基于领域泛化机器学习的多层合采油藏动态产量劈分方法
- 国知局
- 2024-07-31 22:35:40
本发明属于石油工程领域,具体涉及一种基于领域泛化机器学习的多层合采油藏动态产量劈分方法。
背景技术:
1、油井产量劈分在多层合采油藏精细描述及开发中的起着关键性作用。受层间储层物性差异的影响,多层合采油藏在开发过程中层间干扰严重,层间动用程度差异大,导致油藏各个油层的产量分布不均匀,影响油井产能释放以及整体开采效率。因此,制定科学合理的产量劈分方案对提高多层非均质油藏动态开发的生产效率至关重要。
2、油井产量劈分传统方法主要包括地层系数法、突变理论法、数值模拟法。地层系数法通过对地质参数和产液参数的统计分析来估计油井产量。但地层系数的确定通常依赖于一些假设,且对于复杂的油田系统,地层系数无法准确反映地层的真实情况。突变理论法通过突变理论来描述油井产量的变化情况。然而,在实际应用中,突变理论的参数估计通常需要大量的数据,并且往往对数据的要求较高,对数据的噪声和不确定性较为敏感。数值模拟法通过建立复杂的地质模型和流体动力学模型来模拟油井产量的变化。尽管数值模拟法可以考虑到更多的影响因素,并且可以更好地描述油田系统的复杂性,但其计算量较大,模型参数估计和模型验证需要大量的时间和资源投入,且模型的参数化过程可能会引入额外的数据不确定性。
3、多层合采油藏油田系统通常具有复杂的时空结构,数据涉及地质参数、产液参数、生产动态参数。这些动静态参数之间复杂的时空关系对油井每小层的产量分布和动态变化产生重要影响;由于多层合采油藏处于不同地理位置,导致各地域的数据分布存在显著差异,增加了数据的不确定性;kh产量劈分值是衡量地层孔隙空间的一个关键参数,代表着地层产能潜力指标,但不同地质条件下的kh值也有明显差异,导致传统模型过度依赖这一参数,忽略了其他重要参数的影响。综上,传统产量劈分方法,在应对动静态参数复杂时空结构、数据不确定性和对kh劈分值过度依赖时面临着巨大挑战。
技术实现思路
1、为了解决多层合采油藏动态产量预测中动静态参数复杂时空结构、数据不确定性以及对kh劈分值过度依赖问题,本发明提出了一种基于领域泛化机器学习的多层合采油藏动态产量劈分方法,能够对多层合采油藏产量分布和动态变化进行准确预测,从而为油田的生产管理和优化提供可靠的支持和指导。
2、本发明的技术方案如下:
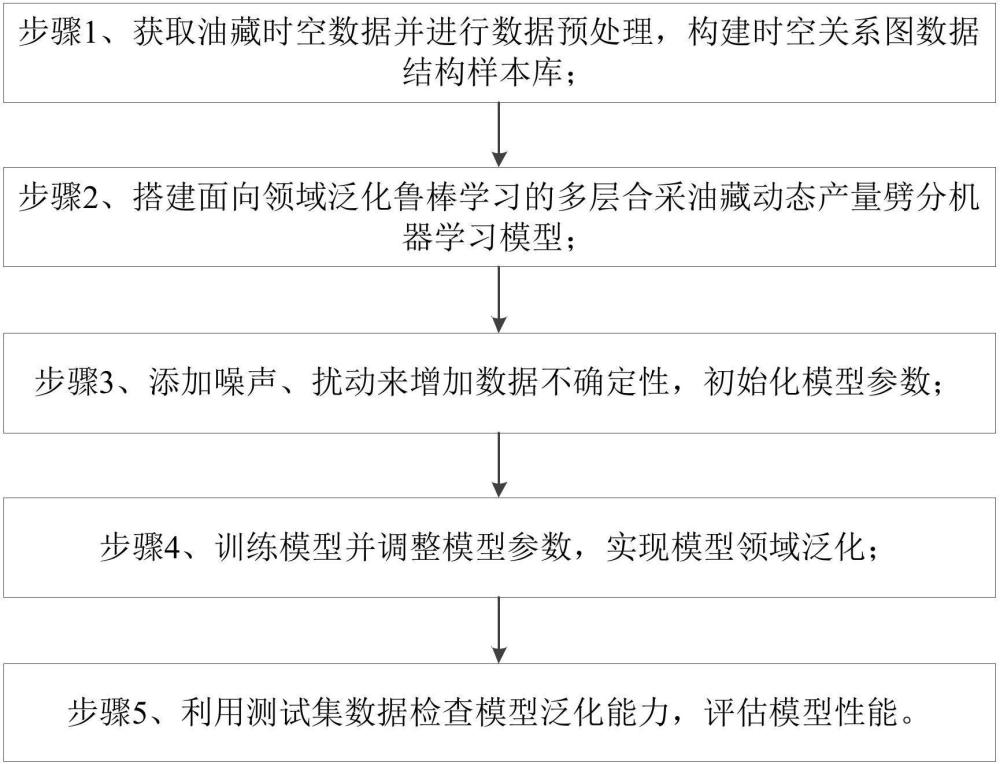
3、一种基于领域泛化机器学习的多层合采油藏动态产量劈分方法,包括如下步骤:
4、步骤1、获取油藏时空数据并进行数据预处理,构建时空关系图数据结构样本库;
5、步骤2、搭建面向领域泛化鲁棒学习的多层合采油藏动态产量劈分机器学习模型;
6、步骤3、添加噪声、扰动来增加数据不确定性,初始化模型参数;
7、步骤4、训练模型并调整模型参数,实现模型领域泛化;
8、步骤5、利用测试集数据检查模型泛化能力,评估模型性能。
9、进一步地,所述步骤1的具体过程为:
10、步骤1.1、获取油藏时空数据,油藏时空数据包括地质参数、产液参数、生产动态参数、测量时间;
11、步骤1.2、对油藏时空数据进行数据预处理并计算kh劈分值;预处理包括数据清洗和数据归一化处理,kh劈分值计算公式为:
12、 (1);
13、其中,为kh劈分值;表示地层的有效渗透率;为地层的有效厚度;
14、步骤1.3、将预处理后的数据进行主控因素分析,留取孔隙度、渗透率、有效厚度、日产液量相关性强的特征属性因素,构建高质量时空数据项表;
15、步骤1.4、将建立的高质量时空数据项表中的数据转换成时空关系图数据结构;其中,为图数据结构所有节点的集合,为第个节点;为时刻的边的集合;为时刻的邻接矩阵;
16、每口井作为图的顶点,每个小层作为图节点,每口井和其对应的小层之间的连接关系作为图的边;根据节点之间边的连接关系,构建邻接矩阵来描述图的拓扑结构;邻接矩阵是描述图中节点之间连接关系的矩阵,矩阵中每个元素表示两个节点之间是否存在边的连接,根据两个节点之间是否存在边的连接关系来对矩阵中的元素赋值;如果节点和节点之间存在边连接,则邻接矩阵的元素或的值为1,否则为0;
17、根据图节点包含的特征来构建特征矩阵,如下式所示:
18、 (2);
19、其中,表示节点的个数;表示特征维度;为特征矩阵中第个节点的第维元素;元素具体内容为步骤1.3预处理后的孔隙度、渗透率、有效厚度、日产液量相关性强的特征属性因素。
20、进一步地,所述步骤2中,面向领域泛化鲁棒学习的多层合采油藏动态产量劈分机器学习模型包含时空关系学习模块、鲁棒学习模块和偏差校正估计模块;
21、时空关系学习模块又划分为空间学习模块和时间学习模块;空间学习模块里面的两层谱域图卷积神经网络通过傅里叶变换将时空关系图数据结构中节点的特征表示转换为谱域中的频域表示;在谱域中,每个节点的特征表示为频率成分的线性组合;在谱域中对图信号进行卷积操作,卷积完成后,通过逆傅里叶变换将谱域中的节点特征表示转换回空域;具体公式如下:
22、 (3);
23、 (4);
24、其中,为图傅里叶变换的输出,将空间域的图信号转换到频域;为逆图傅里叶变换的输出,将频域的信号转换回空间域;为节点特征的集合;表示归一化图拉普拉斯算子特征向量的矩阵;为转置符号;
25、谱域图卷积神经网络的图卷积运算定义为:
26、(5);
27、 (6);
28、其中,为图卷积核;表示卷积操作;为在频域表示的图卷积核;
29、将通过切夫雪比多项式的截断展开来近似:
30、 (7);
31、 (8);
32、其中,为归一化图拉普拉斯算子,是图拉普拉斯矩阵,是的最大特征值;为单位矩阵;为经过两层谱域图卷积神经网络处理后的图信号;表示切比雪夫多项式的阶数;为表示用于近似图滤波器的切比雪夫多项式的阶数总数;表示切比雪夫系数向量;为阶切比雪夫多项式。
33、进一步地,经过两层谱域图卷积神经网络处理后的图信号作为一个时间步的输入传输到时间学习模块里面的长短时记忆神经网络中进行处理;长短时记忆神经网络将根据序列数据的时间顺序,逐步更新其内部的状态和记忆单元,并生成相应的输出序列;长短时记忆神经网络模型有三个门,分别为遗忘门、输入门和输出门;遗忘门是控制记忆状态中的信息进行选择性遗忘;遗忘门公式为:
34、 (9);
35、其中,为第个时间步的遗忘门的激活值;为sigmoid函数;为权重矩阵;为第个时间步的隐藏状态;为第个时间步的输入;为遗忘门的偏置项;
36、输入门是决定哪些信息被添加到记忆单元状态中,作为新的记忆;输入门公式如下所示:
37、 (10);
38、 (11);
39、 (12);
40、其中,为第 个时间步的输入门激活值;为输入门的权重;为输入门的偏置项;为第 个时间步的候选细胞状态;为tanh函数;为记忆单元的权重矩阵;为记忆单元的偏置项;为第 个时间步的记忆单元状态;为第个时间步的记忆单元状态;
41、输出门最后输出需要的记忆;输出门的公式为:
42、 (13);
43、 (14);
44、其中,为第 个时间步的输出门的激活值;为输出门的权重矩阵;为输出门的偏置项;为时空关系模块的输出序列。
45、进一步地,鲁棒学习模块由生成的添加噪声、扰动不确定性数据、时空关系模块的输出序列和损失函数构成;通过生成的添加噪声和扰动不确定性数据,模拟了数据中的随机性和不确定性;采用基于分布的wasserstein距离,度量了时空关系模块的输出序列,生成的噪声、扰动数据之间的概率分布差异,它们之间的wasserstein距离公式为:
46、 (15);
47、其中,为鲁棒学习模块的输出结果,表示和之间的wasserstein距离;为的下确界;为联合分布;表示所有将和连接起来的联合分布集合;为的支撑集;为的支撑集;是和之间的距离函数;是和的联合分布;
48、偏差校正估计模块由鲁棒学习模块的输出结果、kh劈分值和线性回归模型组成;使用线性回归模型建立鲁棒学习模块对地质条件、产液参数、生产动态参数特征学习得到的结果和kh劈分值之间的线性关系;
49、 (16);
50、其中,为的变化对的影响程度;为截距;
51、 (17);
52、其中,为kh劈分值的偏差校正估计值;
53、最后将输入到全连接层,得到预测结果。
54、进一步地,所述步骤3的具体过程为:
55、步骤3.1、在鲁棒学习模块中,为每个原始数据点添加来自符合高斯分布的随机数的值来引入噪声数据,放大和缩小部分原始数据来添加扰动数据;
56、步骤3.2、模型开始训练之前,使用he初始化方法对模型的参数进行初始化;he初始化公式如下:
57、 (18);
58、其中,为要初始化的权重矩阵;为正态分布;为第层神经元个数。
59、进一步地,所述步骤4的具体过程为:
60、步骤4.1、根据步骤1.4中转换的时空关系图数据结构,采用十折交叉验证将样本集划分为训练集和测试集;将样本库分成个大小相似的子集,选择其中一个子集作为测试集,其余的个子集作为训练集;
61、步骤4.2、设置切夫雪比多项式项数、隐藏层个数、输入输出参数和学习率,并将步骤1.4中采用十折交叉验证得到的训练集分成小的批次,每次输入一个批次的数据进入模型进行训练;重复进行批量训练的过程,直到达到预定的迭代次数;
62、步骤4.3、训练模型;在模型训练循环中,首先使用时空关系学习模块中的谱域图神经网络和长短时记忆神经网络学习多层合采油藏的动静态参数间的时间和空间依赖性;鲁棒学习模块将在模型中添加的噪声、扰动不确定数据与时空关系学习模块输出的数据分布之间的wasserstein 距离最小化;为此基于分布的wasserstein距离的损失函数设置为:
63、 (19);
64、其中,为生成器,生成与真实数据分布相似的数据分布;为判别器,用于区分真实数据和扰动不确定性数据;为wasserstein距离;是真实数据的分布;是不确定数据的分布;
65、步骤4.4、对模型超参数进行调优;使用粒子群优化算法,对面向领域泛化鲁棒学习的多层合采油藏动态产量劈分机器学习模型的隐藏层个数、切夫雪比多项式项数、学习率进行调优;使用粒子群优化算法进行超参数调优首先需要初始化粒子群,将每一个粒子代表一个超参数的组合,包括隐藏层个数、切比雪夫多项式项数和学习率;随机初始化粒子的超参数值和速度并设定参数的范围,使用均方误差mse作为适度函数在训练集上评估每个粒子的适应度;最后进行迭代更新达到最大迭代次数;更新每个粒子的速度与位置的更新公式如下:
66、 (20);
67、 (21);
68、其中,为粒子在第次迭代时的速度;为粒子在第次迭代时的位置;是粒子在第次迭代时的速度;是粒子在第次迭代时的位置;是惯性权重;和均是学习因子;和均是在[0,1]之间的随机数;是粒子的历史最佳位置;是全局最佳位置;
69、经过多次迭代后,输出全局最佳位置对应的超参数组合;
70、步骤4.5、将步骤4.4中调完参数的面向领域泛化鲁棒学习的多层合采油藏动态产量劈分机器学习模型进行保存。
71、进一步地,所述步骤5的具体过程为:
72、步骤5.1、将测试集数据输入到步骤4.5保存的面向领域泛化鲁棒学习的多层合采油藏动态产量劈分机器学习模型,进行多层合采油藏测试集数据产量劈分结果预测;
73、步骤5.2、使用评估指标来衡量模型的泛化能力;采用多模型评估指标来衡量模型的泛化能力,评估指标包括均方根误差、平均绝对误差;根据步骤3.3,在每个批次中,计算均方根误差、平均绝对误差,直到达到预定的迭代次数;达到迭代次数之后,将每次迭代获得的均方根误差、平均绝对误差取平均值;均方根误差、平均绝对误差的取值越小,表示模型的预测性能越好,误差越小。
74、本发明所带来的有益技术效果如下。
75、本发明利用谱域图神经网络和长短时记忆神经网络对地质参数、产液参数和生产动态参数之间的时空关系进行建模,可以更好地捕捉油田系统动静态参数之间的复杂性和动态性,提高产量预测的准确性和可靠性。
76、本发明模型中的鲁棒学习模块能够最小化目标分布上的损失,使其在面对不同领域的数据分布时仍能保持良好的预测性能。缓解不同领域数据分布差异造成的偏差漂移,减轻数据分布偏移的影响,使模型对于数据的不确定性具有容忍性,提高其对不同领域数据的适应能力,使模型更具有鲁棒性和领域泛化能力。
77、本发明使用线性回归模型建立动静态参数特征值和kh劈分值之间的线性关系,计算线性回归模型预测值与实际kh劈分值之间的差值,并减去差值,实现对kh劈分值的校正。kh劈分值的偏差校正估计可以消除模型预测过程中对kh劈分值的过度依赖,不再过分依赖于单一的参数,从而提高了预测结果的准确性和稳健性,增强了模型的鲁棒能力。
本文地址:https://www.jishuxx.com/zhuanli/20240731/193769.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。