一种基于Transformer的调制融合在语音情感识别的方法与流程
- 国知局
- 2024-06-21 11:38:57
本发明属于语音识别,具体涉及一种基于transformer的调制融合在语音情感识别的方法。
背景技术:
1、自然语言处理中的情感识别和情感分析一直都是研究的热点,但最新的研究成果往往伴随着越来越复杂和的神经网络,使得其在性能一般的轻量化设备上不容易高效实现。
2、现有的情感识别和情感分析方案大多带有复杂的卷积网络,需要昂贵的设备支持和算力保证。在轻量级的情感识别和情感分析方案上一直没有较为成熟的解决方案。
技术实现思路
1、针对上述现有的情感识别和情感分析方案大多带有复杂的卷积网络,需要昂贵的设备支持和算力保证的技术问题,本发明提供了一种基于transformer的调制融合在语音情感识别的方法,通过提出两种基于transformer调制的架构,将来自广泛数据集的语言和声学输入结合起来,实现了轻量化的功能。
2、为了解决上述技术问题,本发明采用的技术方案为:
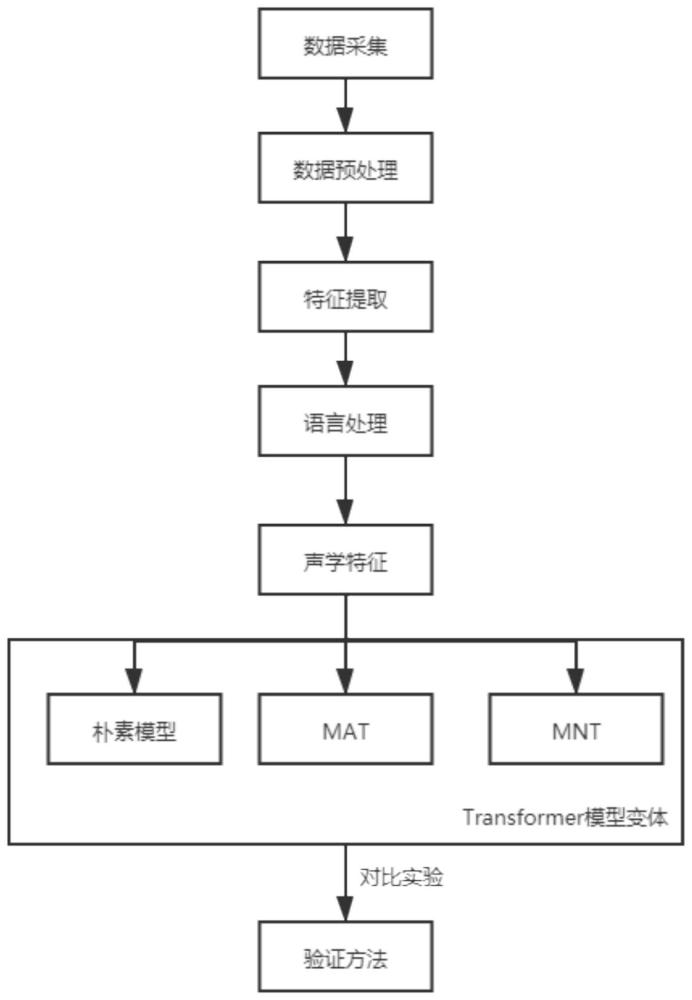
3、一种基于transformer的调制融合在语音情感识别的方法,包括下列步骤:
4、s100、数据采集:采集模型所需的数据,并对其类别进行标注,完成模型所需的数据集构建;
5、s200、数据预处理:对数据集进行的预处理,为后续的搜索做必要准备;
6、s300、特征提取:描述提出的基于变压器的调制融合的输入所用的语言和声学特征;
7、s400、语言处理:句子被标记化并用小写字母表示,并删除特殊字符和标点符号;
8、s500、提取声学特征:采用了seq2seq文本-语音系统的方法来提取墨尔本光谱图;
9、s600、构建transformer模型变体:包含三种变体,分别为朴素transformer模型,调制注意transformer和调制归一化transformer;
10、s700、验证模型:在数据集中验证方法的有效性和可行性。
11、所述s200中数据预处理的方法为:对数据进行数据归一化处理,采用特征标准化,使数据集中所有特征都具有零均值和单位方差。
12、所述s300中特征提取的方法为:对数据集的每个样本独立地进行提取,x和y都有一个大小[t,c],其中t是时间轴大小,c是特征大小,x为语言示例,y为声学示例,对于每个样本,t是不同的,而c是一个超参数。
13、所述s400中语言处理的方法为:根据数据集的训练集构建词汇表,并使用传统字嵌入方法将每个单词嵌入300维向量中,一个来自验证或测试集的单词不在词汇表中,则将其替换为未知的标记为unk,每个句子都要经过一个长度为c的单向一层lstm,每个语言示例x的大小为[t,c],其中t为句子中的单词数。
14、所述s500中提取声学特征的方法为:墨尔本光谱图是使用80个过滤器组,然后通过每16帧选择一帧来应用时间缩减,最后,每个声谱图通过一个尺寸为c的单向一层lstm运行,每个声学示例y的大小为[t,c],其中t是声谱图中的帧数。
15、所述s600中构建transformer模型变体的方法为:朴素transformer模型是将一个transformer叠加在提取的语言和声学特征之上,transformer间是互相独立的,它们各自的输入特性不相互影响,一个transformer是由b个相同的块组成的堆栈,但是有它们自己的一组训练参数,每个块有两个子层,在两个子层的每一个周围都有一个剩余连接,然后是隐含层的层归一化,每个子层的输出为:
16、layernorm(x+sublayer(x))
17、其中,子层(x)是由子层本身实现的功能;
18、调制注意transformer:为了通过语言输出来调节声音的自我注意,将自我注意的键k和值v从y转换到x,下面的方程描述了新的注意子层在声学transformer中的表示,
19、y=layernorm(y+mha(y,x,x))
20、其中,将y,x,x输入mha模块并于y值相加后就是其隐含层的层归一化,mha是多头注意力机制模块;
21、调制归一化transformer:实现语言输出通过放大或缩小、否定或关闭它们来操纵整个声学特征图,由于每个feature map只有两个参数,所以新训练参数的总数较少,使得调制的规范化成为一种非常可伸缩的方法。
22、本发明与现有技术相比,具有的有益效果是:
23、本发明在为情感识别和情感分析提供一种新的轻量级而强大的解决方案。通过提出两种基于transformer调制的架构,将来自广泛数据集的语言和声学输入结合起来,挑战超越该领域的最先进水平。通过在相关数据集上的验证,证明了本发明的可行性和有效性。
技术特征:1.一种基于transformer的调制融合在语音情感识别的方法,其特征在于:包括下列步骤:
2.根据权利要求1所述的一种基于transformer的调制融合在语音情感识别的方法,其特征在于:所述s200中数据预处理的方法为:对数据进行数据归一化处理,采用特征标准化,使数据集中所有特征都具有零均值和单位方差。
3.根据权利要求1所述的一种基于transformer的调制融合在语音情感识别的方法,其特征在于:所述s300中特征提取的方法为:对数据集的每个样本独立地进行提取,x和y都有一个大小[t,c],其中t是时间轴大小,c是特征大小,x为语言示例,y为声学示例,对于每个样本,t是不同的,而c是一个超参数。
4.根据权利要求1所述的一种基于transformer的调制融合在语音情感识别的方法,其特征在于:所述s400中语言处理的方法为:根据数据集的训练集构建词汇表,并使用传统字嵌入方法将每个单词嵌入300维向量中,一个来自验证或测试集的单词不在词汇表中,则将其替换为未知的标记为unk,每个句子都要经过一个长度为c的单向一层lstm,每个语言示例x的大小为[t,c],其中t为句子中的单词数。
5.根据权利要求1所述的一种基于transformer的调制融合在语音情感识别的方法,其特征在于:所述s500中提取声学特征的方法为:墨尔本光谱图是使用80个过滤器组,然后通过每16帧选择一帧来应用时间缩减,最后,每个声谱图通过一个尺寸为c的单向一层lstm运行,每个声学示例y的大小为[t,c],其中t是声谱图中的帧数。
6.根据权利要求1所述的一种基于transformer的调制融合在语音情感识别的方法,其特征在于:所述s600中构建transformer模型变体的方法为:朴素transformer模型是将一个transformer叠加在提取的语言和声学特征之上,transformer间是互相独立的,它们各自的输入特性不相互影响,一个transformer是由b个相同的块组成的堆栈,但是有它们自己的一组训练参数,每个块有两个子层,在两个子层的每一个周围都有一个剩余连接,然后是隐含层的层归一化,每个子层的输出为:
技术总结本发明属于自然语言处理情感分析技术领域,具体涉及一种基于句法结构迁移和领域融合的跨领域情感分类方法,基于句法结构迁移和领域融合的跨领域情感分类总体框架。依存句法递归神经网络模型。跨领域模型参数迁移策略。源领域网络到目标领域网络的参数预训练和微调。跨领域融合策略。领域联合学习和优化过程。本发明提出了一种基于句法结构迁移和领域融合的跨领域情感分类方法,具体设计一种新的可迁移的依存句法递归神经网络模型,通过句法结构迁移有效地迁移跨领域结构信息。在递归神经网络层和Softmax层之间加入了领域融合层,通过约束源领域和目标领域的分布,以领域融合的方式实现最大化源领域和目标领域情感信息之间的共享。技术研发人员:潘晓光,张娜,侯志强,焦璐璐,陈亮,马彩霞受保护的技术使用者:山西三友和智慧信息技术股份有限公司技术研发日:技术公布日:2024/3/24本文地址:https://www.jishuxx.com/zhuanli/20240618/22670.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。