技术特征:
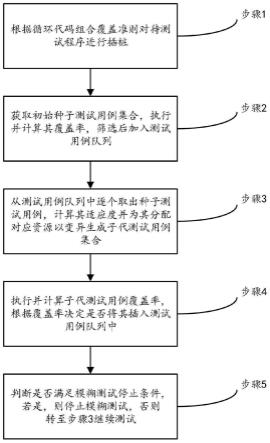
1.一种基于预训练模型与决策树的增量式论文同名作者消歧方法,其特征在于:包括以下步骤:s1,构建数据集,对作者名称、候选集id、论文id、论文信息进行数据预处理;s2,使用人工定义规则的方式提取不含语义信息字段的第一特征,使用xlnet预训练模型提取含有语义信息字段的第二特征,将第一特征和第二特征合并到一起得到所需特征向量;s3,将s2中得到的特征向量输入到xgboost中获取待分配论文属于该候选集的概率,并据此判断是否将待分配论文分配给该候选集;s4、构建基于凝聚式层次聚类的增量消岐后处理框架,对增量s3中未能分配出去的论文进行后处理操作。2.根据权利要求1所述的一种基于预训练模型与决策树的增量式论文同名作者消歧方法,其特征在于:所述第一特征至少包括作者名称、机构,所述第二特征至少包括论文标题、摘要。3.根据权利要求1所述的一种基于预训练模型与决策树的增量式论文同名作者消歧方法,其特征在于:s2具体包括:2.1,比较待分配论文与候选集中所有论文之间的作者信息,各值表示如下:count
a
:同名作者的数量,每次出现同名作者时都会令该值 1,当一个作者名重复出现时同样会对该值进行 1操作;count
oa
:同名且同组织作者的数量,每次出现同名且同组织作者时都会令该值 1,当一个同名且同组织作者重复出现时同样会对该值进行 1操作;r
a
:同名作者数量与候选集中论文数量的比值,即r
oa
:同名且同组织作者与候选集中论文数量的比值,即count
ca
:共同作者的数量,每次出现共同作者时都会令该值 1,当一个作者重复出现时,不再对该值进行操作;r
ca
:共同作者的数量与待分配论文中作者数量的比值,即t
ca
:共同作者在这个候选集c
k
中一共出现的次数;共同作者出现次数与该候选集c
k
中作者总数t
a
的比值,即在完成比较后将这些值排列在一起组成一个向量一,所述向量一为提取出的作者名称相关特征;2.2,比较待分配论文与候选集中所有论文之间的作者机构信息,各值表示如下:count
org
:待分配论文p
a
与候选集c
k
中所有相同机构的数量;r
org
:相同机构数量与所有机构数量count
aorg
之间的比值,即之间的比值,即jaccard
max
:分词合并处理后,待分配论文p
a
与候选集c
k
中所有论文之间的jaccard相似
系数的最大值,即jaccard
mean
:分词合并处理后,待分配论文p
a
与候选集c
k
中所有论文之间的jaccard相似系数的均值,即jaccard
pooling
:分词合并处理后,经过高斯核函数处理后的jaccard相似系数,为一个n维向量,其中n表示输入的中心点数量;r
′
max
:分词合并处理后,待分配论文p
a
与候选集c
k
中所有论文之间相同机构数与所有机构数比值的最大值,即r
′
mean
:分词合并处理后,待分配论文p
a
与候选集c
k
中所有论文之间相同机构数与所有机构数比值的平均值r
′
pooling
:分词合并处理后,经过高斯核函数处理后的相同机构数与所有机构数的比值,为一个n维向量,其中n表示输入的中心点数量;在完成比较后将这些值排列在一起组成一个向量二,所述向量二为提取出的作者机构相关特征;2.3,比较待分配论文与候选集中所有论文之间的标题信息,各值表示如下:count
title
:分词合并过程后,相同词在待分配论p
a
文中出现的次数;count
′
title
:分词合并过程后,相同词在候选集c
k
的所有论文中出现的次数;r
title
′
:分词合并过程后,相同词在待分配论文p
a
中出现的次数与待分配论文p
a
中所有词总数的比值,即r
′
title
′
:分词合并过程后,相同词在候选集c
k
的所有论文中出现的次数与候选集c
k
中所有词总数的比值,即jaccard
pooling
:分词合并过程后,经过高斯核函数处理后的jaccard相似系数,为一个n维向量,其中n表示输入的中心点数量;cos
pooling
:使用xlnet提取论文的标题特征,之后计算待分配论文p
a
的标题与候选集c
k
中每一篇论文标题的余弦相似度,之后通过高斯核函数处理得到cos
pooling
;在完成比较后将这些值排列在一起组成一个向量三,所述向量三为提取出的论文标题的非语义特征;2.4,对含有语义信息的论文字段使用xlnet预训练模型提取语义特征;2.5,将2.1、2.2、2.3得到的向量一、向量二、同量三及2.4提取的语义特征组合到一起得到最终的特征向量。4.根据权利要求1所述的一种基于预训练模型与决策树的增量式论文同名作者消歧方法,其特征在于:s3具体包括:3.1,将步骤2得到的特征输入到xgboost决策树中,确定待分配论文是分配给相应作者
还是不进行分配;假设与当前待分配论文相对应的候选集共有i篇,那么通过步骤2中会得到i个特征向量,将这些特征向量输入到xgboost中,能够得到对应的i个得分score,0<score<1,将概率最高的那个候选集记作最可能的候选集,最高得分记作score_max;3.2,对于较为简单的情况使用阈值进行判断,一般阈值选取0.9;加入score_max≥0.9,那么将待分配论文分配给score_max对应的候选集,否则将该待分配论文记作未分配论文,在对所有待分配论文进行操作后,将所有未分配论文进行汇总,并将该集合记作未分配论文集;3.3,将每个未分配论文看作一个簇,使用步骤2中的方法,将这些簇进行两两比较,能够得到若干个特征向量;3.4,将3.3中得到的特征向量输入到xgboost或者训练好的mlp中进行概率预测,将概率最高的两个簇看作最近的两个簇,将这两个簇合并到一起,当最大簇中的论文数量大于5时,认为这是主聚簇,停止层次聚类;3.5,将未分配候选集中剩余的论文向3.4中得到的主聚簇进行3.1和3.2中提到的增量消岐操作,分配失败的返回未分配候选集,成功的直接加入主聚簇,将最终增量后的主聚簇作为一个新的候选集,此时完成一整轮增量消岐操作。
技术总结
本发明公开了基于预训练模型与决策树的增量式论文同名作者消歧方法,属于神经网络与作者同名消歧技术领域,所述方法利用人工定义特征与XLNet提取特征相结合的特征提取,首先使用人工定义特征提取论文中作者名称、机构等字段的信息,使用XLNet提取论文标题、摘要等字段的信息,之后利用XGBoost与提取出的特征来预测每篇论文应该归属的正确作者,对于该步未能分配出的论文进行凝聚式聚类的后处理,获取主聚类作为新的作者论文集,预测结果使用准确率、召回率以及F1值。本发明能够对论文的信息进行更加充分地提取,具有较强的可解释性,具有较强的鲁棒性,在处理噪点较多以及论文信息较为齐全的数据上有较优秀的表现。较为齐全的数据上有较优秀的表现。较为齐全的数据上有较优秀的表现。
技术研发人员:宫继兵 郑嘉壮 房小涵 寇肖萌 赵祎 丛方鹏
受保护的技术使用者:燕山大学
技术研发日:2022.07.29
技术公布日:2022/11/11
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。