基于深度强化学习的多机器人分层编队控制方法及系统
- 国知局
- 2024-07-30 09:29:43
本发明涉及非电变量的控制,具体涉及一种基于深度强化学习的多机器人分层编队控制方法及系统。
背景技术:
1、本部分的陈述仅仅是提供了与本发明相关的背景技术,并不必然构成现有技术。
2、近几年来,随着控制、通信和机器学习等领域的技术发展与交叉融合,受到生物学和人类社会学研究的启发,多机器人协同控制逐渐成为众多领域的研究重点和热点,并取得了阶段性的研究成果。相对于单一机器人系统,多机器人系统具有分布式的感知与执行能力、内在并行性、高容错性和高效率等诸多优点,可以更有效地完成复杂的任务。多机器人编队控制是指多个机器人组成的系统,借助每个机器人个体间的局部交互,在一定控制策略的作用下,调整每个机器人个体的行为,实现机器人的相互聚结并在保持一定的几何形态的同时进行整体性位移,同时又要适应如避障避撞等环境约束的控制问题。多机器人编队控制在工业、农业、军事、航空航天、地理测绘、搜索救援以及交通物流等多个领域都具有广泛的应用前景。因此,多机器人编队控制已经发展成为多机器人系统协同控制领域的重要研究方向。然而,多机器人系统内在的交联特性也给系统的分析带来了很多困难,其研究仍处于发展阶段。
3、多机器人的编队控制技术是完成各种多体协同任务的前提条件,其主要目的是通过系统内部机器人之间局部的信息交互,使机器人能够形成并且维持一个特定的相对位置以及相对速度关系,实现队形保持、队形变化和避障等多机器人系统的基本功能。在军事领域,无人舰艇和无人机组成的异构机器人系统,能够完成协同作战、侦察和补给等任务,如大规模无人机蜂群作战。在民用领域,多机器人系统被广泛运用于野外位置环境建图、灾后救援等任务。多机器人的优化控制是通过多机器人之间的合作协调有效地实现优化的任务,相比集中式优化算法,分布式优化算法的鲁棒性更好,成为优化与控制领域的一个重要研究方向。目前,分布式控制方法依赖于多机器人系统精确模型已知和状态可观测,然而真实场景中系统的精确模型往往难以获取,如何基于数据而不是模型实现分布式控制已成为研究领域的重要挑战。随着强化学习在多机器人系统分布式控制里的普遍应用,尤其是海量历史数据作为技术的支撑,由数据驱动的控制算法在智能控制领域愈发受到重视。
4、编队控制是多机器人协调控制系统设计中的典型问题之一,从驱动方式的角度来看,主流的编队控制方法主要可以分为规则驱动的方法和数据驱动的方法。规则驱动的方法通常依赖于预设的规则或启发式算法来实现编队控制。数据驱动的方法则依赖于大量训练数据,通过试错的方式来学习最优的控制策略,可以包括监督学习、无监督学习等。规则驱动的方法目前最常用的是基于一致性算法的控制策略,主要包括领队-跟随法、虚拟结构法、基于行为法等。数据驱动的策略主要是基于深度强化学习来实现编队控制,主要包括d3qn(dueling double deep q-network)、ddpg(deep deterministic policy gradient)、maddpg(multi-agent deep deterministic policy gradients)等。
5、多机器人系统的一致性问题是指:系统中的每个机器人根据其局部交互信息及其控制策略,使得所有机器人的某些状态量趋于相同。由于控制策略仅依赖于各个机器人自身的信息和相邻机器人的局部交互信息,而非系统全局信息,这为解决多机器人的编队控制问题提供了重要手段。此后该领域得到了快速增长,并吸引了大量研究者的加入,分别对高阶系统、非线性系统、带延时、网络丢包、有限时间一致性等方面进行了深入探索,并有研究者对其进行了对比研究。
6、在一致性算法的基础上,众多学者研究并提出了多种多机器人编队控制策略和方法。有学者系统地介绍了一致性方法在二阶积分系统轨迹跟踪和编队控制中的应用,并且表明目前主流的传统编队控制策略,如领队-跟随法、虚拟结构法和基于行为法的编队控制方法等,在实现多机器人系统协同控制时都以状态或行为的一致性为目标,通过局部信息交互以及迭代计算和收敛来实现多机器人控制,因而都可以看作是基于一致性方法的特例。
7、虽然基于一致性问题的编队控制算法可以很容易地应用在编队控制问题中,并且已经取得了大量的研究成果,但是在实际的多机器人协同控制中仍然存在诸多问题。比如,在编队控制中必须考虑机器人内部碰撞的问题,而一致性问题的目的是使多机器人的某些状态达成一致,不存在内部避碰的问题。目前已有诸多针对避碰问题的解决方案,但是难以和一致性方法相结合。目前,基于一致性算法的多机器人编队选用的主流避碰方法是人工势场法,虽然能够保证碰撞不会发生,但是控制效率不高,机器人在遇到障碍物碰撞危险时其运动状态可能会发生较大变动,这很可能导致控制指令饱和,同时机器人还可能陷入局部震荡的情况。此外,大多数的多机器人编队控制方法都依赖于精确的物理模型设计,但实际的模型和研究者构建的模型之间必然存在或多或少的差距,这很可能会导致编队的控制产生较大误差甚至是失效。
8、深度学习(deep learning,dl)和强化学习(reinforcement learning,rl)作为机器学习的两大重要分支,近几年来发展迅速,这极大地加快了多机器人系统的智能化进程。目前,已有学者将深度学习的感知能力和强化学习的决策能力相结合,形成深度强化学习,如dqn(deep q-network)等算法,应用于多机器人编队控制。
9、有学者在actor-critic框架基础上,将传统网络结构优化并结合双重记忆库方法,提出了一种cacer(continuous actor-critic with experience replay)算法,解决了在连续状态下领队-跟随拓扑结构下的多无人机聚集问题。有学者提出一种可变学习率的q-learning的方法,使得跟随者能够学习到在平稳随机环境中保持跟随领队的方法。有学者提出了一种群强化学习方法,实现了目标队列较大且复杂的情况下的多机器人编队。有学者提出一种id3qn(imitative dueling double deep q-network)算法,相较于传统算法提高了学习效率,实现了无人机编队协调控制,并通过半物理仿真系统实验进行了验证。有学者设计基于d3qn算法的编队控制器,同时提出一种优先选择策略与多层动作库结合的方法,加速了算法收敛速度并使僚机最终实现领队跟随。有学者提出了一种基于maddpg算法的多无人机协同任务决策方法,相比于传统的深度强化学习算法提高了学习速度。有学者提出了一种基于lstm的策略,使得编队算法可以接收任意数量的其他智能体的观测结果。有学者使用了一种复合奖惩机制,用于求解机器人编队中的多目标优化问题。
10、虽然深度强化学习具有强大的学习和泛化能力,并且已经在多机器人控制领域取得了大量研究成果,但是深度强化学习在实际使用中还存在其局限性。深度强化学习在复杂的任务中,由于每个样本的时间或空间复杂度较长,其采样效率会大幅降低。在多机器人编队任务中,传统的训练方式采用直接编队来训练模型,长时间的编队移动和固定的编队队形会极大地影响采样效率和模型最终的泛化能力。此外,深度强化学习的一个重要假设是存在奖励,它能引导机器人的策略向“正确”的方向改进。奖励函数在学习过程中一般是一个固定项,由研究人员根据先验知识所设置,对于简单的任务目标而言,设置简单的奖励函数即可训练出最佳的策略,然而,对于多机器人编队任务等复杂任务,奖励函数只能给出大致的学习目标,这可能导致训练陷入局部最优、奖励过度拟合导致预期外的结果以及收敛缓慢甚至不收敛等结果。
技术实现思路
1、为了解决现有技术的不足,本发明提供了一种基于深度强化学习的多机器人分层编队控制方法及系统,能够快速学习并跟随目标点,有效的避免了机器人碰撞,在多机器人实时编队任务的控制中具有较强的泛化能力。
2、为了实现上述目的,本发明采用如下技术方案:
3、第一方面,本发明提供了一种基于深度强化学习的多机器人分层编队控制方法。
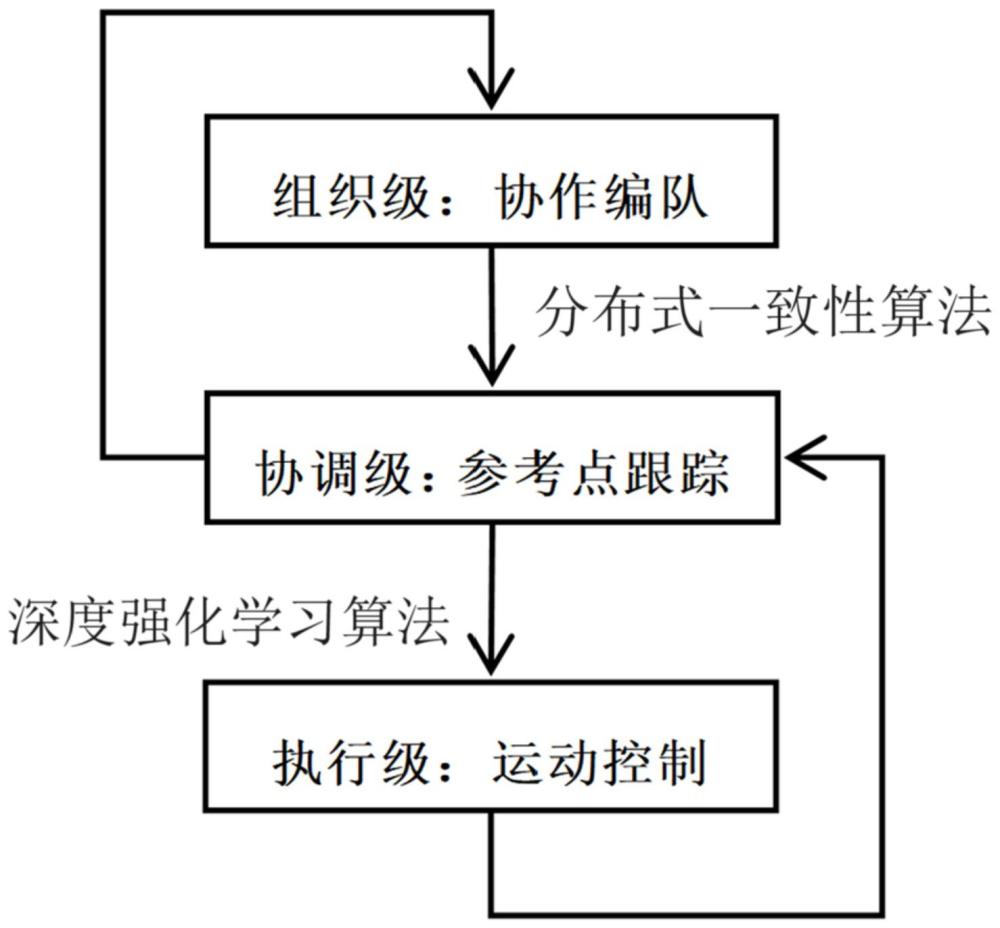
4、一种基于深度强化学习的多机器人分层编队控制方法,包括以下过程:
5、对机器人编队中的各机器人,获取各机器人的位置坐标信息、各机器人的运动速度、各机器人与当前时刻参考点的相对坐标以及各机器人与机器人编队中的其他机器人的相对坐标;
6、根据各机器人与机器人编队中的其他机器人的相对坐标以及基于lstm(longshort-term memory,长短期记忆)的自编码器网络,得到各个机器人的障碍物信息的定长编码,以所述障碍物信息的定长编码以及各机器人的位置坐标信息、各机器人的运动速度、各机器人与当前时刻参考点的相对坐标作为多机器人分层控制模型的输入,得到机器人编队中各个机器人的行动策略。
7、作为本发明第一方面进一步的限定,多机器人分层控制模型中,采用分布式一致性算法,在每个采样时间段内对各机器人拥有的信息进行处理,通过对各机器人的信息进行一致性协商而达到状态一致。
8、作为本发明第一方面更进一步的限定,采用分布式控制方法,每个机器人只知道相邻机器人的位置信息,机器人的协作编队模型为:
9、;
10、其中,为编队拓扑图的邻接矩阵中第i行第j列的元素,,,为 t时刻调整前机器人 i要跟踪的参考点,为t时刻调整前机器人j要跟踪的参考点,为t时刻调整后机器人i要跟踪的参考点。
11、作为本发明第一方面更进一步的限定,对机器人编队中的任一个机器人,此机器人将自己的初始状态作为参考点估计的初值,通过信息交换并不断进行协作调整,最终使机器人编队的参考点形成期望队形。
12、作为本发明第一方面进一步的限定,基于lstm的自编码器网络,包括:lstm编码器层、repeatvector层和lstm解码器层,机器人与机器人编队中的其他机器人的相对坐标序列被输入至lstm编码器层进行编码,生成隐藏层编码,所述隐藏层编码作为障碍物信息的定长编码;
13、repeatvector层和lstm解码器层用于基于lstm的自编码器网络的零样本训练,通过repeatvector层将障碍物信息的定长编码匹配至原始序列长度,lstm解码器层用于将repeatvector层的输出还原为原始数据序列。
14、作为本发明第一方面进一步的限定,多机器人分层控制模型中,采用训练好的maddpg目标跟踪模型,每个机器人给出其最佳的目标点跟踪策略动作,以各个机器人分布式一致性算法处理后的结果为输入,得到每个机器人的最佳目标点跟踪策略动作;
15、maddpg目标跟踪模型的训练中,每个机器人的总奖励值为距离奖励值和碰撞惩罚值的加和,采用基于自适应奖惩方法进行碰撞惩罚值的更新,包括以下过程:
16、步骤1:训练开始,初始化当前奖励值规模变量为0;
17、步骤2:判断训练是否全部完成,如果是则结束训练,否则执行步骤3;
18、步骤3:判断碰撞惩罚值与当前奖励值规模的差异是否大于设定阈值,如果是,执行步骤4,否则跳过步骤4直接执行步骤5;
19、步骤4:根据当前奖励值规模调整碰撞惩罚值的大小;
20、步骤5:执行一次训练,向当前maddpg目标跟踪模型返回奖励值,并更新当前奖励值规模,返回步骤2。
21、第二方面,本发明提供了一种基于深度强化学习的多机器人分层编队控制系统。
22、一种基于深度强化学习的多机器人分层编队控制系统,包括:
23、数据获取单元,被配置为:对机器人编队中的各机器人,获取各机器人的位置坐标信息、各机器人的运动速度、各机器人与当前时刻参考点的相对坐标以及各机器人与机器人编队中的其他机器人的相对坐标;
24、分层编队控制单元,被配置为:根据各机器人与机器人编队中的其他机器人的相对坐标以及基于lstm的自编码器网络,得到各个机器人的障碍物信息的定长编码,以所述障碍物信息的定长编码以及各机器人的位置坐标信息、各机器人的运动速度、各机器人与当前时刻参考点的相对坐标作为多机器人分层控制模型的输入,得到机器人编队中各个机器人的行动策略。
25、作为本发明第二方面进一步的限定,分层编队控制单元的多机器人分层控制模型中,采用分布式一致性算法,在每个采样时间段内对各机器人拥有的信息进行处理,通过对各机器人的信息进行一致性协商而达到状态一致。
26、作为本发明第二方面更进一步的限定,采用分布式控制方法,每个机器人只知道相邻机器人的位置信息,机器人的协作编队模型为:
27、;
28、其中,为编队拓扑图的邻接矩阵中第 i行第 j列的元素,,,为t时刻调整前机器人 i要跟踪的参考点,为t时刻调整前机器人j要跟踪的参考点,为 t时刻调整后机器人 i要跟踪的参考点。
29、作为本发明第二方面更进一步的限定,对机器人编队中的任一个机器人,此机器人将自己的初始状态作为参考点估计的初值,通过信息交换并不断进行协作调整,最终使机器人编队的参考点形成期望队形。
30、与现有技术相比,本发明的有益效果是:
31、1、针对传统编队控制方法中的智能化程度低、训练收敛速度慢、设计控制方法对模型信息要求高等问题,本发明创新性的提出了一种基于深度强化学习的多机器人分层编队控制方法及系统,能够快速学习跟随目标点,有效的避免了机器人碰撞,在多机器人实时编队任务的控制中具有较强的泛化能力。
32、2、针对分层编队控制模型在避撞方面的不足,本发明通过在模型训练过程中自适应调整奖惩参数,该方法显著提高了模型在仿真实验中的避撞能力,降低了碰撞率。
33、3、为了解决障碍物信息数量需要提前固定的局限,本发明提出了一种基于预训练自编码器的无监督学习策略,使得模型能够通过零样本预训练获得处理任意长度的数据序列的能力,实现了对任意数量的机器人和障碍物位置信息的灵活处理。
34、本发明附加方面的优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
本文地址:https://www.jishuxx.com/zhuanli/20240730/149638.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表