一种基于深度强化学习的近端策略优化方法
- 国知局
- 2024-08-02 16:00:21
本发明涉及电力系统,尤其是一种基于深度强化学习的近端策略优化方法。
背景技术:
1、由于长时间停电、多设备故障、极端天气和人为攻击等威胁,电力系统的脆弱性问题变得越来越明显。为了有效解决这些问题,我们需要采取措施提高电力系统的恢复能力。在极端事件和设备故障期间及之后维持电压稳定对增强电力系统的稳定性和恢复能力,并预防级联故障而言至关重要。在发生n-k(k>1)突发事件即多重突发事件时,通过提供无功功率支持以保持电压约束,并合理部署并联无功补偿器,成为一种有前景的解决方案。因此,制定一种在极端事件期间和之后规划并联无功补偿器部署以维持电压约束的方法对于提升电力系统的弹性具有相当的意义。
技术实现思路
1、本发明解决了多线路故障期间的电压违规的问题,提出一种基于深度强化学习的近端策略优化方法,引入一种基于智能体的混合柔性动作评价算法,用于并联无功补偿器的离线定位、分级和在线控制,以提高其电压恢复能力。多智能体框架通过学习以前的经验并接受训练,最终确定并联无功补偿器适当的位置和大小,以避免多线路故障期间的电压违规,从而解决与精确系统建模相关的计算和可扩展性问题,并为电力系统弹性增强制定了并联无功补偿器部署计划。
2、为实现上述目的,提出以下技术方案:
3、一种基于深度强化学习的近端策略优化方法,包括以下步骤:
4、步骤1:基于深度强化学习算法构建多智能体柔性动作评价框架;
5、步骤2:利用弹性增强算法对多智能体柔性动作评价框架进行弹性增强;
6、步骤3:训练弹性增强后的多智能体柔性动作评价框架,利用训练好的弹性增强后的多智能体柔性动作评价框架对近端策略进行优化。
7、本发明首先构建多智能体柔性动作评价(multi-agent sac)框架,即masac框架;再利用masac框架下的弹性增强算法实现电力系统弹性增强;然后训练和执行masac框架,利用训练好的masac框架对近端策略进行优化。引入一种基于智能体的混合柔性动作评价算法,用于并联无功补偿器的离线定位、分级和在线控制,以提高其电压恢复能力。多智能体框架通过学习以前的经验并接受训练,最终确定并联无功补偿器适当的位置和大小,以避免多线路故障期间的电压违规,从而解决与精确系统建模相关的计算和可扩展性问题,并为电力系统弹性增强制定了并联无功补偿器部署计划。
8、作为优选,所述步骤1具体包括以下步骤:
9、步骤1-1:构建多智能体柔性动作评价框架的参数控制方式;
10、步骤1-2:构建多智能体柔性动作评价框架的策略函数;
11、步骤1-3:基于深度强化学习算法训练多智能体柔性动作评价框架。
12、本发明的步骤1首先构建masac框架的参数控制方式,然后再构建masac框架的策略函数,最后基于深度强化学习算法训练多智能体柔性动作评价框架。
13、作为优选,所述深度强化学习算法为ppo算法。本发明提出的masac框架采用近端策略优化(proximal policy optimization,ppo)算法进行训练。ppo算法是一种以动作-评价结构为基础的深度强化学习算法,其核心思想是通过策略梯度来获取最优策略。在ppo算法中,评价网络用于近似状态值函数,通过最小化估计函数的偏差来更新其网络参数。这一方法有助于更准确地估计状态值,从而改进策略网络的训练效果。
14、作为优选,所述步骤1-1具体包括以下步骤:
15、步骤1-1-1:设置系统状态参数,系统观测参数及系统动作;
16、步骤1-1-2:设置系统奖励机制。
17、本发明的步骤1-1将对电力系统弹性增强算法的状态、观测、动作和奖励进行设计,具体如下:
18、状态、观测和动作设计:
19、系统状态可以用各种参数表示,然而,在无功功率控制的研究中,广泛采用电压量级。这表明了深度强化学习(deep reinforcement learning,drl)算法在使用局部状态传播有价值信息方面的有效性,为保存大量测量数据和进行通信提供了灵活性。
20、奖励设计:为了有效训练masac框架,需要设计一个合适的奖励函数。奖励函数的目标是引导智能体采取对于电力系统恢复力和电压稳定性有益的行动。
21、作为优选,所述步骤1-1-2具体包括以下步骤:
22、步骤1-1-2-1:对于在多线路故障期间维持系统电压在安全范围内的系统行动,给予正奖励;步骤1-1-2-2:对于导致电压超出安全范围的系统行动,给予负奖励。
23、本发明通过这样设计奖励机制,masac框架的智能体将学习采取有助于电力系统弹性增强的行动。奖励函数的设计需要在鼓励合适的控制行为和避免不良影响系统稳定性的行为之间找到平衡。我们通过层次假设设计奖励函数,以评估masac所采取行动的有效性。
24、作为优选,所述步骤2具体包括以下步骤:
25、步骤2-1:构建极端事件下的场景训练和执行多智能体柔性动作评价框架;
26、步骤2-2:用二进制字符串定义弹性指数,利用弹性指数对多智能体柔性动作评价框架进行弹性增强;
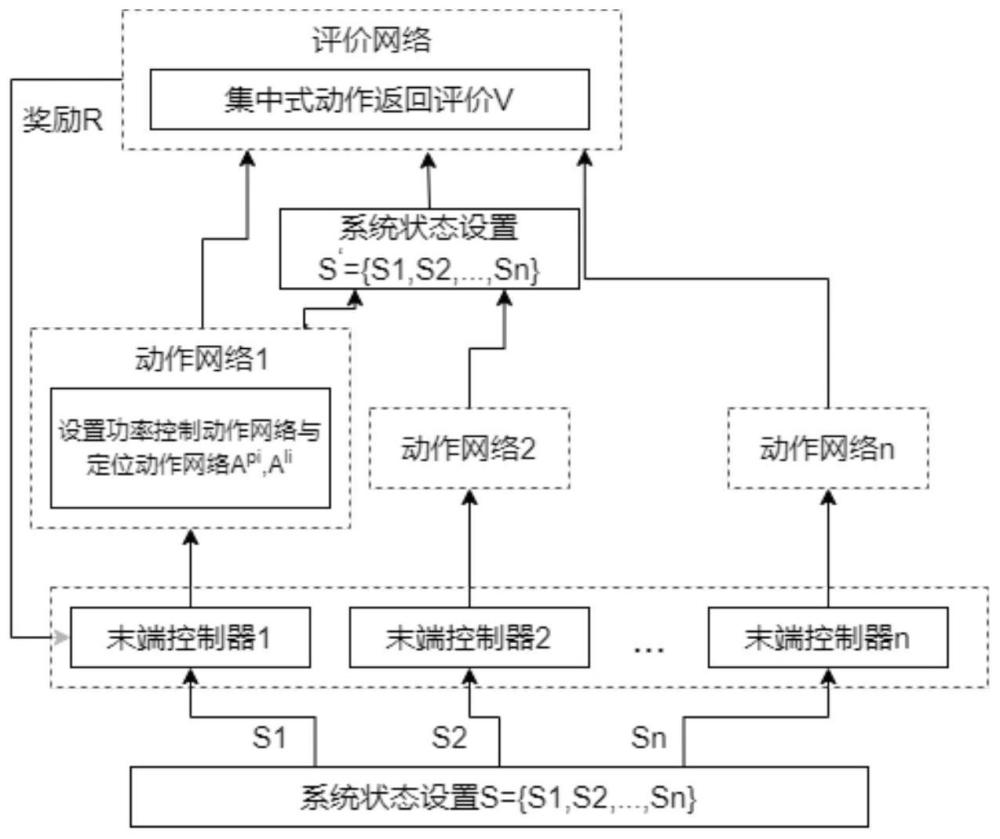
27、步骤2-3:确定弹性增强后的多智能体柔性动作评价框架的训练算法和执行算法。
28、本发明的步骤2首先构建极端事件下的场景训练和执行masac框架,再定义弹性指数,弹性指数采用“存活能力”来衡量弹性,存活能力可以定义为电力系统在突发事件中提供最大数量负载而不损害最关键负载的能力。由于本文的主要重点是开发一种方法来避免在多种意外情况下的负荷下降,最后确定masac框架的训练和执行算法,电网基于电气距离被分为若干区域,每个区域由一个智能体控制,用户/电力系统运营商有权根据系统规模选择masac框架的智能体数量。在突发事件期间,一个区域的电压通过一个智能体的控制动作被调节在预定义的范围内。
29、作为优选,所述步骤2-2中的二进制字符串中“1”表示电力系统能够满足全部负荷需求,“0”表示系统无法满足全部负荷需求。
30、作为优选,所述步骤3具体包括以下步骤:
31、步骤3-1:构建弹性增强后的多智能体柔性动作评价框架训练和执行步骤;
32、步骤3-2:测试训练好的弹性增强后的多智能体柔性动作评价框架,测试通过后进行步骤3-3;步骤3-3:利用训练好的弹性增强后的多智能体柔性动作评价框架对近端策略进行优化。
33、本发明的步骤3首先构建具体的masac框架训练和执行步骤,使用潮流求解器(如pypower)计算每个场景的潮流,每个智能体包含功率动作和定位动作,所有智能体都有一个集中的评价装置。在每个场景开始时,定位动作选择并联无功补偿器的适当的位置,而功率动作选择输出功率。然后,将这两个动作提供给评估网络,根据智能体的策略和算法的终止准则来更新这两个动作。此外,使用一个集中式重放缓冲区来存储所有智能体的信息,再在ieee 39-bus系统上验证所构建的masac框架,最后利用训练好的masac框架对近端策略进行优化。
34、作为优选,所述步骤3-1具体包括以下步骤:
35、步骤3-1-1:在初始电力系统故障场景下对数据集的每个情节进行潮流求解,得到初始电网状态,基于预定义的区域对初始电网状态进行分区,将每个区域的状态作为输入传递给相应的智能体;
36、步骤3-1-2:判断智能体是否发现电压违规,若否,智能体在其区域内维持原始动作,若是,基于其区域输入状态,改变智能体的控制动作,再对电力系统环境进行潮流计算,得到每个智能体的奖励和新观测值;
37、步骤3-1-3:将每个智能体的过渡状态存储在集中式重放缓冲区中;
38、步骤3-1-4:随着训练的进行,减少每个智能体的噪声,判断是否满足情节终止条件之一,若是将该智能体的信息存储,并进入下一个情节。
39、本发明的步骤3-1具体包括以下步骤:对于每个情节,在初始电力系统故障场景下进行潮流求解,得到初始电网状态(母线电压幅值)。然后,基于预定义的区域将电网状态进行分区。接下来,将每个区域的状态作为输入传递给相应的智能体。如果智能体检测到其区域内存在电压问题,则提取观测结果。否则,进行下一个情节的处理,如果某个智能体未发现电压违规,则该控制器将在其区域内维持原始动作。如果智能体检测到电压问题,改变智能体的控制动作。随后,对修改后的电力系统环境进行潮流计算,得到新的系统状态。根据获得的新状态,分别计算和提取每个智能体的奖励和新观测值。每个智能体将其过渡状态存储在集中式重放缓冲区中。定期,根据对小批次数据的随机抽样,动作和评价网络相继进行更新。随着训练的进行,每个智能体逐渐减少噪声以降低搜索概率。如果满足情节终止条件之一,将该信息存储,并进入下一个情节,即重新执行步骤3-1-1。
40、作为优选,所述情节终止条件设有2条,第1条为违规清除,第2条为达到最大迭代次数。
41、本发明的闭环过程持续于训练数据集的所有情节。对于每个情节,训练在满足以下两个条件之一时终止:1)违规清除;2)达到最大迭代次数。在条件2)下的终止情况下,电压违规是否仍然存在并不重要。通过奖励函数中设计的惩罚机制,智能体可以从经验中学习,避免提供不准确的动作。值得一提的是,所提出的masac框架需要一个集中的通信网络,以便在训练期间将所有智能体的动作传递给评价网络。在收到这些动作后,评价网络向智能体提供奖励,用于更新动作网络的策略。这一进程可以在不实时与系统交互的情况下离线执行。在测试/执行期间,经过训练的masac框架智能体仅使用本地测量数据提供控制命令,这些命令在执行之前可以由调度员检查。这种分散的动作使得各智能体在没有彼此通信与上级通信的情况下仍然能够调节区域电压。
42、本发明的有益效果是:本发明引入一种基于智能体的混合柔性动作评价算法,用于并联无功补偿器的离线定位、分级和在线控制,以提高其电压恢复能力。多智能体框架通过学习以前的经验并接受训练,最终确定并联无功补偿器适当的位置和大小,以避免多线路故障期间的电压违规,从而解决与精确系统建模相关的计算和可扩展性问题,并为电力系统弹性增强制定了并联无功补偿器部署计划。
本文地址:https://www.jishuxx.com/zhuanli/20240801/248852.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表