一种全同态密文运算方法、装置及存储介质与流程
- 国知局
- 2024-08-02 14:14:32
本发明涉及全同态密文运算,尤其是指一种全同态密文运算方法、装置、设备及存储介质。
背景技术:
1、全同态密文运算是指一种加密算法和加密形式,它允许人们对密文进行任意的代数运算,将运算结果解密之后得到的结果明文,同直接用明文进行相同的运算得到的结果相同。通过全同态运算,可以实现数据在运算过程中全部以密文的形式存在,使得运算过程不会泄露用户数据的隐私信息,这使得隐私数据在云服务器上的运算外包成为可能。在近年来飞速发展的深度学习和人工智能等新型计算范式的推动下,用户数据在云服务中的分享和外包计算越来越成为训练更复杂更精准模型的前提。但同时随着中国、美国和欧盟相继出台用户隐私保护相关法令法规,用户数据隐私安全也越发受到重视。全同态的出现和推广可以很好的解决数据分享和隐私保护之间的矛盾。
2、全同态被认为是密码学的圣杯,在其概念于1979年首次被rivest等人提出后的很长一段时间内,人们都只能实现部分操作的同态运算,如在密文上实现同态加法运算的paillier同态方案,以及只实现同态乘法运算的rsa和elgamal同态乘法方案,这些都被称为部分同态加密(partly homomorphic encryption)。2009年craig gentry提出了基于理想格的全同态加密方案,同时实现了密文上的加法和乘法同态运算,首次在理论上证明了全同态的可行性。后续全同态加密方面的工作大多以此为基础,使其不断优化和实用化,目前已经发展出实现了整数同态加法和乘法的bgv和bfv方案、支持浮点运算的ckks方案,以及基于单比特逻辑运算的tfhe全同态方案。
3、当前各类全同态方案均存在运算量大、密文及密钥占据存储空间较大等问题。其根源在于当前主流的全同态方案均是基于理想格上的误差学习问题(learning witherror),这就使得密文均带有一定的噪声,而密文噪声会随着在密文上进行的同态运算次数的增长而增长,当密文中的噪声水平超过一定的阈值时,对密文进行解密操作就无法得到正确的运算明文,导致同态运算失败。因此当前的全同态方案均包含一个对密文进行减噪刷新操作,使得减噪后的密文可以继续进行密文操作,从而支持在密文上进行任意多次的同态运算。craig gentry在其2009年的开创性方案中指出这个减噪操作可以通过在新的密钥下进行基于原密钥的同态解密运算来进行。具体的,输入的密文是使用旧密钥(k1)加密的,先将密文用新密钥(k2)再次加密,然后在k2密态下用k2加密了的k1密钥对密文进行同态解密,得到一个k2加密下的密文,同时输入密文上的噪声随着同态解密操作大大减少,此过程被称为自举(bootstraping)操作。由于同态解密操作的复杂性,自举成为全同态加密体系中运算量最大、存储空间消耗最多的操作,也是各类工作优化的重点。
4、bgv、bfv以及ckks方案更多的采用尽量避免自举操作,在进行了多次同态运算后必要时才进行自举,因此被称为层级同态加密(leveled homomorphic encryption)。同时采用batching等方法进行自举的并行化处理,使得自举的大运算量被较大的并行数据量分摊。而tfhe则在每一次同态操作(比特逻辑运算)后都进行自举,将每一个逻辑门操作同自举操作封装,在对逻辑门运算进行组合就可以实现无限次的逻辑运算,实现了真正的全同态,这种自举操作被称作门自举(gate bootstraping)。tfhe的后续优化方案聚焦于提升门自举的计算效率,并减少自举密钥的存储空间,力求在当前的计算机算力下接近于实用。
5、tfhe,即fully homomorphic encryption on torus(环面全同态加密),其基本概念由craig gentry等人在2013年提出,并由illaria chillotti等人在之后的几年的逐渐完善和优化。如上所述,tfhe主要关注单比特的逻辑运算,如and(与),or(或),not(非),xor(异或)等基本逻辑运算,并由此构造对应的基本逻辑门,且在每个逻辑门的逻辑运算后马上进行自举操作,即所谓门自举操作,使得人们可以实用这些基本逻辑门构造任意复杂的逻辑电路,处理任意深度的运算,而不用当心噪声问题。同时在每一步逻辑运算后都进行自举操作方便实现模块化和层次化设计,密码算法专家可以专注优化基本同态逻辑门的性能,构建基本同态逻辑门单元库,而同态应用的设计者无需关心密码学的底层细节,只需根据应用需求进行底层函数调用即可。ilaria chillotti等人也发布了相应的tfhe库,该库由c/c++实现,支持and、or、xor、nand(与非)等10种基本逻辑逻辑的同态运算。每一个逻辑门都附带自举运算。每一个二输入的逻辑门同态运算在单核x86处理器(intel core-i7)上运行占用13ms的处理器时间。后续的nufhe库对tfhe库底层运算进行改造,使用cuda和opencl,运行在gpu上实现了100倍的性能提升。
6、由于现代计算机的底层硬件电路实现也是由这些基本逻辑门构成,因此基于tfhe库及其衍生库可以打造一系列通用全同态计算架构,在密文上进行任意计算程序的运算。目前基于tfhe的通用全同态计算架构主要有全同态虚拟专用电路和全同态虚拟通用处理器两种技术路线。
7、如图1所示,全同态虚拟专用电路是通过电路编译器,将用户程序直接编译成相应的功能电路,功能电路由上述基本同态逻辑门构成。同时用户将所要计算的数据使用公钥进行加密,作为功能电路的输入进行所需的同态运算,得到密文结果后,由用户使用私钥进行解密操作得到结果明文。以google全同态团队于2021年发布的google transpiler为例,该团队采用了google自研的电路编译器xls将用户c++程序编译成电路表达格式xls ir,并通过一系列的优化和转换操作,将程序转换为布尔逻辑电路,如图2所示。最后将布尔逻辑电路中的逻辑单元门用tfhe库中的tfhe同态逻辑门替换,就形成了可以处理用户密态数据的全同态应用程序fhe c++。该计算架构所对应的隐私计算外包流程如图1所示,用户端将所要计算的用户数据进行二进制编码,转换成二进制比特文件,然后使用密钥加密成密文,用户数据密文和同态参数发送到云端;云服务器将上述密文和参数输入到上述电路编译器产生的全同态应用程序fhe c++中,并由fhe c++完成全同态运算,产生的结果密文发送回客户端;由用户使用密钥解密得到最终运算结果。该技术路线中的专用电路是指其具体电路网表都是由用户程序直接编译而成的,不同的用户程序编译出实现其功能的专门电路。虚拟专用电路是指并不是在硬件层面真的实现了专用电路,而是将专用电路中的每一个逻辑门用tfhe库中对应的同态逻辑门函数替换,最终形成的是一个在通用计算机上运行fhec++程序,该c++程序按照所编译的电路网表依次调用相应的tfhe库中的同态逻辑运算函数,完成对数据密文的同态操作。
8、与现代计算机体系结构中有专用逻辑电路和通用处理器相对应,另一种通用全同态计算架构采用了全同态虚拟通用处理器,即将整个通用处理器虚拟同态化。如前所述现代通用处理器都是由逻辑门单元组合实现,只需将通用处理器的底层逻辑门用tfhe中对应的同态逻辑运算函数进行替换,就可以实现一个由c/c++程序实现的同态虚拟处理器。同时我们可以将用户程序使用该处理器对应的编译器进行编译,转换为二进制程序文件,与用户数据一同加密成同态密文。将程序密文和数据密文加载到同态虚拟处理器中运行,就可以得到程序运算的结果密文,并由用户解密得到明文。京都大学的kotaro matsuoka等人在2020年提出了基于risc-v指令架构的全同态虚拟处理器,将一个5级流水的risc-v指令架构32位处理器的底层逻辑门用tfhe库进行等效替换,实现了通用用户程序密文的同态执行。其外包运算流程如图3所示,在客户端,用户将用户程序采用risc-v编译器编译成能够被risc-v处理器识别并执行的二进制程序文件。用户将用户数据和二进制程序都加密成tfhe密文,发送到云端。用户数据密文和用户程序密文在云端被加载到部署在服务器上的risc-v同态虚拟处理器,处理器运算后得到结果密文发送回客户端,并由客户进行解密得到结果明文。
9、对比上述两种技术路线,全同态虚拟专用电路针对每一个用户程序定制逻辑电路,用户程序的复杂程度决定了专用电路的复杂程度,在经过工具优化之后不会有冗余运算,相对性能较高。但用户编译并转换后的fhe c++程序是公开的且需要部署在云端运行,因此用户程序实际上是公开,可以通过将fhe c++程序进行反编译获得用户的原程序,无法实现用户程序的隐藏。全同态虚拟通用处理器的同态逻辑运算规模由通用处理器的逻辑门数和虚拟通用处理器的运行周期共同决定。由于通用处理器的逻辑门数是由处理器微架构决定的,与用户程序无关,因此采用虚拟通用处理器进行同态逻辑运算必然包含一定的计算冗余,使本来就效率低下的同态运算性能雪上加霜,严重阻碍了该技术路线的进一步实用化。如上述京都大学的risc-v同态虚拟处理器的实际运行频率仅为1.25hz,与同样微架构的非同态硬件risc-v处理器有着多达8个数量级的性能差距。但该技术方案的优点在于能够实现用户程序隐藏。由于在云服务器上公开部署的只是虚拟处理器的底层逻辑门电路,与用户程序无关。用户程序连同用户数据都是加密后全程以密文的形式在云服务器上参与运算的,在保护了用户数据的同时也有效的保护的用户程序不被泄露,在数据模型和知识产权保护方面有着重要的意义。
10、现有基于tfhe的全同态通用计算两种技术路线中,全同态虚拟专用电路同态运算性能较好,但无法实现用户程序隐藏。而全同态虚拟通用处理器同态运算冗余量大,性能较差,但可以实现用户程序隐藏。
技术实现思路
1、为此,本发明所要解决的技术问题在于克服现有技术中的无法在实现用户程序隐藏的同时保持较好性能的问题。
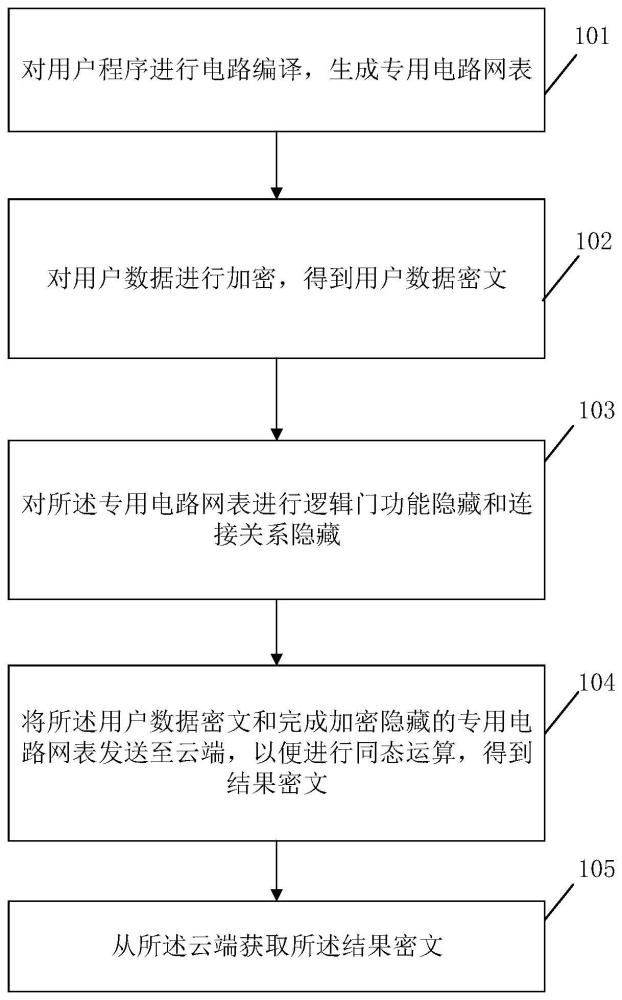
2、为解决上述技术问题,本发明提供了一种全同态密文运算方法,包括:
3、对用户程序进行电路编译,生成专用电路网表;
4、对用户数据进行加密,得到用户数据密文;
5、对所述专用电路网表进行逻辑门功能隐藏和连接关系隐藏;
6、将所述用户数据密文和完成加密隐藏的专用电路网表发送至云端,以便进行同态运算,得到结果密文;
7、从所述云端获取所述结果密文。
8、优选地,所述逻辑门功能隐藏的具体步骤包括:
9、将所述专用电路网表中的逻辑门替换为查找表lut,并按照所述逻辑门的具体功能配置所述查找表lut的真值输入;
10、对所述真值输入进行加密。
11、优选地,所述查找表lut由多个同态mux逻辑门组合构成。
12、优选地,所述连接关系隐藏的具体步骤包括:
13、创建运行参数表;
14、将所述用户数据密文作为专用电路网表初始门输入存储至所述运行参数表中;
15、将专用电路网表逻辑运算的中间值密文存储至所述运行参数表中;
16、根据专用电路网表中逻辑门的连接关系确定每一个查找表lut的门输入和门输出在所述运行参数表中存放的地址,并进行加密。
17、优选地,所述运行参数表的读写操作包括:
18、通过输入的表项地址读取相应的表项,得到查找表的输出;
19、为每一个表项创建一个独立的写单元,所述写单元基于多级mux门实现;
20、当写地址与写单元对应的表项地址一致且写使能有效时,所述写单元的输出为输入的写数据,根据所述写数据更新原表项数据,否则,所述写单元的输出为所述原表项数据,表项数据不进行更新。
21、优选地,所述用户数据的加密方式为tfhe加密。
22、优选地,所述同态运算的具体步骤包括:
23、根据所述完成加密隐藏的专用电路网表调用tfhe库中的同态逻辑运算函数,完成所述用户数据密文的逻辑运算。
24、本发明还提供了一种全同态密文运算装置,包括:
25、专用电路网表生成模块,用于对用户程序进行电路编译,生成专用电路网表;
26、用户数据加密模块,用于对用户数据进行加密,得到用户数据密文;
27、专用电路网表加密隐藏模块,用于对所述专用电路网表进行逻辑门功能隐藏和连接关系隐藏;
28、数据传输模块,用于将所述用户数据密文和完成加密隐藏的专用电路网表发送至云端,以便进行同态运算,得到结果密文;
29、结果密文获取模块,用于从所述云端获取所述结果密文。
30、本发明还提供了一种全同态密文运算设备,包括:
31、存储器,用于存储计算机程序;
32、处理器,用于执行所述计算机程序时实现上述一种全同态密文运算方法步骤。
33、本发明还提供了一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现上述一种全同态密文运算方法的步骤。
34、本发明的上述技术方案相比现有技术具有以下优点:
35、本发明所述的全同态密文运算方法,结合全同态虚拟专用电路同态运算和全同态虚拟通用处理器同态运算两种技术路线,取优补短,以全同态虚拟专用电路为基础,在电路编译器将用户程序编译成专用电路网表后,采用逻辑门功能隐藏和连接关系隐藏实现对专用电路网表的功能隐藏,从而实现了用户程序隐藏;相对于全同态虚拟通用处理器减少了同态逻辑运算冗余,提升了运算性能。
本文地址:https://www.jishuxx.com/zhuanli/20240801/242131.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表