一种基于深度学习的轻量化交通流预测方法
- 国知局
- 2024-07-31 22:55:10
本发明涉及交通流预测,具体涉及一种基于深度学习模型、剪枝和蒸馏轻量化技术的交通流预测方法。
背景技术:
1、目前,随着城市化的发展,城市机动车数量急剧增加,城市交通拥堵加剧,机动车尾气排放也相应放大。准确的交通预测有助于实时优化交通信号控制,从而提高道路利用率,减少交通拥堵,最终提高城市交通运行效率。
2、深度学习算法在交通流预测方面具有显著的准确性,但其实施受到高计算成本的阻碍。为了追求交通系统的无缝运行以及车辆与道路基础设施之间的快速通信,最佳解决方案是将流线型模型放置在本地运行的边缘设备上。近年来的研究越来越关注时间序列边缘的部署问题。为了减少计算和存储复杂性,提出了包括参数量化和稀疏关注在内的创新方法。
3、大多数现有的轻量化方法主要侧重于降低以失败为衡量标准的计算复杂性,而忽略了现实场景中的实际应用。先进的交通流预测模型的特点是精度高,但往往具有冗余结构。利用轻量级方法可以通过删除多余的组件来简化模型。
4、从广义上讲,深度学习轻量化方法可以概括为知识蒸馏、剪枝和量化。大多数轻量化方法主要集中在图像分类和自然语言推理上,而交通流数据具有时空依赖性。然而,轻量化技术在交通流预测领域的应用相对有限。
5、神经网络架构自动轻量化成为制作高效深度学习模型的关键方法,且多技术的协同作用可能会超过每种单独方法的功效。这些技术主要基于图像分类和视频识别,尚未在交通流预测领域得到广泛应用。这种差距主要源于交通流数据分析固有的独特挑战和时空复杂性,它与图像处理领域中更直接的分类任务和图像数据操作有很大差异,导致模型模块设计和应用的差异。
技术实现思路
1、针对现有技术中存在的不足,本发明目的是提供一种基于深度学习的轻量化交通流预测方法,采用局部和全局剪枝技术,由不同粒度的掩模控制每个参数的剪枝决策,并利用分层蒸馏策略在优化过程中将知识从未剪枝模型转移到已剪枝模型,提高了真实路网环境下轻量化交通流预测精度,为构建硬件限制下的交通流预测系统提供技术支持。
2、为解决上述技术问题,本发明提供的技术方案是:
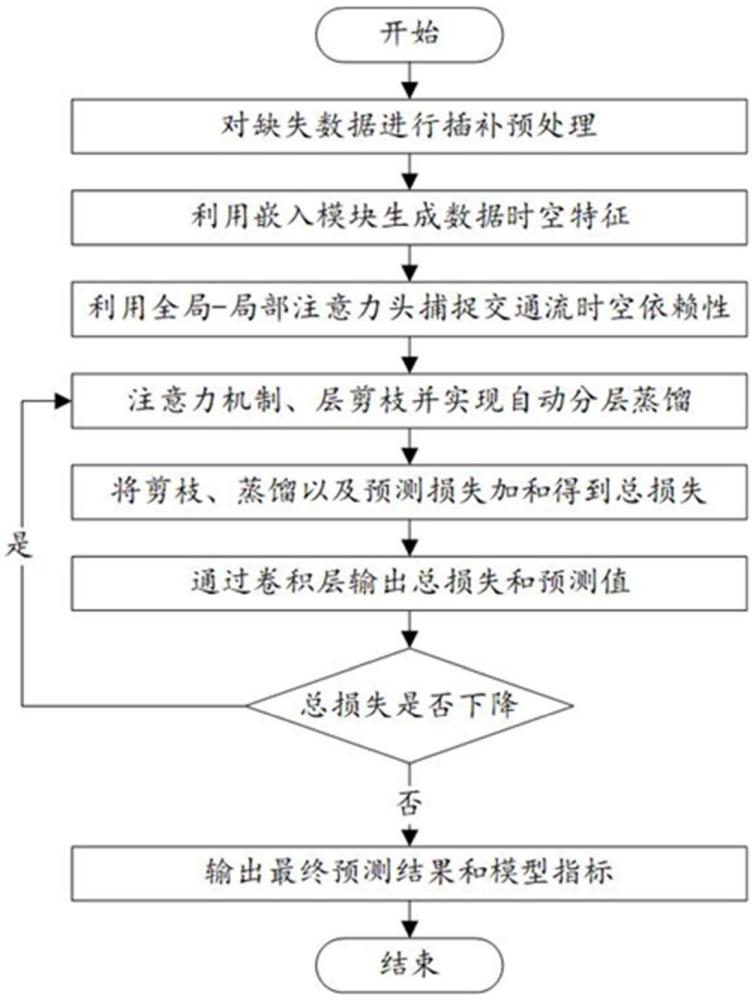
3、一种基于深度学习的轻量化交通流预测方法,包括如下步骤:
4、s1、获取交通流参数数据,并对数据进行预处理,包括异常值清理、错误数据纠正、缺失数据插补、归一化和时间序列化处理,获得预处理数据;
5、s2、构建训练样本集,将多个预处理数据作为每个训练样本的标签,将未来指定时间步的交通流参数数据作为输出,每个训练样本包括多个时空特征;
6、s3、基于交通流的时空特征,构建一个深度学习预测模型;所述预测模型包括时空注意力机制、多层感知机;
7、s4、使用轻量化的方法对所述预测模型进行优化处理;
8、所述轻量化方法包括剪枝技术和蒸馏技术;具体为使用多头注意力层、多层感知器层、注意力模块和多层感知器神经元剪枝,将所述预测模型由粗到细进行剪枝,然后用蒸馏技术对所述预测模型进行效果迁移;
9、s5、将剪枝损失、蒸馏损失和预测损失函数相加,得到总损失函数,反向传播以动态调整预测模型;
10、s6、通过卷积层输出预测模型总损失函数和预测值,判断总损失函数是否下降;
11、若总损失下函数降则继续训练、剪枝和蒸馏预测模型;若总损失函数不下降则终止预测模型,得到最终输出结果;
12、s7、部署所述深度学习预测模型至实时交通监测系统中,输出最终预测结果,最终利用实时采集的交通数据进行交通流预测。
13、优选的,
14、所述s2中对于标签为t的连续时间段内的交通流训练样本,其特征向量构建包括:
15、获取连续的车流量数据集,根据交通流数据的周期性,利用嵌入模块生成数据时空特征xe,包括时、日和周三种时间步长下的周期子数据集xh、xd和xw;时间位置嵌入xp和道路网络节点xg;
16、截取时、日和周三种时间步长下的周期子数据集xh、xd和xw;为保持输入数据的先后顺序,利用三角位置编码将原始数据转化为时间位置嵌入xp;将交通检测器和所在路段的拓扑结构表示为图,道路网络节点转化为子数据集xg;将五种子数据集进行合并,得到模型输入xe;将五种子数据集进行维度统一后相加。
17、优选的,
18、所述s3中的时空注意力包括局部时间注意力机制lta、全局时间注意力机制gta、局部空间注意力机制lsa和全局空间注意力机制gsa,将四种注意力机制结合得到时空注意力机制,四个注意力机制的表达式如下所示:
19、lta(xe)=softmax(alt)vlt (1)
20、gta(xe)=softmax(agt)vgt (2)
21、lsa(xe)=softmax((alse msem)+(alse mpro))vls (3)
22、gsa(xe)=softmax(ags)vgs (4)
23、其中,vlt、vgt、vls和vgs分别为局部时间间注意力、全局时间注意力、局部空间注意力和全局空间注意力的值;alt、agt、als和ags为局部时间注意力、全局时间注意力、局部空间注意力和全局空间注意力的分数;msem为使用动态时间规划算法计算节点间历史交通流的相似度,构建的语义掩码;mpro为使用邻近效应,构建的邻接掩码。
24、优选的,
25、所述局部空间注意力机制lsa使用msem和mpro两个掩码作为核心技术;
26、所述msem采用动态时间规划算法计算节点间历史交通流的相似度,选择相似度最高的k个节点作为语义邻居,其他节点通过乘0去除;
27、所述mpro使用邻近效应,将交通的传播限制在交通路网的一层邻接范围内,其他邻接层通过乘0去除。
28、随后在每个时空编码层后使用1×1卷积构成的跳跃连接和注意力层输出相加得到最终隐藏状态xhid;输出层对最终隐藏状态使用一个1×1卷积转换为预测所需维度xout,表示为:
29、xout=conv2(conv1(xhid)) (5)
30、优选的,
31、所述s4中的剪枝技术,从粗到细对模型进行全面的剪枝,在粗颗粒度方面对注意力层和多层感知机层进行剪枝,在细粒度方面对注意力和多层感知机中的细胞元进行剪枝;剪枝过程的重要技术为使用改进sigmoid函数将离散稀疏性决策转换为连续域,最终将这些决策强化为训练后的近二值{0,1}结果去除冗余结构,其公式如下:
32、
33、其中,σ为sigmoid函数,u为从均匀分布u(0,1)中抽样的随机变量,τ为控制函数陡峭度的温度参数;logα和τ是主要的可学习参数。
34、优选的,
35、所述s4中的蒸馏技术包括自动匹配层蒸馏和输出层蒸馏;
36、自动匹配层蒸馏无需提前设置需要匹配的层数,使用自动化技术选定注意力层对应剪枝后的注意力层;输出层蒸馏将剪枝前的模型训练效果迁移到完整剪枝后的模型上,恢复模型性能。
37、优选的,
38、所述s5中的预测损失加剪枝损失函数如下所示:
39、
40、其中,p表示模型在训练数据上的性能损失,表示模型当前的稀疏度;r是目标稀疏度级别,即期望模型达到的期望稀疏度;λ1和λ2是拉格朗日乘子,用于调整稀疏性约束的强度;
41、所述s5中的蒸馏层损失函数加输出损失函数可以表示为:
42、lkd= α(mae ps || pt ) + (1- α) ll (9)
43、其中,ps和pt分别表示学生和教师的输出概率分布;ll为层蒸馏损失函数;mae为平均绝对误差;α表示各损失的影响程度;以及mae ps||pt为输出蒸馏损失函数。
44、本发明的有益效果是:
45、本发明在降低计算和存储需求的情况下实现了与最先进模型相当的精度,同时显著减少了计算支出和模型规模,为进行轻量化交通流预测奠定了理论基础,为减少城市交通拥堵提供了技术支持。
本文地址:https://www.jishuxx.com/zhuanli/20240730/195312.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表