一种自适应局部环境变化的救援机器人轨迹规划方法
- 国知局
- 2024-08-01 00:22:16
本发明涉及机器人轨迹规划领域,尤其是涉及一种自适应局部环境变化的救援机器人轨迹规划方法。
背景技术:
1、随着智能算法的发展和机器人的高效作业能力,救援机器人用于应对危险且时间紧迫的灾区救援任务被给予了厚望。但由于复杂且多变的工作环境,能够规划一条合理且高效的施救轨迹是被救援机器人所需要的。
2、现有的轨迹规划算法有人工势场法、搜索算法和智能算法。人工势场法需要提前预定义障碍物的斥力函数和到达目的的引力函数,由于受灾区复杂的障碍物构成,这使得提前预定义可能遇见的所有障碍物类型是难以实现的,限制了斥力与引力函数的权衡设置。搜索算法又可以分为基于采样的搜索算法(概率路线图和重复探索随机树)和基于启发式的搜索算法(dijkstra算法和a*搜索方法)。基于采样的搜索算法尽管具备处理环境变化的情况,但是由于采用的随机性其应对环境变化的能力有限。基于启发式的搜索算法存在搜索效率和局部最优导致的目的地到达困难的矛盾。此外,与基于马尔科夫决策构建的智能决策算法一样,依赖与对地图的探索经验,对于变化的环境需要重新探索,显著降低了在高度变化的受灾区环境的适应性。
技术实现思路
1、本发明的目的是为了提高救援机器人在高度变化的受灾区的作业效率和成功率,而提供一种兼顾效率和自适应能力的自适应局部环境变化的救援机器人轨迹规划方法。
2、本发明的目的可以通过以下技术方案来实现:
3、一种自适应局部环境变化的救援机器人轨迹规划方法,包括以下步骤:
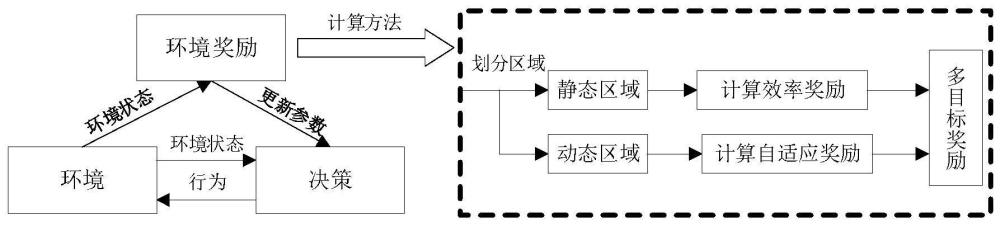
4、确定救援机器人的引导路线,并根据途径区域是否受到灾害的持续影响将地图划分为静态区域和动态区域;
5、构建用于救援机器人轨迹规划的强化学习网络,所述强化学习网络在静态区域基于效率奖励函数引导网络,以保证救援机器人的行驶效率,在动态区域基于自适应奖励函数引导网络,以应对变化的受灾区域;
6、通过网络与环境的不断交互,利用强化学习网络生成救援机器人规划轨迹。
7、所述引导路线为仅包含方向性和必须经过的勘测点的路线。
8、所述效率奖励函数用于指导救援机器人快速到达救援区域,所述效率奖励函数依据救援机器人与救援区域之间的相对距离构建,且与相对距离成反向变化关系,表示为:
9、re=(dba0-dbai)
10、
11、
12、式中:re为效率奖励值;dba0为初始环境下救援机器人与救援区域的距离;dbai为第i时刻下救援机器人与救援区域的距离;(xa,ya)为救援区域位置坐标,(x0,y0)为初始环境下救援机器人位置坐标,(xi,yi)为第i时刻下救援机器人位置坐标。
13、所述自适应奖励函数用于引导救援机器人应对变化的受灾区域,通过尽可能的遍历变化区域来保证到达率,所述自适应奖励函数包括方向适应性奖励和轨迹适应性奖励。
14、在动态区域的中心点构建坐标系,将动态区域分割为四个部分,分别对应4个方向的探索,即前左、前右、后左以及后右,通过期望分布和实际分布的kl散度构建方向适应性奖励,公式如下:
15、
16、式中:qd(x)为期望的到达方向分布,初步定义为qd(x)=[0.25,0.25,0.25,0.25];pd(x)为实际达到区域分布;rd为定义的方向适应性奖励。
17、所述轨迹适应性奖励的作用是在单一通道被毁的情况,引导救援机器人变更原有的轨迹,而不更改到达的方向,通过期望分布和实际分布的kl散度构建轨迹适应性奖励,公式如下:
18、
19、式中:qp(x)为期望的历史位置分布,初步定义为均匀分布,即qp(x)=n/n;其中n为经过动态区域位置的总次数,n为实际探索过程中发现的动态区域位置数量;pp(x)为实际历史位置分布,即pp(x)=m/n;其中m为某一动态区域位置实际发生的次数;rp为定义的轨迹适应性奖励;其中,所述动态区域位置是基于位置识别精度划分动态区域后的一个方格中心坐标,计数代表的是到达一个方格的次数。
20、所述强化学习网络的基础参数定义如下:
21、状态空间s:表示救援机器人可能处于的状态集合,即s∈s,s为具体的一个环境状态元素;
22、行动空间a:表示救援机器人可以执行的行动集合,即a∈a,a为具体的一个救援机器人操作行为;
23、状态转移函数p(s′|s,a):表示从状态s执行行动a后转移到状态s′的概率,在环境中救援机器人的状态转移严格受到动力学约束,则其被假定为确定性环境,即p(s′|s,a)=1;
24、奖励函数r(s,a,s′):表示在状态s执行行动a后转移到状态s′时的奖励,包括效率奖励和自适应奖励。
25、所述强化学习网络采用a2c,包括一个策略网络和一个价值网络。
26、所述策略网络的作用是指导救援机器人决定在环境状态为s时,确定采用的行为a,以快速到达救援区域,用π(a|s,θ)表示,其中π(·)表示被定义的决策网络,θ是网络中需要学习的参数,策略更新的目的是最大限度地减少策略损失,表示为负预期优势函数与决策概率对数的乘积,具体的计算公式如下:
27、
28、a(s,a)=q(s,a)-v(s)
29、式中:a(s,a)为定义的优势函数计算方法,q(s,a)为行为-状态奖励,表示在状态s下采取行动a的奖励,v(s)为转移到状态s时的状态奖励,l(θ)为定义的策略网络损失计算函数。
30、所述价值网络的作用是学习环境中实际奖励的分布,用于指导策略网络的更新,用表示,是网络中需要学习的参数,价值网络的损失函数通过最小化状态奖励函数的估计误差构建,具体的计算公式如下:
31、
32、式中:r(st,at,s′t)为人为定义的环境奖励,为实际值;为价值网络对环境奖励的估计值;其中t表示从初始环境开始,决策次数的序号;为定义的价值网络损失计算函数。
33、与现有技术相比,本发明具有以下有益效果:
34、本发明对强化学习网络设置了多目标奖励函数,在静态区域构建了效率奖励,以保证救援机器人的行驶效率,在动态区域构建了方向适应性奖励和轨迹适应性奖励,以应对受灾区域障碍物的巨大变化和微小变化,从而能够兼顾效率和自适应性能力,提高了救援机器人在高度变化的受灾区的作业效率和成功率。
技术特征:1.一种自适应局部环境变化的救援机器人轨迹规划方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的一种自适应局部环境变化的救援机器人轨迹规划方法,其特征在于,所述引导路线为仅包含方向性和必须经过的勘测点的路线。
3.根据权利要求1所述的一种自适应局部环境变化的救援机器人轨迹规划方法,其特征在于,所述效率奖励函数用于指导救援机器人快速到达救援区域,所述效率奖励函数依据救援机器人与救援区域之间的相对距离构建,且与相对距离成反向变化关系,表示为:
4.根据权利要求1所述的一种自适应局部环境变化的救援机器人轨迹规划方法,其特征在于,所述自适应奖励函数用于引导救援机器人应对变化的受灾区域,通过尽可能的遍历变化区域来保证到达率,所述自适应奖励函数包括方向适应性奖励和轨迹适应性奖励。
5.根据权利要求4所述的一种自适应局部环境变化的救援机器人轨迹规划方法,其特征在于,在动态区域的中心点构建坐标系,将动态区域分割为四个部分,分别对应4个方向的探索,即前左、前右、后左以及后右,通过期望分布和实际分布的kl散度构建方向适应性奖励,公式如下:
6.根据权利要求4所述的一种自适应局部环境变化的救援机器人轨迹规划方法,其特征在于,所述轨迹适应性奖励的作用是在单一通道被毁的情况,引导救援机器人变更原有的轨迹,而不更改到达的方向,通过期望分布和实际分布的kl散度构建轨迹适应性奖励,公式如下:
7.根据权利要求1所述的一种自适应局部环境变化的救援机器人轨迹规划方法,其特征在于,所述强化学习网络的基础参数定义如下:
8.根据权利要求7所述的一种自适应局部环境变化的救援机器人轨迹规划方法,其特征在于,所述强化学习网络采用a2c,包括一个策略网络和一个价值网络。
9.根据权利要求8所述的一种自适应局部环境变化的救援机器人轨迹规划方法,其特征在于,所述策略网络的作用是指导救援机器人决定在环境状态为s时,确定采用的行为a,以快速到达救援区域,用π(a|s,θ)表示,其中π(·)表示被定义的决策网络,θ是网络中需要学习的参数,策略更新的目的是最大限度地减少策略损失,表示为负预期优势函数与决策概率对数的乘积,具体的计算公式如下:
10.根据权利要求8所述的一种自适应局部环境变化的救援机器人轨迹规划方法,其特征在于,所述价值网络的作用是学习环境中实际奖励的分布,用于指导策略网络的更新,用表示,是网络中需要学习的参数,价值网络的损失函数通过最小化状态奖励函数的估计误差构建,具体的计算公式如下:
技术总结本发明涉及一种自适应局部环境变化的救援机器人轨迹规划方法,包括以下步骤:确定救援机器人的引导路线,并根据途径区域是否受到灾害的持续影响将地图划分为静态区域和动态区域;构建用于救援机器人轨迹规划的强化学习网络,所述强化学习网络在静态区域基于效率奖励函数引导网络,以保证救援机器人的行驶效率,在动态区域基于自适应奖励函数引导网络,以应对变化的受灾区域;通过网络与环境的不断交互,利用强化学习网络生成救援机器人规划轨迹。与现有技术相比,本发明通过精细设计的差异化多目标奖励优化强化学习,在保证救援机器人作业效率的情况下,显著的提高了在局部受灾区域变化情况下的完成概率。技术研发人员:孟强,张琳,陈虹受保护的技术使用者:同济大学技术研发日:技术公布日:2024/7/29本文地址:https://www.jishuxx.com/zhuanli/20240730/200789.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。