一种基于海量大数据的青藏高原公里级土壤水分反演工作方法
- 国知局
- 2024-07-31 23:16:36
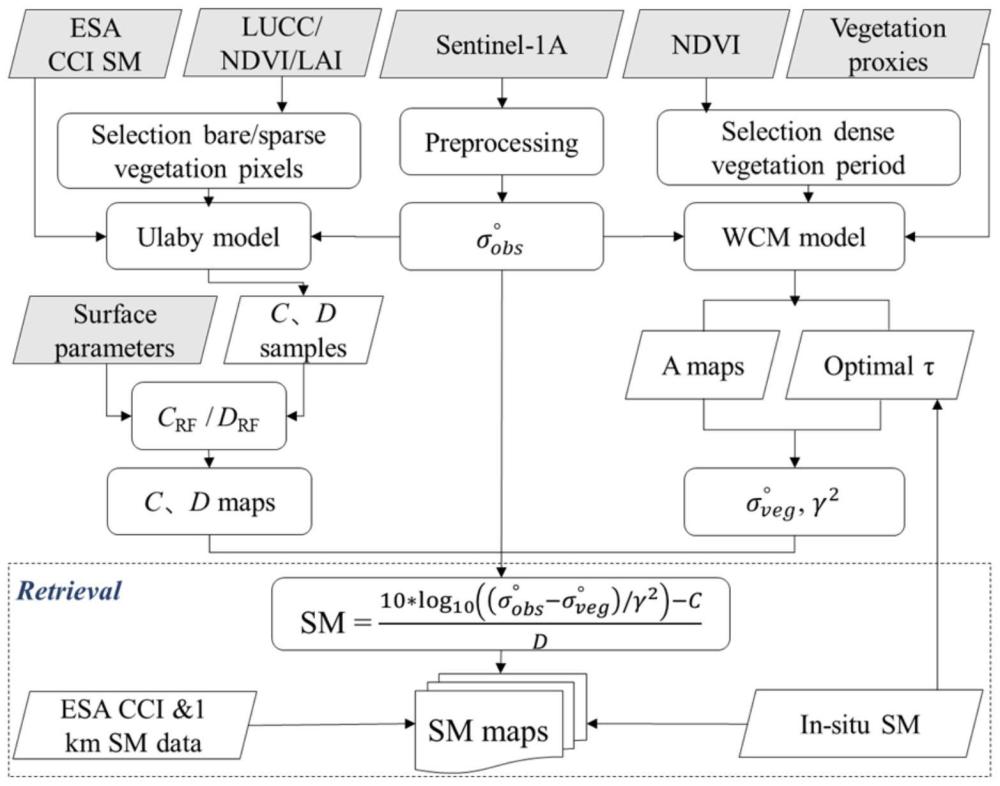
本发明涉及一种土壤水分,特别是涉及一种基于海量大数据的青藏高原公里级土壤水分反演工作方法。
背景技术:
1、青藏高原不仅是长江、黄河、雅鲁藏布江和澜沧江等主要河流的发源地,也是湖泊和湿地的主要聚集地,被誉为“亚洲水塔”。同时,青藏高原平均海拔4000m以上,是世界上平均海拔最高的高原,也是中、低纬度地区多年冻土分布最广泛的地区。在气候变暖大背景下,青藏高原多年冻土发生着不同程度的退化,主要表现为多年冻土温度升高、活动层增厚、浅表层多年冻土及其中的地下冰逐渐融化为液态水,进而影响着寒区地表径流形成以及地下水的运移过程和分布格局。土壤水分不仅是青藏高原地区联系地表水、地下水、大气水和植被水的关键地表参量,也通过土壤热容量、地表蒸散等过程对陆面能水进行再分配,进而改变地表向大气输送的水热通量。因此,如何获取青藏高原地区大范围准确的高分辨率土壤水分对于理解该区域乃至全球的气候和能水循环具有重要作用。
技术实现思路
1、本发明旨在至少解决现有技术中存在的技术问题,特别创新地提出了一种基于海量大数据的青藏高原公里级土壤水分反演工作方法。
2、为了实现本发明的上述目的,本发明提供了一种基于海量大数据的青藏高原公里级土壤水分反演工作方法,包括以下步骤:
3、s1,获取采集的多源遥感观测和土壤水分大数据;
4、s2,根据步骤s1中采集的土壤水分大数据从空间尺度上优化土壤和植被参数以得到空间土壤参数;
5、s3,从光学、主动和被动微波数据之一或者任意组合中选用不同的植被代用指标进行筛选以得到植被光学厚度;
6、s4,根据植被覆盖区的站点土壤水分数据,校正并获取适用于高寒草地区域的植被含水量。
7、在本发明的一种优选实施方式中,在步骤s1中采集土壤水分大数据的方法包括野外观测资料、土壤水分产品数据集、sentinel-1后向散射数据、其他辅助数据之一或者任意组合。
8、在本发明的一种优选实施方式中,在步骤s2中采用空间降尺度、主动微波遥感实现土壤和植被参数优化。
9、在本发明的一种优选实施方式中,在步骤s4中,含水量的计算方法为:
10、
11、其中,代表在参考入射角θref归一化得到的后向散射;
12、代表在局部入射角θ观测到的后向散射;
13、θref表示参考入射角;
14、θ表示局部入射角;
15、
16、其中,代表雷达接收到的总后向散射;
17、代表植被后向散射;
18、γ2为植被穿透系数;
19、代表土壤后向散射;
20、
21、其中,代表植被后向散射;
22、a代表全植被覆盖下的植被冠层后向散射;
23、v1表示植被参数;
24、θref为参考入射角;
25、γ2为植被穿透系数;
26、
27、其中,γ2为植被穿透系数;
28、e为自然底数;
29、τ为植被光学厚度;
30、θref为参考入射角;
31、τ=b×vwc (2.13)
32、其中,τ为植被光学厚度;
33、b是依赖于植被冠层类型的经验参数;
34、vwc为植被含水量;
35、
36、其中,代表土壤后向散射;
37、c是土壤参数,代表干燥土壤条件下的后向散射;
38、d是土壤参数,代表后向散射对土壤水分的敏感性;
39、sm表示土壤水分参数;
40、
41、其中,sm表示土壤水分参数;
42、代表雷达接收到的总后向散射;
43、代表植被后向散射;
44、γ2为植被穿透系数;
45、c和d是土壤参数。
46、在本发明的一种优选实施方式中,土壤参数c和d的校正方法为:
47、筛选裸地和稀疏植被区像元;
48、计算已筛选像元的土壤参数。
49、在本发明的一种优选实施方式中,还包括校正整个研究区域的土壤参数。
50、在本发明的一种优选实施方式中,植被参数a的校正方法为:
51、
52、其中,代表雷达接收到的总后向散射;
53、代表植被后向散射;
54、adense(t,i,j)表示密集植被期的植被参数;
55、θref为参考入射角;
56、
57、其中,a(t)表示第t天密集植被像元上所有adense(t,i,j)值的空间平均值;
58、adense(t,i,j)表示密集植被期的植被参数;
59、∑adense(t,i,j)表示第t天密集植被像元上所有adense(t,i,j)值之和;
60、a代表全植被覆盖下的植被冠层后向散射。
61、在本发明的一种优选实施方式中,还包括评估指标,评估指标包括平均偏差、皮尔逊相关系数、均方根误差、无偏均方根误差之一或者任意组合;
62、平均偏差计算公式为:
63、
64、其中,bias表示平均偏差;
65、n代表数据总个数;
66、代表产品土壤水分数据;
67、代表观测土壤水分数据;
68、皮尔逊相关系数计算公式为:
69、
70、其中,r表示皮尔逊相关系数;
71、n代表数据总个数;
72、代表产品土壤水分数据;
73、代表产品土壤水分数据的平均值;
74、代表观测土壤水分数据;
75、代表观测土壤水分数据的平均值;
76、均方根误差计算公式为:
77、
78、其中,rmse表示均方根误差;
79、n代表数据总个数;
80、代表产品土壤水分数据;
81、代表观测土壤水分数据;
82、无偏均方根误差计算公式为:
83、
84、其中,ubrmse表示无偏均方根误差;
85、rmse表示均方根误差;
86、bias表示平均偏差。
87、在本发明的一种优选实施方式中,植被含水量vwc的校正方法为以下之一:
88、
89、其中,vwc为植被含水量;
90、a1、a2、b1、b2表示为植被含水量公式拟合系数;
91、ndvi表示归一化植被指数;
92、vwc=a×ndvi2–b×ndvi+c×(((ndvimax-ndvimin)/(1-ndvimin))),
93、其中,vwc为植被含水量;
94、a、b、c表示植被含水量公式拟合系数;
95、ndvi表示归一化植被指数;
96、ndvimax表示像元归一化植被指数最大值;
97、ndvimin表示像元归一化植被指数最小值。
98、vwc=exp(lai/a3)-b3
99、其中,vwc为植被含水量;
100、其中,lai表示叶面积指数;
101、a3、b3表示植被含水量公式拟合系数;
102、vwc=a4*ndwi+b4
103、其中,vwc为植被含水量;
104、a4、b4表示植被含水量公式拟合系数;
105、ndwi表示归一化差值水体指数;
106、vwc=a5*ndwi2+b5*ndwi+c5
107、其中,vwc为植被含水量;
108、a5、b5、c5表示植被含水量公式拟合系数;
109、ndwi表示归一化差值水体指数;
110、vwc=a6*rvi+b6
111、
112、其中,vwc为植被含水量;
113、a6、b6、c6表示植被含水量公式拟合系数;
114、表示vh极化后向散射;
115、表示vv极化后向散射;
116、smap-l3 dca vod表示smap l3级产品dca算法计算得到的植被光学厚度产品数据。
117、在本发明的一种优选实施方式中,植被含水量vwc的校正方法为:
118、vwc=a×ndvi2–b×ndvi+c×(((ndvimax-ndvimin)/(1-ndvimin))),其中,vwc为植被含水量;
119、a、b、c表示植被含水量公式拟合系数;
120、ndvi表示归一化植被指数;
121、ndvimax表示像元归一化植被指数最大值;
122、ndvimin表示像元归一化植被指数最小值。
123、在本发明的一种优选实施方式中,还包括为了保障公里级土壤水分反演工作方法的安全性,防止在传输过程中公里级土壤水分反演工作方法的泄露,还包括以下步骤:
124、s5,将步骤s1~s4中的公里级土壤水分反演工作方法进行加密,加密后通过u盘、移动硬盘或者网络进行数据的传输;
125、s6,需要使用公里级土壤水分反演工作方法时,对其加密的公里级土壤水分反演工作方法进行解密进行使用。
126、综上所述,由于采用了上述技术方案,本发明能够实现对青藏高原地区大范围准确的高分辨率土壤水分含量进行识别。
127、本发明的附加方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
本文地址:https://www.jishuxx.com/zhuanli/20240730/196758.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。