一种多粒度语义增强表示的中文关键词抽取方法及装置
- 国知局
- 2024-07-31 23:07:19
本发明涉及计算机领域的文本自动处理,具体涉及一种多粒度语义增强表示的中文关键词抽取方法及装置。
背景技术:
1、关键词抽取是指从文本中自动抽取出主题性或重要性的词或短语,能帮助人们快速了解文档的主题思想和主要内容,是文本检索、文本摘要、意见挖掘、自动推荐等自然语言处理任务和信息检索任务的基础性和必要性工作。随着信息技术的发展,人们步入了信息爆炸时代,数据的快速增长远远超过了人类的阅读和理解能力,因此如何从大量文本数据中自动抽取出关键词是当下的研究重点和难点。
2、目前的关键词抽取方法主要是直接利用预训练语言模型从海量语料中学习到的通用语言表示来进行关键词抽取。虽然上述方法取得了很好的效果,但其还存在两方面的问题:一方面是存在无法根据下游任务特性进行领域适配的问题,目前的预训练语言模型主要是基于大规模通用领域语料训练的,这些通用领域的语料并不能涵盖下游任务的特定领域知识。当该类预训练语言模型应用于特定领域的关键词自动抽取任务中时,它们往往因为难以理解特定任务的具体需求而无法充分发挥其强大的语义表示作用,导致其抽取出任务相关关键词的准确性不高。另一方面是存在单模态信息语义表征能力有限的问题,目前的预训练语言模型主要是利用单一的文本数据进行训练,大都关注文本中词语之间的语义关系。但是中文是以象形为基础的文字,往往通过字形图像来表达物体、动作和抽象概念等的特征或本质。随着人们更多地关注汉字表达和传递的信息,汉字的字形逐渐从具体的物象转变为抽象的符号,这使得汉字中的部分偏旁部首用于表意。例如:“言”字表达了言语、说话的意义,在许多与言语相关的汉字中都可以找到“言”字作为偏旁部首。可以看出汉字图像和偏旁部首等多粒度信息能较好地辅助理解汉字,可以帮助中文自然语言处理模型获得更丰富、更全面的语义表征,而目前的关键词自动抽取模型并没有直接考虑这些多粒度信息。
技术实现思路
1、本发明要解决的技术问题:针对现有技术的上述问题,提供一种多粒度语义增强表示的中文关键词抽取方法及装置,本发明旨在基于包括偏旁部首信息、汉字图像信息的多粒度信息增强文本语义表示以提升中文关键词抽取任务的效果。
2、为了解决上述技术问题,本发明采用的技术方案为:
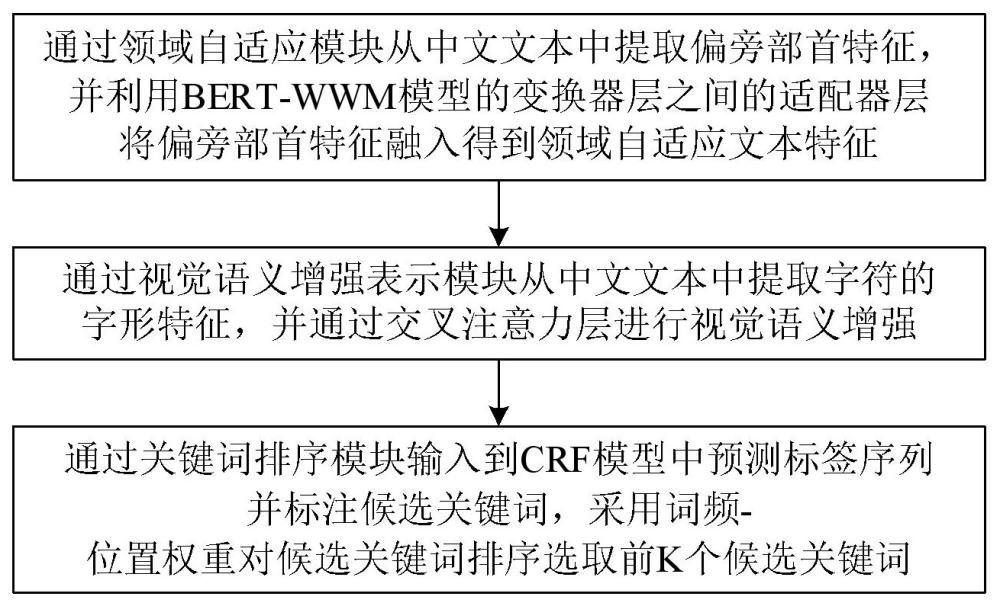
3、一种多粒度语义增强表示的中文关键词抽取方法,包括采用预先训练好的中文关键词抽取网络模型从输入的中文文本中提取关键词,所述中文关键词抽取网络模型包括依次相连的领域自适应模块、视觉语义增强表示模块和关键词排序模块,所述领域自适应模块用于从中文文本中提取偏旁部首特征,并利用bert-wwm模型的变换器层之间的适配器层将偏旁部首特征融入到bert-wwm模型,从而得到中文文本的领域自适应文本特征;所述视觉语义增强表示模块用于从中文文本提取字符的字形特征,并结合领域自适应模块输出的特征基于交叉注意力层进行视觉语义增强,所述关键词排序模块用于将视觉语义增强表示模块输出的视觉语义增强表示输入到crf模型中预测标签序列并标注候选关键词,采用词频-位置权重对crf模型标注出来的候选关键词进行排序,并选取前k个候选关键词作为从中文文本中提取的关键词。
4、可选地,所述从中文文本中提取偏旁部首特征包括:对于中文文本中的各个字符分别通过拆字词典获得其偏旁部首,并随机初始化偏旁部首的特征获得偏旁部首向量矩阵;采用大小为 k的卷积核在偏旁部首向量矩阵上以指定的步长滑动进行二维卷积操作,最后通过最大池化层得到偏旁部首特征。
5、可选地,所述适配器层包括前馈层、连接层和层归一化层,所述前馈层用于将从中文文本中提取偏旁部首特征与bert-wwm模型中上一层变换器层输出的特征进行对齐,所述连接层用于将bert-wwm模型中上一层变换器层输出的特征、对齐后的偏旁部首特征连接以实现特征融合,所述层归一化层用于将融合后的特征进行层归一化处理后输出以作为bert-wwm模型中下一层变换器层的输入。
6、可选地,所述从中文文本中提取字符的字形特征包括:对于中文文本中的各个字符分别获取不同时期和不同写作风格的文字图片得到图片序列,然后将图片序列中的图片输入到预先训练好的卷积神经网络cnn中提取字形特征,所述卷积神经网络cnn包括依次相连的卷积层、最大池化层和分组卷积层,卷积神经网络cnn中提取字形特征包括:通过卷积层用指定大小的卷积核进行卷积以捕获较低级的图形特征,接着通过最大池化层执行最大池化操作将较低级的图形特征降为2×2大小以捕获更小尺度的特征,最后通过分组卷积层用分组卷积得到图片的字形表征向量作为字形特征。
7、可选地,所述卷积神经网络cnn在训练时使用的损失函数的函数表达式为:
8、,
9、上式中, lossglyph表示卷积神经网络cnn在训练时使用的损失函数, q表示训练数据集中第 i个图像 vi的真实标签, p( q| vi)表示样本 vi在分类 q下的条件概率。
10、可选地,所述结合领域自适应模块输出的特征基于交叉注意力层进行视觉语义增强包括:首先将领域自适应模块输出的特征 hl作为交叉注意力机制的查询,将从中文文本中提取的字形特征 eglyph分别作为交叉注意力机制的键和值,通过执行交叉注意力机制得到视觉增强的注意输出特征 ev;然后将领域自适应模块输出的特征 hl和视觉增强的注意输出特征 ev连接起来输入到前馈神经网络中,获得最终输出的视觉语义增强表示。
11、可选地,所述将视觉语义增强表示模块输出的视觉语义增强表示输入到crf模型中预测标签序列并标注候选关键词,采用词频-位置权重对crf模型标注出来的候选关键词进行排序,并选取前k个候选关键词作为从中文文本中提取的关键词包括:
12、步骤1,将视觉语义增强表示模块输出的视觉语义增强表示输入到crf模型中预测标签序列,其中 y1~ yn分别表示第1~ n个预测标签, n为预测标签序列长度;给定一组输入序列,crf模型通过最大化训练数据的对数似然函数学习输入特征和标签之间的关系,得到如下式所示的 m个标签序列的条件概率:
13、,
14、上式中,为条件概率,为输入序列,为输出标签序列,为第 i个标签序列的权重 ,为第 i个标签序列的打分函数;
15、步骤2,使用维特比解码最大化条件概率,根据下式计算概率最大的标签序列作为标注出来的候选关键词输出:
16、,
17、上式中,为概率最大的预测标签序列;
18、步骤3,针对crf模型标注出来的候选关键词根据下式计算词频权重:
19、,
20、上式中,为第i个候选关键词的词频权重,为第i个候选关键词在输入的中文文本中的出现次数,为输入的中文文本中所有词条项的总数量;针对crf模型标注出来的候选关键词根据下式计算位置权重:
21、,
22、上式中,为第i个候选关键词的位置权重,为第i个候选关键词的第一次出现在输入的中文文本中的位置,为常数系数;
23、步骤4,首先根据下式计算各个候选关键词的词频权重:
24、,
25、上式中,为第i个候选关键词的词频权重;然后根据词频权重对crf模型标注出来的候选关键词进行排序并选取前k个候选关键词作为从中文文本中提取的关键词。
26、此外,本发明还提供一种多粒度语义增强表示的中文关键词抽取装置,包括相互连接的微处理器和存储器,所述微处理器被编程或配置以执行所述多粒度语义增强表示的中文关键词抽取方法。
27、此外,本发明还提供一种计算机可读存储介质,该计算机可读存储介质中存储有计算机程序/指令,该算机程序/指令被编程或配置以通过处理器执行所述多粒度语义增强表示的中文关键词抽取方法。
28、此外,本发明还提供一种计算机程序产品,包括计算机程序/指令,该算机程序/指令被编程或配置以通过处理器执行所述多粒度语义增强表示的中文关键词抽取方法。
29、和现有技术相比,本发明主要具有下述优点:目前关键词抽取任务主要依赖于预训练语言模型来获取文本表示,这类语言模型主要基于单一模态的通用文本语料进行训练,存在无法根据下游任务特性进行领域适配和语义表征能力有限的问题。针对上述问题,本发明提出一种多粒度语义增强表示的中文关键词抽取方法,该方法将关键词抽取任务转化为序列标注任务,首先引入adapter层将偏旁部首信息集成到预训练语言模型层中,得到领域自适应的文本表示;其次利用卷积神经网络提取汉字的图像特征,同时使用交叉注意力机制融合汉字图像特征和文本特征,实现文本语义表示增强;最后在此基础上利用crf进行序列标注任务,并计算候选关键词的位置-词频权重对其进行排序,将前n个候选关键词作为文本的关键词。在自构建的数据集上进行实验,结果表明,本发明方法与几类基准关键词抽取方法相比,准确率与召回率都有显著提高,同时通过消融实验进一步证明了本发明方法所提的领域自适应模块和视觉语义增强模块均能够有效的提高关键词抽取的准确性。
本文地址:https://www.jishuxx.com/zhuanli/20240730/196059.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。