技术特征:
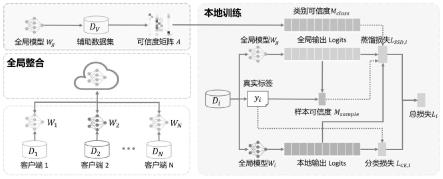
1.一种基于自适应调整权重的数据隐私保护方法,其特征在于,包括:步骤1、将已标注类别标签的辅助数据集输入全局模型,得到该全局模型在每类数据上的分类精度,作为类别可信度矩阵;步骤2、至少一个客户端从云端获取该全局模型,该客户端初始化其本地模型,该客户端本地具有本地私有数据集,该本地私有数据集中样本对应有类别标签;将该本地私有数据集,输入该本地模型,得到本地模型的输出,以及分类损失;并将该本地私有数据集输入位于该客户端本地的该全局模型,得到该全局模型的输出,以及该本地私有数据中每个样本的分类精度,作为样本可信度矩阵;根据该样本可信度矩阵和该类别可信度矩阵,得到蒸馏损失;根据由该分类损失和该蒸馏损失构成的总损失,训练该本地模型;将训练完成的该本地模型的模型参数上传到该云端;步骤3、该云端通过对收到的模型参数进行加权聚合,得到新模型。2.如权利要求1所述的基于自适应调整权重的数据隐私保护方法,其特征在于,该步骤3包括:以该新模型替换该全局模型,循环执行该步骤1到3,直到该总损失收敛或达到预设迭代次数,全局模型训练更新结束,保存当前的全局模型作为最终模型,并对指定数据进行分类或预测。3.如权利要求1所述的基于自适应调整权重的数据隐私保护方法,其特征在于,该蒸馏损失其中是类别的权重向量,
⊙
表示元素相乘;z
g
为全局模型的输出,z为本地模型的输出;权重向量m中k1位置的值为:m(x)[k1]=m
max
·
[m
class
[k1]m
sample
(x)-0.1]
,m
sample
(x)=1-(1-p
g
(x)[k2])
0.5
;其中样本x属于类别k2,a
k1,k1
是类别k1的召回率,a
k,k1
表示类别k误预测为类别k2的概率;p
g
(x)[k2]表示该全局模型正确预测样本x的类别为k2的概率,m
max
为蒸馏损失项的上限值。4.如权利要求1所述的基于自适应调整权重的数据隐私保护方法,其特征在于,该客户端为医疗机构数据中心或金融机构数据中心,该新模型用于对输入图像进行分类或对交易数据进行风险预测。5.一种基于自适应调整权重的数据隐私保护系统,其特征在于,包括:云端,用于将已标注类别标签的辅助数据集输入全局模型,得到该全局模型在每类数据上的分类精度,作为类别可信度矩阵;通过对收到的模型参数进行加权聚合,得到新模型;至少一个客户端,从该云端获取该全局模型,该客户端初始化其本地模型,该客户端本地具有本地私有数据集,该本地私有数据集中样本对应有类别标签;将该本地私有数据集,输入该本地模型,得到本地模型的输出,以及分类损失;并将该本地私有数据集输入位于该客户端本地的该全局模型,得到该全局模型的输出,以及该本地私有数据中每个样本的分类精度,作为样本可信度矩阵;根据该样本可信度矩阵和该类别可信度矩阵,得到蒸馏损
失;根据由该分类损失和该蒸馏损失构成的总损失,训练该本地模型;将训练完成的该本地模型的模型参数上传到该云端。6.如权利要求5所述的基于自适应调整权重的数据隐私保护系统,其特征在于,该云端用于:以该新模型替换该全局模型,保存当前的全局模型作为最终模型,并对指定数据进行分类或预测。7.如权利要求5所述的基于自适应调整权重的数据隐私保护系统,其特征在于,该蒸馏损失其中是类别的权重向量,
⊙
表示元素相乘;z
g
为全局模型的输出,z为本地模型的输出;权重向量m中k1位置的值为:m(x)[k1]=m
max
·
[m
class
[k1]m
sample
(x)-0.1]
,m
sample
(x)=1-(1-p
g
(x)[k2])
0.5
;其中样本x属于类别k2,a
k1,k1
是类别k1的召回率,a
k,k1
表示类别k误预测为类别k2的概率;p
g
(x)[k2]表示该全局模型正确预测样本x的类别为k2的概率,m
max
为蒸馏损失项的上限值。8.如权利要求5所述的基于自适应调整权重的数据隐私保护系统,其特征在于,该客户端为医疗机构数据中心或金融机构数据中心,该新模型用于对输入图像进行分类或对交易数据进行风险预测。9.一种存储介质,用于存储执行如权利要求1到4所述任意一种基于自适应调整权重的数据隐私保护方法的程序。10.一种客户端,用于权利要求5至8中任意一种基于自适应调整权重的数据隐私保护系统。
技术总结
本发明提出一种基于自适应调整权重的数据隐私保护方法和系统,解决了面向非独立同分布数据带来的模型性能下降和收敛速度变慢的问题,属于联邦学习应用技术领域。包括:在每一轮联邦通信开始时,服务器端利用辅助数据集评估全局模型类别层面的可信度,将可信度矩阵和全局模型参数下发到参与该轮联邦的客户端中;客户端根据本地私有数据集评估全局模型样本层面的可信度,进行知识蒸馏时利用类别可信度和样本可信度进行加权,动态指导本地模型的训练过程,并上传更新后的本地模型参数至服务器端;服务器端加权聚合各本地模型参数更新全局模型。模型。模型。
技术研发人员:陈益强 何雨婷 杨晓东 于汉超
受保护的技术使用者:中国科学院计算技术研究所
技术研发日:2022.07.06
技术公布日:2022/12/19
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。