一种高并发的大语言模型高速推理部署方法与流程
- 国知局
- 2024-08-05 12:00:43
本发明涉及计算机自然语言,更具体地说,它涉及一种高并发的大语言模型高速推理部署方法。
背景技术:
1、2023年chatgpt的爆发,标志着人工智能四大领域中的自然语言处理得到了人们的肯定。在当前的计算机自然语言处理领域,大语言模型(llm:large language model)的应用日益广泛,这些模型能够通过深度学习和大规模数据训练来理解和生成自然语言文本,其在机器翻译、文本分析、理解推理、智能客服和信息高效检索等方面展现出了强大的潜力。
2、尽管大语言模型(llm)在准确性和泛化能力方面表现出色,但通常会面临着推理速度慢、无法支持高并发请求以及需要大量计算资源等问题。
3、目前,推理部署方法多采用模型量化的方式,往往难以同时兼顾基础准确率、泛化能力、延迟、并发性和计算速度等推理需求。因此,有必要提出一种高并发的大语言模型(llm)高速推理部署方法,以解决这些挑战。
技术实现思路
1、本发明要解决的技术问题是针对现有技术的上述不足,本发明的目的是提供一种高并发的大语言模型高速推理部署方法,可以在不影响模型基础准确率和泛化能力的同时,满足低延迟、高并发、高速计算的模型推理需求。
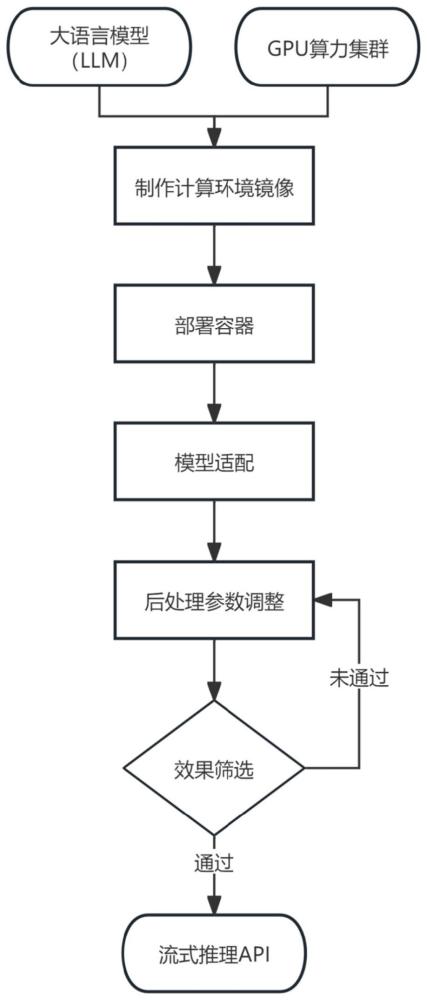
2、本发明的技术方案是:一种高并发的大语言模型高速推理部署方法,包括以下步骤:
3、步骤1.准备好需要部署的大语言模型和需要匹配模型推理部署的gpu算力集群;
4、步骤2.根据步骤1中的大语言模型和开源部署框架vllm所需的运行环境版本,配置制作模型推理计算所需的docker镜像;
5、步骤3.在步骤1中的gpu算力集群内的每台物理机中,使用步骤2中制作好的docker镜像创建容器;
6、步骤4.编写步骤1中大语言模型的推理代码,在步骤3中创建的容器内使用bfloat16浮点数格式完成适配部署;
7、步骤5.制作测试数据集,根据步骤4中部署的大语言模型对测试数据集的推理情况,筛选最优的后处理参数;
8、步骤6.采用步骤5中得到的后处理参数和步骤4中部署的大语言模型搭建流式推理api;
9、步骤7.使用步骤6中的流式推理api进行大语言模型推理。
10、作为进一步地改进,在步骤1中,获得使用企业场景化数据微调开源qwen-14b-chat生成的dxqwen-14b-chat大语言模型及相关模型文件,根据用户的并发需求建立gpu算力集群,gpu算力集群包含多台物理机,每台物理机包含多块gpu卡或显卡,每台物理机配置有双端口网卡,多台物理机通过双端口网卡和交换机实现高速互通,每台物理机安装开源docker相关程序,为大语言模型提供部署环境,将dxqwen-14b-chat大语言模型及相关模型文件拷贝至每台物理机中,并确保每台物理机配置和文件夹路径完全一致。
11、进一步地,在步骤2中,在docker镜像内安装步骤1中dxqwen-14b-chat大语言模型和开源部署框架vllm运行所需版本的cuda、cudnn、python代码包、c++代码包的环境包,用于统一步骤1中gpu算力集群的物理机的部署环境。
12、进一步地,在步骤3中,将步骤2中建立的docker镜像拷贝至步骤1中gpu算力集群的每台物理机内,并在每台物理机中使用镜像启动挂载步骤1中dxqwen-14b-chat大语言模型及相关模型文件和物理机显卡的容器,在容器内配置开启相互之间的免密访问。
13、进一步地,在步骤4中,在步骤3中创建好的容器内,基于步骤2中装好的开源部署框架vllm,将步骤1中dxqwen-14b-chat大语言模型采用bfloat16浮点数格式进行多机多卡启动测试,测试过程中解决出现的各种bug和环境配置问题,问题解决完后,完成模型推理适配部署。
14、进一步地,在步骤5中,在收集多条与步骤1中微调模型所用数据有相关性的问答数据,以及多条通用型问答数据,将该两种问答数据合并成验证数据集,采用专家经验总结的形式,生成多组temperature和top_p后处理参数,利用验证数据集在多组后处理参数中筛选效果最好的一组参数,并作为后处理参数。
15、进一步地,在步骤6中,基于步骤4中完成推理适配部署的大语言模型,封装流式推理api,api内的后处理默认参数采用步骤5中测试得到最优的后处理参数,api的入参参数还包含模型名称、模型起始字符、模型起始字符token_id和重复惩罚值,流式推理api返回值为输入的上下文数据以及模型的回答内容数据。
16、进一步地,在步骤7中,将步骤6搭建的流式推理api嵌入到需要使用步骤1中的大语言模型进行问答推理的平台、系统或程序中,以提供稳定、高精度、高并发的快速推理能力;调用步骤6搭建的流式推理api时,输入提问的问题和相关上下文数据,api将流式返回大语言模型推理的问题回答数据。
17、有益效果
18、本发明与现有技术相比,具有的优点为:
19、相较于现有技术,本发明基于开源部署框架vllm,通过自制docker镜像在物理机分布式多机多卡部署的方式提高稳定性,使用bfloat16浮点数格式部署大语言模型,结合实际数据验证的后处理策略,提供流式api接口完成模型推理,以确保不损失大语言模型精度的同时,提供最大的并发处理能力。本发明使得大语言模型能够在实际应用场景下为用户提供稳定、高精度、高并发的快速推理能力。
技术特征:1.一种高并发的大语言模型高速推理部署方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的一种高并发的大语言模型高速推理部署方法,其特征在于,在步骤1中,获得使用企业场景化数据微调开源qwen-14b-chat生成的dxqwen-14b-chat大语言模型及相关模型文件,根据用户的并发需求建立gpu算力集群,gpu算力集群包含多台物理机,每台物理机包含多块gpu卡或显卡,每台物理机配置有双端口网卡,多台物理机通过双端口网卡和交换机实现高速互通,每台物理机安装开源docker相关程序,为大语言模型提供部署环境,将dxqwen-14b-chat大语言模型及相关模型文件拷贝至每台物理机中,并确保每台物理机配置和文件夹路径完全一致。
3.根据权利要求2所述的一种高并发的大语言模型高速推理部署方法,其特征在于,在步骤2中,在docker镜像内安装步骤1中dxqwen-14b-chat大语言模型和开源部署框架vllm运行所需版本的cuda、cudnn、python代码包、c++代码包的环境包,用于统一步骤1中gpu算力集群的物理机的部署环境。
4.根据权利要求2所述的一种高并发的大语言模型高速推理部署方法,其特征在于,在步骤3中,将步骤2中建立的docker镜像拷贝至步骤1中gpu算力集群的每台物理机内,并在每台物理机中使用镜像启动挂载步骤1中dxqwen-14b-chat大语言模型及相关模型文件和物理机显卡的容器,在容器内配置开启相互之间的免密访问。
5.根据权利要求2所述的一种高并发的大语言模型高速推理部署方法,其特征在于,在步骤4中,在步骤3中创建好的容器内,基于步骤2中装好的开源部署框架vllm,将步骤1中dxqwen-14b-chat大语言模型采用bfloat16浮点数格式进行多机多卡启动测试,测试过程中解决出现的各种bug和环境配置问题,问题解决完后,完成模型推理适配部署。
6.根据权利要求1所述的一种高并发的大语言模型高速推理部署方法,其特征在于,在步骤5中,在收集多条与步骤1中微调模型所用数据有相关性的问答数据,以及多条通用型问答数据,将该两种问答数据合并成验证数据集,采用专家经验总结的形式,生成多组temperature和top_p后处理参数,利用验证数据集在多组后处理参数中筛选效果最好的一组参数,并作为后处理参数。
7.根据权利要求1所述的一种高并发的大语言模型高速推理部署方法,其特征在于,在步骤6中,基于步骤4中完成推理适配部署的大语言模型,封装流式推理api,api内的后处理默认参数采用步骤5中测试得到最优的后处理参数,api的入参参数还包含模型名称、模型起始字符、模型起始字符token_id和重复惩罚值,流式推理api返回值为输入的上下文数据以及模型的回答内容数据。
8.根据权利要求1所述的一种高并发的大语言模型高速推理部署方法,其特征在于,在步骤7中,将步骤6搭建的流式推理api嵌入到需要使用步骤1中的大语言模型进行问答推理的平台、系统或程序中,以提供稳定、高精度、高并发的快速推理能力;调用步骤6搭建的流式推理api时,输入提问的问题和相关上下文数据,api将流式返回大语言模型推理的问题回答数据。
技术总结本发明公开了一种高并发的大语言模型高速推理部署方法,属于计算机自然语言技术领域,解决现有推理部署方法难以同时兼顾基础准确率、泛化能力、延迟、并发性和计算速度的推理需求的技术问题,方法为:包括准备好大语言模型和GPU算力集群;根据大语言模型和开源部署框架vLLM所需的运行环境版本配置制作Docker镜像;在GPU算力集群内的每台物理机中,使用Docker镜像创建容器;编写大语言模型的推理代码,在容器内使用BFloat16浮点数格式完成适配部署;根据大语言模型对测试数据集的推理情况,筛选最优的后处理参数;采用后处理参数和大语言模型搭建流式推理API;使用流式推理API进行大语言模型推理。可以确保不损失大语言模型精度的同时,提供最大的并发处理能力。技术研发人员:高健,黄文新,李昌金受保护的技术使用者:中国—东盟信息港股份有限公司技术研发日:技术公布日:2024/8/1本文地址:https://www.jishuxx.com/zhuanli/20240802/260615.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表