一种基于动量对比学习的声纹识别方法和设备
- 国知局
- 2024-06-21 10:41:58
本发明涉及声纹识别领域,具体涉及一种基于动量对比学习的声纹识别方法和设备。
背景技术:
1、随着数字化时代的到来,身份识别与认证越来越成为日常生活中不可或缺的一项技术,常用的技术主要有密钥认证、人脸认证、虹膜认证、指纹认证;声纹认证一直是一项不太成熟的技术,目前市面上并没有成熟的开源或闭源的声纹识别认证技术。
2、声纹识别技术的背景可以追溯到上世纪60年代,当时研究人员开始尝试使用声音特征来识别说话人。这项技术的关键在于人类的声音特征是独一无二的,即使对同一段话,不同的人的发音也会有所不同。
3、理论层面,声纹识别与认证主要有两种方法。一是基于特征提取的方法:这种方法首先需要从声音信号中提取出一些特征,比如声音的频谱、声道长度、共振峰等。然后使用这些特征组合构造一个类似于人体音色的具有各异性的的变量进行比对,从而识别区分不同个体的声纹;二是基于神经网络的方法:近年来,随着深度学习技术的发展,神经网络已经应用到了nlp、cv等各个方面,也出现了很多基于神经网络的说话人识别模型,这些模型通常会将声音信号输入神经网络,通过学习提取出高层次的特征来进行识别。
4、实际应用层面,声纹识别技术得到了广泛应用。在金融机构、政府部门等场所,可以通过声纹识别来确认用户的身份,以保障敏感信息的安全访问。同时,在电话银行和客服行业,声纹识别可以用于验证客户的身份,提升用户体验。此外,声纹识别也在犯罪侦查和取证方面发挥着重要作用。它可以帮助警方鉴别犯罪嫌疑人,也可以作为法庭取证的一种手段,解决一些涉及声音录音的法律案件。在智能语音助手领域,声纹识别可以区分不同的用户,从而提供个性化的服务。不同的用户可以享受到特定于他们的定制化建议、提醒等功能。
5、技术方法层面,目前主流的声纹识别技术主要应用的是如下技术:mfcc(melfrequency cepstral coefficients)是常用于声纹识别的特征提取方法,它模拟了人耳对声音的感知机制,将声音信号转化为一系列频率系数,从而提取出有用的特征;gmm-ubm(gaussian mixture model-universal background model)是一种常用的统计建模方法,它将声音特征建模为高斯混合模型,并使用通用的背景模型进行比对,从而实现说话人的识别;i-vector是一种表示说话人特征的方法,它通过将声学特征投影到一个低维空间中,将说话人的声学特征编码为一个向量,用于构建说话人识别系统;随着深度学习技术的发展,卷积神经网络(cnn)和循环神经网络(rnn)等深度学习模型在声纹识别中取得了显著的成果,用于提取声音特征;siamese网络用于学习说话人相似度,它可以在说话人验证等任务中取得良好的效果,通过比较两段声音信号的相似程度来判断是否属于同一说话人。
6、但是在提取说话人的声纹特征时,往往会受到噪声因素的干扰,使得声学细节模糊,从而影响模型的性能和识别率。此外,采用高斯分量的gmm模型也具有局限性。随着gmm规模逐渐变大,模型表征的能力增强。但同时参数量也会随之增加,也就是说,高斯分量需要大量的数据进行训练来模拟分布,需要有更多的数据参与驱动gmm的训练,否则其性能就会变差。即使将目标用户的训练数据大幅提升,也很难符合gmm的充分训练要求。当数据量较少时,高斯混合模型很容易陷入过拟合的境地,无法应用与多个场景下。
技术实现思路
1、为解决现有技术所存在的技术问题,本发明提供一种基于动量对比学习的声纹识别方法和设备,可以获得大量不同环境的声纹样本数据,训练的时候让识别模型捕获更多有效特征,增强了泛化性,有效防止噪声因素的干扰,可以在复杂的环境下较好地完成声纹识别任务,提高识别效率。
2、本发明的第一个目的在于提供一种基于动量对比学习的声纹识别方法。
3、本发明的第二个目的在于提供一种计算机设备。
4、本发明的第一个目的可以通过采取如下技术方案达到:
5、一种基于动量对比学习的声纹识别方法,所述方法包括:
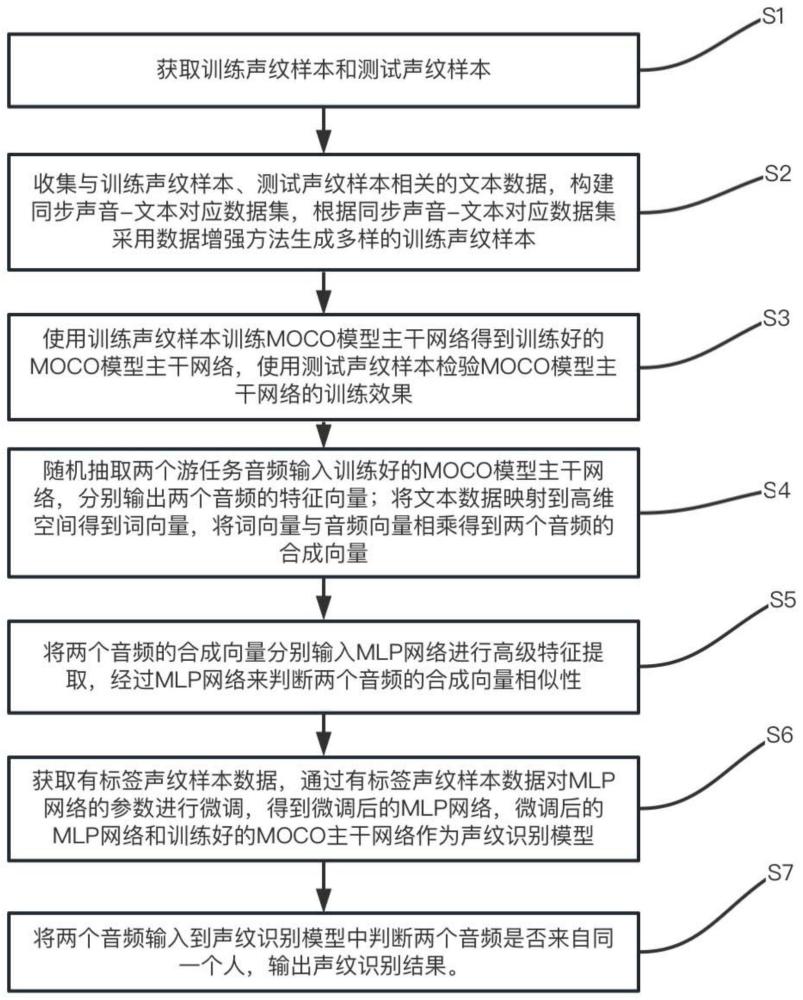
6、s1、获取训练声纹样本和测试声纹样本;
7、s2、收集与训练声纹样本、测试声纹样本相关的文本数据,构建同步声音-文本对应数据集,根据同步声音-文本对应数据集采用数据增强方法生成多样的训练声纹样本;
8、s3、使用训练声纹样本训练moco模型主干网络得到训练好的moco模型主干网络,使用测试声纹样本检验moco模型主干网络的训练效果;
9、s4、随机抽取两个游任务音频输入训练好的moco模型主干网络,分别输出两个音频的特征向量;将文本数据映射到高维空间得到词向量,将词向量与音频向量相乘得到两个音频的合成向量;
10、s5、将两个音频的合成向量分别输入mlp网络进行高级特征提取,经过mlp网络来判断两个音频的合成向量相似性;
11、s6、获取有标签声纹样本数据,通过有标签声纹样本数据对mlp网络的参数进行微调,得到微调后的mlp网络,微调后的mlp网络和训练好的moco主干网络作为声纹识别模型;
12、s7、将两个音频输入到声纹识别模型中判断两个音频是否来自同一个人,输出声纹识别结果。
13、优选的技术方案中,所述对语音数据集进行预处理,包括
14、对声音数据进行降噪处理,采用傅里叶变换去除部分类型的噪音,通过denoisingautoencoders自编码器来对声音进行降噪;
15、对声音数据的采样率、位深度和格式进行统一格式;
16、对语音数据进行语音分段。
17、优选的技术方案中,所述收集与训练声纹样本、测试声纹样本相关的文本数据,构建同步声音-文本对应数据集,包括:
18、收集与训练声纹样本、测试声纹样本相关的文本数据,对文本数据进行清洗和标准化处理得到训练声纹样本、测试声纹样本的文本表示,将同一说话者的训练声纹样本的声音表示和文本表示进行匹配,得到同步声音-文本对应数据集。
19、优选的技术方案中,所述使用训练声纹样本训练moco模型主干网络,得到训练好的moco模型主干网络,包括:
20、使用训练声纹样本训练moco模型主干网络,选择合适的mini-batch size和代理任务,以任意一个训练声纹样本作为音频数据原样本生成训练声纹样本的正负样本对,基于训练声纹样本的正负样本对构建动态数据字典;
21、从动态数据字典的训练声纹样本中进行随机抽取多个音频,对一个音频采用mfcc方法提取音频信号的特征向量,通过resnet-18网络的encoder编码器进行前向传播,生成query向量;对其他音频通过使用mfcc方法提取它们音频信号的特征向量,通过resnet-18网络的momentum-encoder动量编码器前向传播,输出key向量集,将key向量集进入队列;
22、使用infonce损失函数进行特征学习,更新encoder参数和momentum encoder参数,得到训练好的moco模型主干网络。
23、优选的技术方案中,,所述使用infonce损失函数进行特征学习,更新encoder参数和momentum encoder参数,包括:
24、从动态数据字典中获取正样本生成的key向量,并且随机抽取若干数量负样本生成的key向量,正样本生成的key向量、负样本生成的key向量和一个对应的query向量做query-key查询并输入到损失函数之中计算损失,然后进行反向传播,直接更新参数encoder,进行动量式更新参数momentum encoder。
25、优选的技术方案中,所述将两个音频的合成向量分别输入mlp网络,进行高级特征提取,判断两个音频的合成向量相似性,包括:
26、将这两个音频的合成向量分别输入mlp网络,通过mlp网络的linear线性层对音频的合成向量进行高级特征提取,使用余弦相似性函数来计算这两个合成向量之间的余弦相似性,将余弦相似性与预先设定的阈值进行比较;如果余弦相似性大于等于阈值,判断这两段音频出自同一人;否则,判断这两段音频不出自同一个人。
27、本发明的第二个目的可以通过采取如下技术方案达到:
28、一种计算机设备,包括处理器以及用于存储处理器可执行程序的存储器,所述处理器执行存储器存储的程序时,实现上述的一种基于动量对比学习的声纹识别方法。
29、本发明与现有技术相比,具有如下优点和有益效果:
30、本发明提供一种基于动量对比学习的声纹识别方法和设备,应用moco主干网络来提取声音的特征,使用了队列的数据结构思想来减轻训练网络时对电脑储存的依赖,并且使用动量更新的方法来保证数据样本的一致性,从而保证了训练的有效性;并且结合了文本嵌入的方式,实现了音频和文本的多模态学习;训练mlp网络来更好地完成说话人识别的下游任务;使用了无标签数据的对比学习在降低了对训练数据依赖同时还增强模型的泛化能力,可以在复杂的环境下实现更准确的声纹识别。
本文地址:https://www.jishuxx.com/zhuanli/20240618/21300.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表