技术特征:
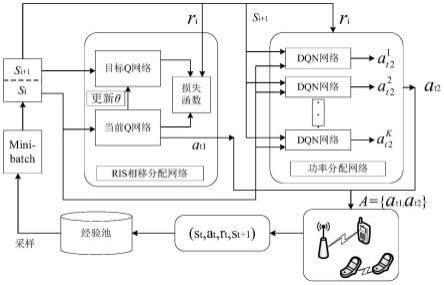
1.一种基于多智能体dqn的irs辅助d2d系统资源分配方法,其特征在于,步骤如下:步骤1,设置基站、irs、蜂窝用户、k对d2d用户和能量接收机(energy harvesting receiver,ehr)的位置;对蜂窝用户到bs、irs、接收用户(d2d receiver,dr)、ehr的信道,发射用户(d2d transmitter,dt)到dr、irs、bs、ehr的信道,irs到bs、dr、ehr的信道进行建模并得到信道增益;步骤2,根据步骤1中的信道增益,构建蜂窝用户最大传输速率问题;步骤2.1,蜂窝用户向基站发送的信号的最大传输速率可以表示为r
c
;步骤2.2,系统目标是在满足d2d用户最小传输速率、ehr最低能量采集约束条件下,针对irs相移矩阵、dt发射功率进行优化,构建蜂窝用户最大传输速率问题;步骤3,根据系统中的irs相移矩阵,dt发射功率分配,d2d用户最小传输速率,ehr能量采集,分别对深度强化学习的三大要素:状态、动作及奖励进行定义与设计;步骤4,利用多智能体dqn算法优化强化学习网络模型。并根据优化后的网络模型获得蜂窝用户最大传输速率。2.根据权利要求1所述的一种基于多智能体dqn的irs辅助d2d系统资源分配方法,其特征在于:步骤1中所述信道增益具体包括:使用准静态平坦衰落信道模型,所有的信道增益为理想信道状态信息(channel state information,csi)模式,其中,蜂窝用户到bs、irs、dr、ehr的信道增益分别为information,csi)模式,其中,蜂窝用户到bs、irs、dr、ehr的信道增益分别为dt到dr、irs、bs、ehr的信道增益分别为dt到dr、irs、bs、ehr的信道增益分别为irs到bs、dr、ehr的信道增益分别为3.根据权利要求1所述的一种基于多智能体dqn的irs辅助d2d系统资源分配方法,其特征在于:步骤2.1中所述蜂窝用户传输速率问题具体包括:在上行链路中,基站接收到的信号为蜂窝用户的传输信号、irs的反射信号和复用蜂窝用户频谱的d2d用户产生的同频干扰信号。因此,蜂窝用户传输速率可以表示为:其中,p
c
、分别为蜂窝用户和第i个dt的发射功率,θ为irs相移矩阵,满足主对角线θ
n
=(0,2π)表示第n(1≤n≤n)个反射元素的相移,σ2代表噪声。4.根据权利要求1所述的一种基于多智能体dqn的irs辅助d2d系统资源分配方法,其特征在于:步骤2.2中所述构建蜂窝用户最大传输速率问题具体包括:每个d2d用户的信息传输速率可以表示为:
ehr采集的能量表示为:其中,η为能量转换效率。因此,蜂窝用户最大化传输速率的问题可以建模为::s.t.c1:r
id
≥r
min
,c2:|v
n
|=1,c3:e≥e
min
c4:其中,c1是d2d用户传输速率约束,r
min
为d2d用户可以正常通信的最小传输速率;c2是irs恒模约束;c3是能量采集约束,e
min
为ehr最低能量采集限制;c4是dt发射功率约束,p
max
为dt最大发射功率。5.根据权利要求1所述的一种基于多智能体dqn的irs辅助d2d系统资源分配方法,其特征在于:步骤3中所述状态、动作及奖励的定义与设计具体包括:状态:dqn网络需要根据当前所处状态选择最佳的动作,以此来获得更多的奖励,从而能够在保证在满足d2d用户最小传输速率条件下最大化蜂窝用户的传输速率。针对这一目标,状态空间s被定义为d2d用户的sinr,因此,在t时刻智能体所处的状态为:其中,sinr
i
(t)为第i个智能体在t时刻的信干噪比,即传输速率。动作:dqn算法中,每输入一个状态,dqn网络会根据ε-greedy策略来选择一个动作,agent执行这个动作获得一个奖励值并到达下一个状态。ε-greedy策略表示为:其中,0<ε<1。针对本章所提irs辅助d2d通信系统,动作空间a应包含所有的功率选择和irs相移选择。因此,t时刻的动作a
t
定义为:其中,其中,a1和a2分别表示d2d用户功率分配空间和irs反射元素相移选择空间。奖励函数:本模型采用蜂窝用户的速率作为瞬时奖励,考虑d2d用户的最低传输速率约束,奖励值r
t
定义为:
则长期累积的奖励值为:其中,γ∈[0,1]为折扣因子,表示agent对未来奖励的关注程度。当γ=0时,agent只关注当前时刻的奖励值,γ越大,则表示agent越关注未来的奖励,这种远视能力通常有助于agent更加明智的选择动作。6.根据权利要求1所述的一种基于多智能体dqn的irs辅助d2d系统资源分配方法,其特征在于:步骤4中所述利用多智能体dqn算法优化强化学习网络模型具体包括:整个算法由在线决策和离线训练两部分组成:在线决策阶段,首先初始化当前环境,得到初始状态s
t
,根据ε-greedy(0<ε<1)策略选择一个动作,然后计算奖励值并到达下一个状态s
t 1
,然后将(s
t
,a
t
,r
t
,s
t 1
)作为数据样本存入经验池中。离线训练阶段,从经验池中随机抽取一批数据,根据以下定义计算出真实的q值:y
t
=r
t
γmaxq(s
t 1
,a
t 1
;θ)其中,θ为网络中的参数,通过训练当前值网路,更新参数θ,让网络预测的q值无接近真实的q值,因此,损失函数表示为:ψ(t)=(y
t-q(s
t
,a
t
;θ))2本算法中,采用adam优化器最小化损失函数,然后反向传播更新网络中的参数。训练一段时间后,将当前值网络中的权值参数复制到目标值网络。
技术总结
本发明公开了一个智能反射面(IRS)辅助设备到设备(D2D)通信中复用上行链路频谱资源的场景,提出一种基于多智能体DQN的IRS辅助D2D系统资源分配方法,用以提升蜂窝用户最大传输速率。本发明通过满足D2D用户最小传输速率和能量接收机最低能量采集的约束,联合优化D2D用户发射功率和IRS相移,构建最大化蜂窝用户信息传输速率模型。提出一种多智能体DQN资源分配算法,每个DQN网络只负责一个agent的学习并输出D2D功率和IRS相移。仿真结果表明,与其他方法相比,所提出的资源分配算法可以从环境中学习并不断改善行为,在较低的复杂度下显著提高蜂窝用户最大传输速率,同时拥有良好的收敛效果。敛效果。敛效果。
技术研发人员:朱政宇 巩梦飞 赵航冉 宁梦珂 王宏旭 梁静 宋灿 孙钢灿 郝万明 侯庚旺 李铮
受保护的技术使用者:郑州大学
技术研发日:2022.07.22
技术公布日:2022/11/29
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。