一种基于生成模型的无偏图像分类方法
- 国知局
- 2024-08-05 11:56:21
本发明涉及可信人工智能领域,尤其涉及一种基于生成模型的无偏图像分类方法。
背景技术:
1、图像分类任务作为一个最基础的计算机视觉领域任务,为计算机视觉领域其他多个任务提供了基础,在当今社会中具有重要性与广泛应用。例如在自动驾驶领域,用于辨识交通标志、车辆和行人,为智能交通系统提供关键信息,提高行车安全性。在安全领域,图像分类应用于监控摄像头,能够检测异常行为或潜在威胁,提升公共安全等等。这些应用展示了图像分类在不同领域中的多样性和关键作用,其发展不仅推动了技术的进步,也深刻影响了我们的日常生活。但当前分类任务中普遍存在虚假关联、分类存在偏见的问题,分类任务在某些子类别上的准确率较低,影响了图像分类在应用中的效果。
2、图像分类任务中的不公平性主要源于训练数据中分布的不平衡,例如对人脸是否微笑进行分类时,由于训练数据中大部分微笑的人脸为女性,传统方法(如经验风险最小化)训练的分类模型可能通过使用数据中微笑与女性之间的虚假关联作为预测目标的捷径,导致在微笑男性群体上的分类准确率降低,性别成为了影响微笑分类的偏见属性。
3、尽管现有方法在提高公平性,实现无偏分类上取得了进展,但它们面临一些问题。首先,大多数方法需要偏见属性的标签,而在应用中这可能无法获得。其次,由于图像中包含的广泛属性,确定哪些是可能造成偏见的属性仍然是一个挑战。第三,某些属性由于其主观性和模糊性难以标记。最后,标注成本对于大规模数据集可能较高,限制了方法的可扩展性。
4、现有方法的缺陷引发了一个重要的问题:如何在没有偏见属性标签的情况下,在有偏数据集上构建一个公平的图像分类模型,解决现有方法的局限性。
技术实现思路
1、本发明的目的在于解决现有技术中存在的问题,并提供一种基于生成模型的无偏图像分类方法。
2、本发明具体采用的技术方案如下:
3、一种基于生成模型的无偏图像分类方法,包括如下步骤:
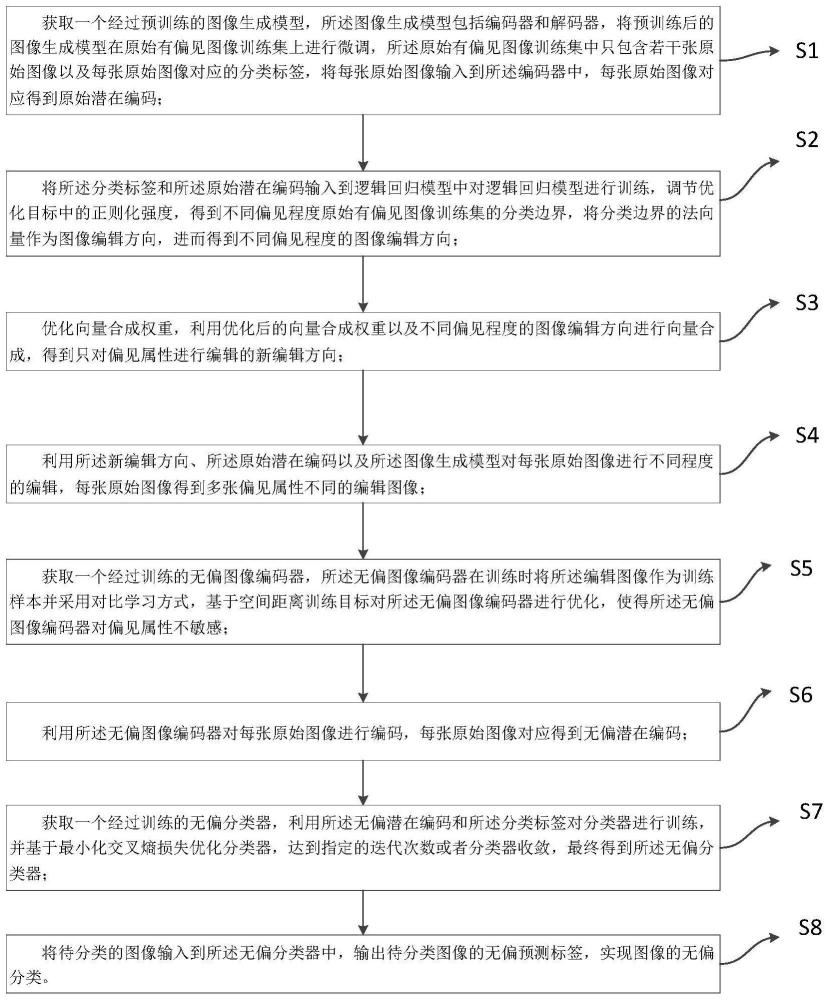
4、s1.获取一个经过预训练的图像生成模型,所述图像生成模型包括编码器和解码器,将预训练后的图像生成模型在原始有偏见图像训练集上进行微调,所述原始有偏见图像训练集中只包含若干张原始图像以及每张原始图像对应的分类标签,将每张原始图像输入到所述编码器中,每张原始图像对应得到原始潜在编码;
5、s2.将所述分类标签和所述原始潜在编码输入到逻辑回归模型中对逻辑回归模型进行训练,调节优化目标中的正则化强度,得到不同偏见程度原始有偏见图像训练集的分类边界,将分类边界的法向量作为图像编辑方向,进而得到不同偏见程度的图像编辑方向;
6、s3.优化向量合成权重,利用优化后的向量合成权重以及不同偏见程度的图像编辑方向进行向量合成,得到只对偏见属性进行编辑的新编辑方向;
7、s4.利用所述新编辑方向、所述原始潜在编码以及所述图像生成模型对每张原始图像进行不同程度的编辑,每张原始图像得到多张偏见属性不同的编辑图像;
8、s5.获取一个经过训练的无偏图像编码器,所述无偏图像编码器在训练时将所述编辑图像作为训练样本并采用对比学习方式,基于空间距离训练目标对所述无偏图像编码器进行优化,使得所述无偏图像编码器对偏见属性不敏感;
9、s6.利用所述无偏图像编码器对每张原始图像进行编码,每张原始图像对应得到无偏潜在编码;
10、s7.获取一个经过训练的无偏分类器,利用所述无偏潜在编码和所述分类标签对分类器进行训练,并基于最小化交叉熵损失优化分类器,达到指定的迭代次数或者分类器收敛,最终得到所述无偏分类器;
11、s8.将待分类的图像输入到所述无偏分类器中,输出待分类图像的无偏预测标签,实现图像的无偏分类。
12、作为优选,所述图像生成模型采用对抗生成网络。
13、作为优选,所述优化目标的函数形式为:
14、
15、其中,z为每张原始图像对应得到原始潜在编码;y为每张原始图像对应的分类标签;w为原始有偏见图像训练集的分类边界;表示2-范数的平方;e(z,y)表示所有原始潜在编码和所有分类标签所构成的域;λ为所述正则化强度。
16、作为优选,所述向量合成权重的优化过程如下:在预设的取值范围内选择当前向量合成权重,由当前向量合成权重和不同偏见程度的图像编辑方向进行运算,得到当前编辑方向,将原始潜在编码和当前编辑方向进行运算,得到当前潜在编码;将当前潜在编码输入到所述图像生成模型中,得到若干个当前生成图像;利用文本-图像匹配模型对当前生成图像进行判断:若满足当前生成图像和原始图像相比,分类属性保持不变,仅偏见属性发生变化,则将当前向量合成权重输出,作为优化后的向量合成权重;若不满足,则重新选择当前向量合成权重,直到满足当前生成图像的分类属性保持不变,仅偏见属性发生变化。
17、作为优选,所述取值范围设置为0.5-2.0;所述文本-图像匹配模型采用大语言模型clip。
18、作为优选,所述新编辑方向w*的函数形式为:
19、
20、其中,c1、c2...cn均表示向量合成权重;分别表示n个不同偏见程度的图像编辑方向。
21、作为优选,所述编辑图像x′的生成过程为:
22、x′=t(g(z+α′w*))
23、其中,α′表示编辑程度参数;t表示图像增强;g表示图像生成模型中的解码器。
24、作为优选,所述无偏图像编码器采用resnet50。
25、作为优选,所述空间距离训练目标的函数形式为:
26、
27、其中,dis为两个图像表征之间的空间距离,e(x′1)、e(x′2)均表示图像表征;e表示所述无偏图像编码器。
28、作为优选,所述分类器采用线性分类器。
29、本发明相对于现有技术而言,具有以下有益效果:
30、本发明首先获取偏见程度不同的图像编辑方向:提出利用有偏见的数据集训练图像生成模型,得到有偏的图像编码;根据有偏的图像编码训练分类边界,并取其法向量得到图像编辑方向;通过调整训练目标函数中的正则化强度,得到偏见程度不同的编辑方向。
31、本发明其次合成仅对偏见属性进行编辑的编辑方向:利用文本-图像匹配模型自动挑选向量合成权重,使得编辑后的图像仅偏见属性发生变化,分类属性与编辑前保持一致。
32、本发明接着对图像的偏见属性进行不同程度的编辑,并通过对比学习得到无偏图像编码器:将有偏见的数据集中图像偏见属性朝不同方向进行编辑,得到偏见属性不同的编辑图像,使用对比学习拉近编辑图像编码之间的距离,训练得到一个对偏见属性不敏感的无偏图像编码器。
33、本发明最后利用无偏图像编码器得到线性无偏分类器:通过无偏图像编码器得到有偏见的数据集图像的无偏编码,再利用无偏图像编码器训练线性分类器,即可得到对图像进行无偏分类的线性无偏分类器。
34、可见,与背景技术相比,本发明无需得到虚假关联中的偏见属性,可同时消除多个偏见属性的影响,同时适用于二分类任务及多分类任务,在多个指标上提升了图像分类器的公平性。
本文地址:https://www.jishuxx.com/zhuanli/20240802/260172.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表