꢀꢀꢀꢀ
(3)其中,为逐元素的乘积,是sigmoid函数,分别为权值方阵,记为循环交互单元参数,i为所述循环交互单元的循环次数索引;所述多目标任务分配具体步骤包括:s11:环境建模以数字化地图构建所述多智能体任务规划的环境,描述环境中要素的坐标位置,所述要素至少包括智能体、目标点、障碍物,将智能体和目标点抽象为质点,环境中的障碍物抽象为几何区域;设智能体个数为m,目标任务个数为n,且m≥n;n记为目标任务的索引,所述多目标任务分配的总价值p最大化为约束条件;s12:智能体竞标目标任务选择总价值最大的方案x为智能体竞标目标任务的最优任务分配方案,x为矩阵,记为正向分配方案;
ꢀꢀ
(4)其中,v
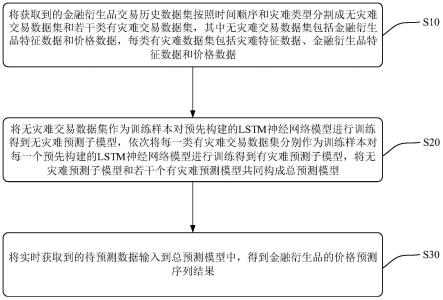
n
是目标任务n的执行收益,k
mn
为第m个智能体对目标任务n的匹配系数,q
mn
为智能体m对目标任务n成功完成的概率,其取值范围为[0,1],x
mn
代表竞标方案矩阵x的元素,定义为:
ꢀꢀ
(5)x
mn
=1时,表示智能体m执行目标任务n;x
mn
=0时,表示智能体m不执行目标任务n;s13:目标任务竞标智能体选择总价值最大化的方案y为目标任务竞标智能体的最优任务分配方案,记为反向分配方案;
ꢀꢀ
(6)其中,u
m
是智能体m对目标任务的执行收益,g
nm
为第n个目标任务对智能体m的匹配系数,q
nm
为目标任务n采用智能体m成功完成的概率,且q
nm
=q
mn
,y
nm
代表竞标方案矩阵y的元素,定义为:
ꢀꢀ
(7)y
mn
=1时,表示目标任务n选择智能体m执行任务;y
mn
=0时,表示目标任务n不采用智能体m执行任务;s14:将方案x和方案y的转置矩阵进行逐元素比对,若对应位置的元素取值相同,则取该位置对应的智能体和目标任务作为分配结果;若对应位置的元素取值不一致,则对方案x的不一致元素记录相应的值,对方案y的不一致元素记录相应的值;将所有记录的值按取值大小确定未分配智能体或目标任务的优先级,取值越大的对应的智能体与目标任务分配结果越优先被采纳,直至所有目标任务均分配了智能体;所述多智能体路径规划具体步骤包括:s21:初始化设置在t=0阶段,观测全局状态量;设定t的上限值;遍历所有智能体,完成所有智能体的初始化,具体方法是:
对于智能体m,采用随机初始化的方式,随机生成动作策略的参数,并设置的最优参数,随机生成评判策略的参数,并设置的最优参数;随机初始化循环交互单元的所有参数;s22:设置从第m=0个智能体开始,逐个智能体执行步骤s23-s29;s23:计算多智能体交互信息将多智能体的全局状态量输入相关性排序单元进行相关性排序,相关性排序单元的输出是除智能体m的状态量之外的,且经排序后的其他智能体的状态量,将相关性排序单元的输出按照大至小的顺序依次输入循环交互单元按照公式(1)-(3)进行迭代,得到循环交互单元输出;智能体m每完成一次任务规划,将其循环交互单元参数共享给下一个智能体m 1的循环交互单元,循环交互单元参数通过共享更新,即
ꢀꢀ
(8)式中,的取值范围为[0.05,0.5];s24:生成最优动作基于动作策略生成最优动作为:
ꢀꢀ
(9)其中,为随机噪声,表示参数为时的动作策略;s25:评估路径规划结果依据最优动作,智能体m完成一次任务规划,评估此时智能体和目标任务所产生的奖励,以及其下一时刻达到的状态;s26:获取多智能体路径规划参数优化的数据包存储t时刻的到由紧凑全局状态量、最优动作和奖励构成的任务规划历史数据库,采用随机取样方式,从历史数据库中抽取一批数据,构成多智能体路径规划参数优化数据包,数据包包含k组样本,k为样本索引,,第k组样本包括某一时刻的紧凑全局状态量、最优动作、奖励及其下一时刻的紧凑全局状态量;s27:根据k个样本逐一计算智能体m的总奖励期望的目标值
ꢀꢀ
(10)其中,表示以当前最优动作策略参数计算的最优动作,表示当前奖励的期望以最优的评价策略参数计算,,为相邻两次多智能体路径规划奖励的权重系数;s28:智能体m,动作策略、评判策略和循环交互单元参数通过最小化损失函数值l来优化
ꢀꢀꢀ
(11)其中,;则评判策略参数更新为,动作策略的参数更新为,更新为,;s29:更新智能体m的动作策略和评判策略的最优模型参数
ꢀꢀ
(12)其中,为更新权重,;所有智能体完成步骤s23-s29后,在t的上限值范围内,通过不断重复s22-s29,实现动作策略的最优模型参数的逐步优化,并以最终的为动作策略的最优动作,即最优路径规划结果。2.根据权利要求1所述的方法,其特征在于,所述相关性排序具体方法是:智能体m与其他的任一智能体l的相关性通过其状态量间的距离来度量,采用范数计算:
ꢀꢀ
(13)
其中,j表示状态量,的维度索引,p一般取1或2。
技术总结
本发明属于智能体任务规划优化技术领域,特别涉及一种面向多智能体任务规划的复杂优化方法。该方法基于马尔可夫决策和博弈论理论实现,包括多目标任务分配和多智能体路径规划;多目标任务分配采用双向竞标,即由智能体竞标目标任务和由目标任务竞标智能体的循环竞标策略;多智能体交互模块包括依次连接的相关性排序单元和循环交互单元;相关性排序单元用于进行相关性排序,循环交互单元采用循环递推结构对所述相关性排序单元输出的状态量进行降维,获得数据维度与智能体数量无关的交互信息。本发明能够在多对多任务规划的高维空间获得更优的局部最优解。获得更优的局部最优解。获得更优的局部最优解。
技术研发人员:江光德 陈豪 李冬雪 何浩东 魏国强 宫树香 马靖 杜林峰 刘庆国 伍樊成 魏庆栋 周颖 粱燕
受保护的技术使用者:中国人民解放军96901部队
技术研发日:2022.04.18
技术公布日:2022/7/29
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。