技术特征:
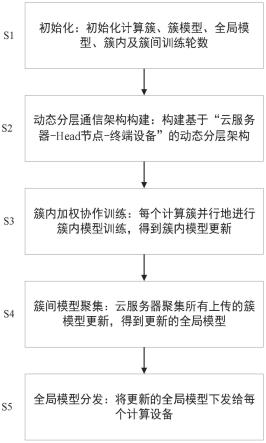
1.一种基于响应时间实时均衡的联邦学习高效通信方法,其特征在于:该方法包括以下步骤:s1:初始化,定义为设备集合,n为设备个数,和分别为所有设备所采集的本地隐私数据和计算能力集合,和分别为簇以及簇的head节点集合,m为簇个数,云服务器初始化全局模型ω0,全局模型训练轮数t,簇内模型训练轮数h;s2:动态分层通信架构构建,根据给定的设备计算能力以及设备的数据集合动态的将终端设备划分至给定的计算簇中,使得每个计算簇在当前迭代轮次h∈h的簇模型训练时间均衡,并构建基于“云服务器-head节点-终端设备”的动态分层通信架构;s3:簇内加权协作训练,每个簇的head的节点分别进行簇内加权协作训练,得到每个簇在当前迭代轮次h∈h的簇内模型更新s4:簇间模型聚集,每个计算簇的head节点分别将获得的簇模型更新上传至云服务器,云服务器对上传的簇模型更新进行聚集操作,得到下一轮迭代的全局模型ω
t 1
;s5:全局模型分发,云服务器将更新的全局模型ω
t 1
下发给所有计算设备,模型训练进入下一轮迭代。2.根据权利要求1所述的一种基于响应时间实时均衡的联邦学习高效通信方法,其特征在于:所述s2具体包括以下步骤:s2-1:所有终端设备从云服务器获取迭代轮次t∈t的全局模型ω
t
(t=0,1,2,...,t);s2-2:所有终端设备根据各自的本地隐私数据以及全局模型ω
t
并行地进行本地模型训练,对于设备有如下计算公式:其中,e∈e为终端设备的本地模型训练轮次,和为终端设备在本地迭代轮次e和e-1的本地模型更新,b∈b为训练块大小,η和分别为学习率和梯度函数;s2-3:记簇内迭代训练轮次h∈h,得到经过e轮本地模型训练的终端设备集合为s且s中每个设备的本地模型更新为则分别预测评估将设备划分至每个簇的簇模型训练时间对于设备有如下计算公式:s2-4:将设备分配至使得簇间训练时间差异最小的簇中,对于簇有如
下计算公式:s2-5:更新每个簇的簇模型训练时间重复s2-3至s2-5,直至集合s中所有设备划分完成为止,得到当前迭代轮数h∈h的一次簇划分结果;s2-6,在每个簇中,选择一个计算能力最强的设备作为簇的head节点,并构建基于“云服务器-head节点-终端设备”一体的逻辑分层架构。3.根据权利要求2所述的一种基于响应时间实时均衡的联邦学习高效通信方法,其特征在于:所述s3具体包括以下步骤:s3-1:分别统计每个设备直至迭代轮次h∈h,训练得到本地模型更新的总频次s3-2:分别计算每个设备在当前迭代轮次h∈h的簇内模型聚集权重其计算公式如下:s3-3:计算每个簇在当前迭代轮次h∈h的簇内模型更新,对于簇其计算公式如下:其中,表示簇在簇内迭代轮次(h-1)的簇模型更新;不断重复s2~s3,直至每个簇迭代训练h轮为止,得到经过h轮迭代训练的簇模型更新4.根据权利要求3所述的一种基于响应时间实时均衡的联邦学习高效通信方法,其特征在于:所述s4具体包括以下步骤:s4-1,每个计算簇的head节点将训练得到的簇模型更新传输至云服务器;s4-2,云服务器对所有上传的簇模型更新进行聚集操作,并得到下一轮迭代的全局模型ω
t 1
,其计算公式如下:其中,ω
t
为第t轮迭代的全局模型。5.根据权利要求4所述的一种基于响应时间实时均衡的联邦学习高效通信方法,其特征在于:所述s5具体包括以下步骤:
s5-1,清空簇集合簇的head节点集合每个簇的簇模型训练时间以及经过h轮迭代训练的簇模型更新每个设备直至迭代轮次h∈h,训练得到本地模型更新的总频次簇内模型聚集权重s5-2,云服务器将更新的全局模型ω
t 1
下发给所有计算设备,模型训练进入下一轮迭代;不断重复s2~s5,直至t轮全局模型训练迭代为止,全局模型训练结束,得到收敛后的全局模型ω
t
。6.一种基于响应时间实时均衡的联邦学习高效通信系统,其特征在于:该系统包括以下模块:初始化模块,用于初始化簇集合簇head节点集合全局模型ω0,全局模型训练轮数t,簇内模型训练轮数h,每个簇的簇模型训练时间每个设备在迭代轮次h∈h的累计通信频率以及簇内模型聚集权重动态分层通信架构构建模块,用于将资源异构的计算设备集合根据其设备每轮迭代训练的本地模型训练时间,进行动态分组,并构建基于“云服务器-head节点-终端设备”的动态分层通信架构,包含以下子模块:全局模型获取子模块,用于所有终端设备从云服务器获取的当前迭代轮次t∈t的全局模型ω
t
(t=0,1,2,...,t);并行训练子模块,用于所有终端设备并行地根据其本地隐私数据以及全局模型ω
t
进行本地模型训练;本地模型存储子模块,用于存储簇内迭代训练轮次h∈h,经过e轮本地模型训练的终端设备集合为s以及s中每个设备的本地模型更新簇模型训练时间评估子模块,用于评估集合s中每个设备划分至每个簇的簇模型训练时间簇间训练时间评估子模块,用于评估将设备分配至每个簇所得到的簇间训练时间差异设备划分子模块,用于将设备分配至簇间训练时间差异φ
j
最小的簇中;中间变量更新子模块,用于更新每个簇在当前迭代轮次h∈h的簇模型训练时间循环子模块,用于循环执行设备划分子模块,直至集合s中的所有设备划分完成为止;head节点选取子模块,用于从每个簇中,选取一个当前计算能力最强的设备作为簇的head节点,构建基于“云服务器-head节点-终端设备”一体的逻辑分层架构;
簇内加权协作训练模块,用于每个簇的head节点分别进行簇内加权协作训练,得到每个簇在当前迭代轮次h∈h的簇模型更新包含以下子模块:设备通信频率计算子模块,用于统计每个计算设备在迭代轮次h∈h的累计通信频次簇内模型更新权重计算子模块,用于计算每个计算设备在当前迭代轮次h∈h的簇内模型聚集权重簇内模型更新子模块,用于计算每个簇在当前迭代轮次h∈h的簇内模型更新簇内模型参数分发子模块,用于将计算得到的簇模型更新分发给已经空闲的终端设备;迭代训练模块,用于不断重复动态分层通信架构构建模块以及簇内加权协作训练模块,直至每个簇迭代训练h轮为止,得到经过h轮迭代训练的簇模型更新簇间模型聚集模块,用于每个簇的head节点分别将获得的簇模型更新上传至云服务器,云服务器对上传的簇模型进行聚集操作,得到下一轮迭代的全局模型ω
t 1
,包括以下子模块:簇内模型更新传输子模块,用于每个计算簇的head节点将训练得到的簇模型更新传输至云服务器;全局模型聚集子模块,用于云服务器对所有上传的簇模型更新进行聚集操作,并得到下一轮迭代的全局模型ω
t 1
;全局模型分发模块,用于云服务器将更新的全局模型ω
t 1
下发给所有计算设备,模型训练进入下一轮迭代,包括以下子模块:参数重置模块,用于清空上一轮全局模型迭代划分得到的簇集合簇的head节点集合重置簇模型训练时间以及簇模型更新每个设备的累计通信总频次以及簇内模型聚集权重全局模型下发子模块,云服务器下发全局模型ω
t 1
给所有的终端设备;全局模型迭代训练子模块,用于不断重复动态分层通信架构构建模块、簇内加权协作训练模块、簇间模型聚集模块以及全局模型分发模块,直至得到收敛的全局模型ω
t
,全局模型训练结束。
技术总结
本发明涉及一种基于响应时间实时均衡的联邦学习高效通信方法,属于联邦机器学习领域。首先,在预先设定的簇迭代训练中,每个响应的终端设备分别根据自身的本地模型计算时间,均衡的划分至预先设定的计算簇中,构建基于“云服务器-Head节点-终端设备”一体的分层通信架构,从通信结构上间接增加了低响应设备的模型训练参与度。然后,使响应快的设备能够帮助响应慢的设备进行训练。本发明通过对异构的计算设备动态分组,自适应构建分层的逻辑通信架构,并在计算簇内设计加权的协作训练机制,间接提高了低响应设备的模型训练参与度,从本质上解决了联邦机器学习技术中,由于资源异构所导致的通信等待延时问题,提高了训练模型的精确度。精确度。精确度。
技术研发人员:李开菊 王豪 张清华 夏英 张旭
受保护的技术使用者:重庆邮电大学
技术研发日:2022.08.15
技术公布日:2022/11/25
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。