一种数据库无关的执行计划成本估算器及方法与流程
- 国知局
- 2024-07-31 23:12:28
本发明涉及数据库查询优化,特别涉及一种数据库无关的执行计划成本估算器及方法。
背景技术:
1、代价估计在资源分配和数据库查询优化等许多领域中扮演着关键角色。传统的数据库优化器对查询进行了很多假设简化,使用启发式算法来计算查询计划的代价,虽然保证了估计的效率,但准确性不够理想。近年来,许多研究人员尝试将机器学习(ml)技术应用于代价估计,以实现更准确的预测。与传统方法相比,基于ml的方法在一些公开数据集上表现得更好,但也仍然存在着许多限制。
2、首先是鲁棒性不足的问题。在基于单一数据库的模型(wdms)中,模型的训练和测试都是在同一个数据库上进行的,在单一数据库上有着不错的准确性,但其准确预测能力高度依赖于训练时使用的工作负载,当面对新的、未见过的工作负载(out ofdistribution,ood)时,模型的预测能力会明显下降。此外,在实践中,选择适合用于训练wdms的查询集也非常困难,基于此,一些方法选择通过重新训练来提高wdms在新工作负载上的准确性,但何时重新训练以及如何收集用于重新训练的数据(即冷启动问题)同样不容易解决,并且,实际应用中还经常出现数据漂移等问题。因此,wdms鲁棒性不足的限制可能导致其在应用于数据库管理系统(dbms)时出现安全问题,如生成次优的执行计划或错误的调度。
3、其次是准确性不足的问题。近年来,跨数据库模型(adms)引起了许多研究人员的关注。adms在不同数据库和工作负载上进行训练和测试(即在未见过的数据库上进行测试),以提高其泛化能力。相对于wdms,adms具有更强大的泛化能力。然而,adms无法像wdms一样有效地优化单个数据库(也称为实例优化),因此adms的准确性通常无法满足商业dbms的要求。
4、最后是效率低下的问题。现有的代价估计模型在效率方面(包括训练效率和推断效率)很难满足商业dbms的需求。对于推断效率,要么将模型嵌入到dbms中以获得更好的执行计划选择,要么进行查询性能预测(qpp)以实现资源调度。这两种方法都需要具有高推断速度的代价估计模型。而对于训练效率,训练速度更快的模型可以更容易地进行重新训练或微调,以适应更复杂和变化的场景。然而,为了获得更高的准确性,大多数基于ml的代价估计模型都选择牺牲了效率。特别是许多adms为了学习不同的数据库信息,通常会构建复杂的模型,导致效率低于wdms。
技术实现思路
1、本发明的目的在于提供一种数据库无关的执行计划成本估算器及方法,解决了现有技术存在代价估计的鲁棒性与高效性不足的问题。
2、为实现上述目的,本发明采用的技术方案如下:
3、一种数据库无关的执行计划成本估算器,其特征在于,包括:
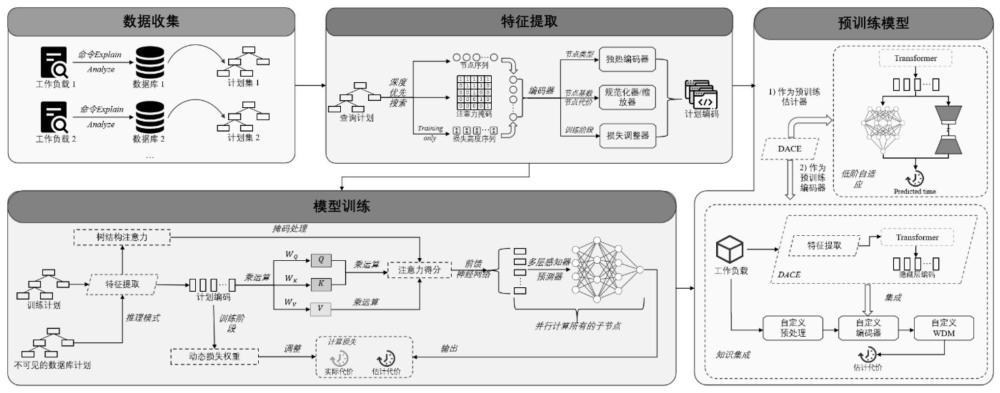
4、数据收集模块,用于存储查询语句,并可生成查询计划树,该查询计划树中包含每个节点的预估执行代价和预估基数;
5、特征提取模块,用于从查询计划树中提取预估执行代价和预估基数,并获取与查询计划树对应的节点序列,以及树结构注意力掩码和节点高度序列,然后对节点序列的节点类型、节点预估代价和预估基数进行编码,并输出计划编码;
6、代价估计模块,用于对计划编码进行掩码处理和获得隐藏层编码,然后并行预测所有子计划的代价,输出整个计划树的预估代价;
7、预训练模块,用于某个范围的训练集训练后,将其直接部署在跨数据库环境中进行代价估计;以及输出查询计划中可迁移的隐藏信息,为特征提取模块提供编码依据。
8、具体地,所述数据收集模块使用dbms的查询优化器生成查询计划树。
9、具体地,所述特征提取模块包括信息捕获器和编码器;所述信息捕获器使用深度优先搜索来获得节点序列、邻接矩阵和节点高度,以及树结构注意力掩码和节点高度序列;所述编码器包括独热编码器、缩放器,所述独热编码器对节点序列的节点类型进行编码,所述缩放器用于对节点预估代价和预估基数进行编码。
10、进一步地,所述编码器还包括损耗调整器,该损失调整器用于在训练阶段基于节点的高度序列,计算每个节点的损失权重。
11、具体地,所述代价估计模块包括注意力机制模块、多层感知机和损失调整器,其中,注意力机制模块用于处理特征模块输出的计划编码,并添加树结构的注意力矩阵来进行掩码处理;多层感知机用于获得隐藏层编码,然后并行预测所有子计划的代价;损失调整器用于输出动态损失权重。
12、基于上述成本估算器,本发明还提供了一种数据库无关的执行计划成本估算方法,包括以下步骤:
13、(1)根据现有的公开数据集,利用查询语句生成查询计划树,该查询计划树中包含每个节点的预估执行代价和预估基数;
14、(2)从查询计划树中提取预估执行代价和预估基数,并获取与查询计划树对应的节点序列,以及树结构注意力掩码和节点高度序列,然后对节点序列的节点类型、节点预估代价和预估基数进行编码,并输出计划编码;该步骤中,基于查询计划进行训练,输出查询计划中可迁移的隐藏信息,为计划编码提供依据,其定义如下:
15、ωout=mlpout([ωt,ωj,ωp,ωe]),
16、其中,ωt,ωj和ωp分别表示查询的表、连接条件和谓词信息;ωe表示mlp的第2个网络层输出的隐藏层;
17、(3)使用自注意力机制处理计划编码,并添加树结构的注意力矩阵来进行掩码处理,定义如下:
18、
19、其中,s∈rn×d是编码器输出的节点编码序列,n是节点个数,d是节点编码的长度。和分别表示查询键值和值的参数矩阵,kt表示k的转置矩阵,dk表示查询和键值的维度,dv表示值的维度,m∈rn×n作为注意力掩码矩阵,从邻接矩阵a导出;
20、(4)利用多层感知机获得隐藏层编码,然后并行预测所有子计划的代价,定义如下:
21、est_cost(subp)=mlp(attention(q,k,v))
22、其中,subp表示p的所有子计划,mlp由三层全连通线性网络组成;
23、(5)输出整个计划树的预估代价;该步骤中,利用预训练估计方法使预估代价适应跨数据库场景。
24、具体地,所述步骤(1)中,使用dbms的查询优化器生成查询计划树。
25、具体地,所述步骤(2)中,输出计划编码的过程如下:
26、(a)利用深度优先搜索获取与查询计划树对应的节点序列,同时获得树结构注意力掩码和节点高度序列,其中,树结构注意力掩码为一个n×n的邻接矩阵,定义如下:
27、
28、其中,nodei是深度优先搜索获取的节点序列中的第i个节点,a(p)i,j表示树结构注意力掩码矩阵的第i行第j列,当nodei是nodej本身或者nodei是nodej祖先节点时,定义nodei≤nodej;
29、(b)基于节点的高度序列,计算每个节点的损失权重,定义如下:
30、
31、其中,lp表示查询计划树上节点p的损失权重,hp表示节点p的高度,α表示超参数;
32、(c)分别对节点序列的节点类型、节点预估代价和预估基数进行编码。
33、进一步地,所述步骤(4)中,还通过动态损失权重计算损失,定义如下:
34、
35、其中,lp,i表示第i个节点的损失权重,est_cost和cost分别表示估计代价和实际代价,est_cost(subp)i和cost(subp)i分别表示subp的第i个节点的估计代价和实际代价。
36、具体地,所述步骤(5)中,预训练估计方法的定义如下:
37、
38、其中,表示mlp的第i个网络层的权重,表示第i个网络层输出的隐藏层,δwi、均为lora模型的参数。
39、与现有技术相比,本发明具有以下有益效果:
40、(1)本发明设计了一种轻量级数据库无关的代价估计器,相比现有的代价估计模型,本发明利用树结构的注意力机制来促进子计划的并行预测,因而无需依赖于特定数据集的数据特征,而是专注于查询优化器估计代价的误差分布,并且能够适应各种偏移场景(包括数据偏移和跨数据库场景等),解决了现有模型的鲁棒性与高效性不足的问题。
41、(2)本发明采用树结构的损失调整策略进行设计,有效提高了模型的预测准确性,实验表明,即使不利用任何数据库知识,本发明也能在特定数据库上的表现优于传统的代价估计模型。
42、(3)本发明利用transformer的结构和树结构的注意力掩码来实现子计划的并行预测,能够高效地获得查询计划中所有子计划的估计代价,其原因在于,在transformer中,模型使用注意力机制并行的计算每个节点的隐藏状态,并考虑了树结构信息以获得准确的预测;在mlp中,模型可以并行地使用注意力来预测子计划的代价。
43、(4)本发明引入了节点的损失权重计算,通过使子节点具有较小的损失权重来防止子节点的重复学习,从而更好地利用查询计划中的知识。
44、(5)本发明还引入了动态损失权重计算,基于树结构的损失调整策略结合qerror(一种代价估计中的通用评价指标),可以为具有较大高度的节点设置较低的损失权重。
45、(6)本发明基于低秩适应(lora)设计了预训练估计方法,其是一种轻量级的微调方法,可以通过微小的微调成本令代价估计适应更多场景。
46、(7)本发明基于查询计划进行训练,可以输出查询计划中可迁移的隐藏信息,如此,本发明利用adms的知识来提高了wdms的性能,能为所有wdms提供先验知识(也称为上下文),有效地解决了wdms面临的冷启动和ood(out-of-domain)问题。
本文地址:https://www.jishuxx.com/zhuanli/20240730/196409.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表