技术特征:
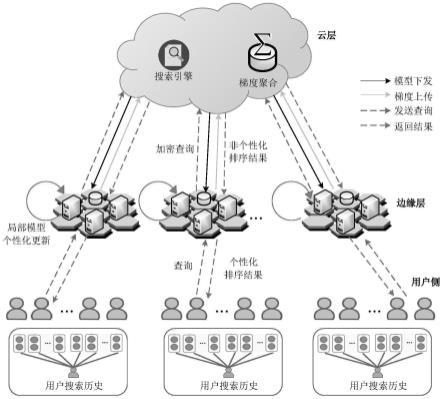
1.一种个性化数据服务方法,其特征在于,该方法具体包括以下步骤:s1:区域划分:每个边缘服务器根据其范围覆盖能力划分负责管理的区域,对区域内的用户和物理实体进行管理;s2:数据收集:边缘服务器收集并存储所管辖区域内用户的历史搜索请求记录及评价反馈数据;s3:模型构建:构建个人-全局级语义增强的个性化搜索模型,包括:以用户历史搜索请求记录及评价反馈数据作为transformer模型输入,获得输入数据中蕴含的三种隐含特征:个人级语义消歧查询特征q
p
、个人级用户兴趣偏好特征p和全局级实体表示e
u
;利用三种隐含特征获得语义增强后的当前查询并通过余弦相似度计算当前查询与实体e的个性化匹配分数从而实现个性化结果排序;s4:联合推理:边缘服务器与云服务器构成基于联邦学习的边云协同模型进行模型联合推理,通过边云协同的联合推理将个性化搜索模型部署在所有边缘服务器中;s5:发起搜索:用户通过所持客户端设备向边缘服务器发起对实体状态数据的搜索请求;s6:搜索响应:边缘服务器或云服务器筛选出相关的匹配实体结果,边缘服务器并经过存储的个性化搜索模型对反馈结果进行个性化的重新排序,再返回至管理区域内的用户。2.根据权利要求1所述的个性化数据服务方法,其特征在于,步骤s3中,所述transformer模型由多个多头注意力机制及位置前馈网络组成,表示为:transformer(x)=ln(m
x
d(pf(m
x
)))其中,m
x
=ln(x d(ms(x))),ln(
·
)是对输出数据的批量归一化层,d(
·
)是为了防止模型过拟合的dropout层;模型中多头注意力机制ms(x)表示为ms(x)=[head1,...,head
i
,...,head
h
]w
o
,其中每个头head
i
=att(xw
iq
,xw
ik
,xw
iv
),注意力为x表示模型的数据输入,w
o
,w
iq
,w
ik
,w
iv
表示模型中需要更新的参数;q,k,v为transformer中三个重要的信息,分别表示为数据输入向量,被关注的信息与其他信息的相关性的向量,被关注的信息的向量;位置前馈网络表示为pf(x)=c2(relu(c1(x
t
)))
t
,其中c2(
·
),c1(
·
)为两个具有不同参数的卷积操作,x
t
表示输入数据向量的转置操作,relu(
·
)为非线性激活函数。3.根据权利要求2所述的个性化数据服务方法,其特征在于,步骤s3中,构建的个人-全局级语义增强的个性化搜索模型具体包括以下步骤:s31:利用transformer模型完成个人级查询消歧,具体包括:将输入数据x替换为包含当前时刻查询q
t
的查询序列q={q1,q2,...,q
t
,...,q
t-1,q
t
},获取个人级语义消歧查询特征征表示查询序列中每个查询单词的位置嵌入;利用transformer模型完成个人级兴趣偏好挖掘,具体包括:将输入数据x替换为用户历史搜索记录h={h1,h2,...,h
t
,...,h
t-1
},h
t
={q
t
,r
t
},r={r1,r2,...,r
t
,...,r
t-1
}为用户每个历史搜索请求对应的评价反馈,表示用户服务体验;获取个人级用户兴趣偏好特征p=transformer(h h
p
),h
p
表示历史搜索记录中每个由搜索请求与对应的评价反馈组成的记录元组的位置嵌入;
利用transformer模型完成全局级实体表示,将输入数据x替换为所有用户对一个实体的评价反馈r={r1,r2,...,r
u
,...,r
u
},获取全局级实体表示e
u
,e
u
=transformer(r r
p
),r
p
表示所有用户对一个实体的所有评价反馈对应的位置嵌入;s32:利用步骤s31获取的三种隐含特征q
p
、p、e
u
增强当前查询q
t
,获得的语义增强后的当前查询表示为mlp(
·
)表示多层感知机模型,负责将这几种特征向量融合在一起;s33:通过余弦相似度计算用户增强的当前查询与实体e的个性化匹配分数从而完成个性化搜索构建以实现个性化结果排序,表示为:4.根据权利要求3所述的个性化数据服务方法,其特征在于,步骤s4具体包括以下步骤:s41:边云协同模型的联合推理需要对个性化搜索模型进行多轮迭代更新,在每轮训练过程中,每个边缘服务器在本地完成每轮模型训练;边缘服务器本地训练:具体过程表示为m
t
为t时刻训练轮次中边缘服务器所拥有的个性化搜索模型参数,x为步骤s3中三种隐含特征提取所需要的输入数据,sgd(
·
)表示模型迭代更新采用的随机梯度下降法,表示第k个边缘服务器在t 1时刻训练好的个性化搜索模型参数;s42:边缘服务器参数上传:每个边缘服务器将更新的模型参数上传至云服务器;s43:云服务器参数聚合:在每轮联合推理中,云服务器对接收到的每个边缘服务器上传的模型参数与上一轮的模型参数m
t
聚合,t 1时刻聚合的模型参数表示为k为边缘服务器总数量;s44:云服务器参数下发:云服务器将新一轮聚合的模型参数m
t 1
发送给每个边缘服务器;s45:边云协同联合推理:在联合推理及训练模型中,损失函数loss定义为:其中,表示搜索请求与目标实体的相关性得分,表示搜索请求与其他候选实体的相关性得分,而联合推理的优化目标是使得目标函数最小:其中θ
k
表示第k个边缘服务器中个性化模型的所有参数;s46:模型获取:重复步骤s41-s44直至使得步骤s45中目标函数达到最小并趋于稳定,此时每个边缘服务器都能获得最优的个性化搜索模型。5.根据权利要求4所述的个性化数据服务方法,其特征在于,步骤s6具体包括以下步骤:s61:边缘服务器判断用户所需实体状态数据的缓存位置,如果所需实体状态数据缓存在边缘服务器,则边缘服务器基于传统检索匹配方法执行检索,筛选出相关实体结果后再
运行训练好的个性化搜索模型,对实体结果进行个性化的重新排序,使用户最满意的实体结果出现在排序列表最前面,最后将个性化实体结果列表反馈至用户;s62:如果所需实体状态数据没有缓存在边缘服务器,则边缘服务器将搜索请求加密后上传至云服务器;云服务器基于对称可搜索加密机制执行密文环境下一般的搜索请求与实体相关性匹配,然后将加密的实体结果列表反馈至相应的边缘服务器,边缘服务器对实体结果列表解密后再运行训练好的个性化搜索模型,对实体结果进行个性化的重新排序,同样能为用户返回个性化的排序结果。
技术总结
本发明涉及一种个性化数据服务方法,属于物联网领域。该方法包括:区域划分;数据收集:边缘服务器收集并存储所管辖区域内用户的历史搜索请求及评价反馈数据;模型构建:以用户历史搜索请求记录作为数据输入,构建个人-全局级语义增强的个性化搜索模型;联合推理:边缘与云服务器协同构建联邦学习框架以联合协作训练个性化搜索模型,将训练好的模型发送给各边缘服务器存储;发起搜索:用户通过所持客户端设备向边缘服务器发起搜索请求;搜索响应:边缘服务器执行搜索过程并匹配若干相关实体,然后调用个性化搜索模型对若干实体进行结果重排序后返回至用户。本发明可有效提高面向用户的数据服务精度,为用户提供个性化且高质量搜索服务体验。量搜索服务体验。量搜索服务体验。
技术研发人员:吴大鹏 孙美玉 王汝言 杨志刚 张普宁
受保护的技术使用者:重庆邮电大学
技术研发日:2022.08.24
技术公布日:2022/11/25
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。