一种基于强化学习的配电网故障恢复方法及系统与流程
- 国知局
- 2024-08-08 16:51:18
本发明涉及电力系统运行与控制,具体为一种基于强化学习的配电网故障恢复方法及系统。
背景技术:
1、在过去几十年里,随着电力系统的不断扩张和复杂化,配电网的稳定和可靠运行成为了电力系统设计和运维中的一个核心问题;特别是在面对自然灾害、设备老化、操作失误等导致的电网故障时,如何快速有效地恢复供电,减少故障对消费者的影响,成为了电力系统研究的重要课题。
2、近年来,随着计算机技术、人工智能和数据科学的飞速发展,基于数据驱动的决策支持系统在配电网故障恢复领域得到了广泛应用;特别是机器学习和强化学习技术的引入,为解决配电网的动态优化问题提供了新的思路和方法;强化学习,尤其是最大熵强化学习(softactor-critic,sac)和批量限制强化学习,通过从历史数据中学习最优策略,展现出在处理配电网故障恢复问题上的巨大潜力。
3、尽管强化学习在配电网故障恢复方面取得了进展,但现有技术仍存在一些不足之处;首先,大多数现有方法依赖于与环境的实时交互来学习最优策略,这在真实的电力系统中往往是不可行的,因为实时交互可能导致系统稳定性风险;其次,现有方法在处理高维状态和动作空间时的效率和准确性仍有待提高,尤其是在电力系统复杂性日益增加的背景下。
技术实现思路
1、鉴于上述存在的问题,提出了本发明。
2、因此,本发明解决的技术问题是:现有的配电网故障恢复方法存在响应性低,准确性低,效率性低,以及如何基于强化学习对配电网故障进行恢复的问题。
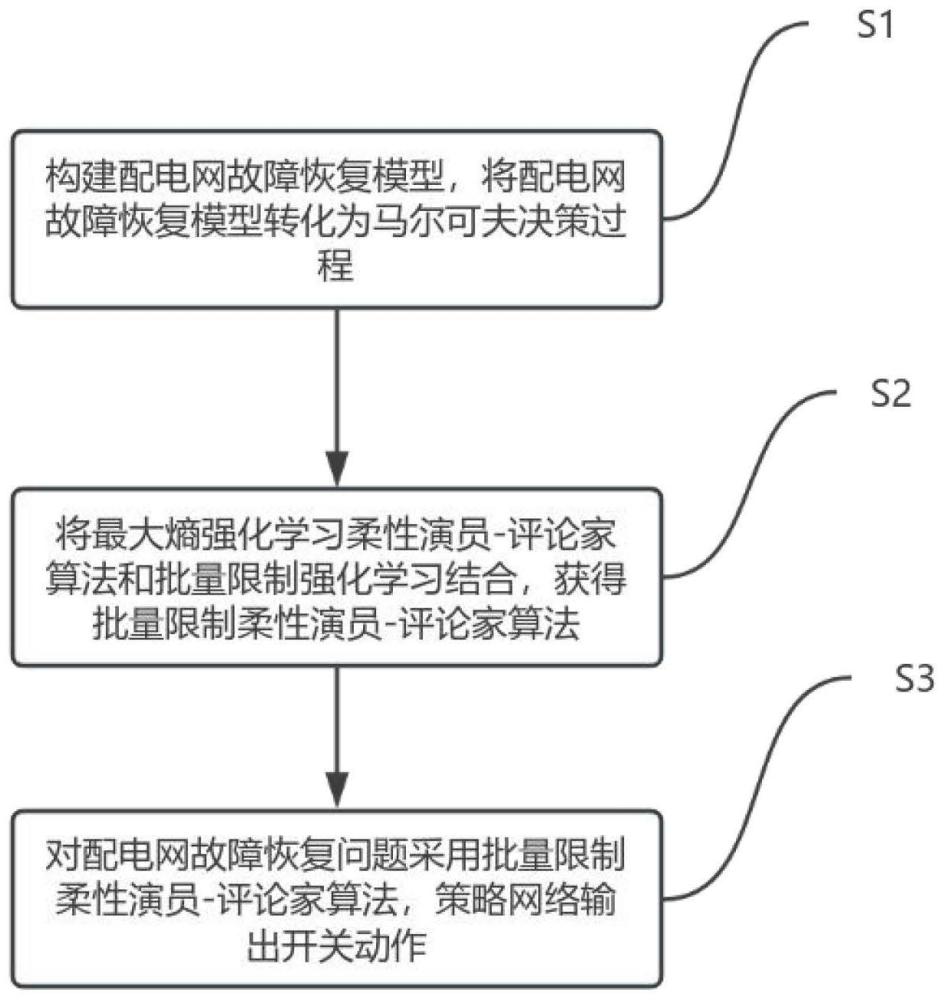
3、为解决上述技术问题,本发明提供如下技术方案:一种基于强化学习的配电网故障恢复方法,包括构建配电网故障恢复模型,将配电网故障恢复模型转化为马尔可夫决策过程;将最大熵强化学习柔性演员-评论家算法和批量限制强化学习结合,获得批量限制柔性演员-评论家算法;对配电网故障恢复问题采用批量限制柔性演员-评论家算法,策略网络输出开关动作。
4、作为本发明所述的一种基于强化学习的配电网故障恢复方法的一种优选方案,其中:所述将配电网故障恢复模型转化为马尔可夫决策过程包括构建配电网故障恢复模型,将配电网故障恢复模型转化为马尔可夫决策过程。
5、构建配电网故障恢复模型包括基于配电网故障恢复问题,构建目标函数,满足潮流约束、节点电压约束以及支路容量约束。
6、基于配电网故障恢复问题,通过失负荷成本clol最小化,线路损耗成本closs最小化,节点电压越限成本cv最小化,构建目标函数f,表示为:
7、minf=clol+closs+cv
8、失负荷成本clol,表示为:
9、
10、其中,t为总运行时间,cl为单位电价,为t时刻的失负荷功率。
11、线路损耗成本closs,表示为:
12、
13、其中,为t时刻的线路损耗功率,节点电压越限成本cv,表示为:
14、
15、其中,λ为节点电压越限的单位成本,nv为所有节点的集合,vit为t时刻i节点的电压值,为电压的上限,v为电压的下限;潮流约束,表示为:
16、
17、其中,pi,t为i节点输入的有功功率,为t时刻i节点电源输入的有功功率,为t时刻i节点的有功负荷,vi,t为节点的电压,j为节点,n为节点总数,vj,t为末端节点的电压,gij为支路ij间的电导,bij为支路ij间的电纳,δij,t为t时刻节点ij间的电压相角差,qi,t为节点输入的无功功率,为t时刻节点电源输入的无功功率,为t时刻节点的无功负荷;节点电压约束,表示为:
18、
19、其中,vi,min为节点电压的下限,vi,max为节点电压的上限;支路容量约束,表示为:
20、
21、其中,sb,t为t时刻支路b流经的视在功率,sb,max为流经支路b的最大视在功率;网路拓扑约束,表示为:
22、
23、其中,为配电网在t时刻的拓扑结构,γ为网络构型;将配电网故障恢复模型转化为马尔可夫决策过程包括一个有n个负载节点、m条线路以及ns个变电站的配电网,节点i在t时刻的电压幅值vit,负载节点i在t时刻实时电网注入pit,负载节点i在t时刻无功电网注入qit,网络的实时线路总损耗开关在t时刻的状态为当开关在时刻t闭合时,负载节点实时功率的注入向量pt,表示为:
24、pt=[p1t,...,pnt]
25、其中,pnt为第n个负载节点的实时功率的注入;负载节点无功功率注入的向量qt,表示为:
26、qt=[q1t,...,qnt]
27、其中,qnt为第n个负载节点的无功功率的注入;负载节点t时刻所有开关状态的向量αt,表示为:
28、αt=[α1t,...,αmt]
29、其中,αmt为第m条线路的开关状态;通过智能体、状态、动作以及奖励函数,将配电网故障恢复问题转化为马尔可夫决策过程,马尔可夫决策过程包括状态空间动作空间实时奖励r,折扣因子γ,状态转移概率函数p,状态转移概率,表示为:
30、
31、其中,p(s'|s,a)为状态转移概率,a为实时动作,s'为s的下一时刻的状态,s为实时状态;奖励函数,表示为:
32、
33、其中,r(s,a)为奖励函数,为实数空间,为映射;在马尔可夫决策过程中,智能体在每个时刻t,基于环境的状态st,选择动作at,st为t时刻的状态,at为t时刻的动作智能体接收奖励,表示为:
34、rt+1=r(st,at)
35、其中,rt+1为t+1时刻的智能体接收的奖励,r(st,at)为基于t时刻的状态和动作获得的奖励值;环境的状态基于状态转移概率p(st+1∣st,at)转移到st+1;智能体包括配电网操作员或控制器;t时刻的状态空间st,表示为:
36、st=[pt,qt,αt,t]
37、t时刻的动作at为通过改变开关状态αt,改变网络拓扑结构,只关闭一个开关并打开另一个开关,满足网络拓扑结构为辐射状。
38、通过st和at获得新的状态空间st+1,at通过的开关的打开或闭合决定αt+1,全局变量时刻t的值,在进行每一次动作时,t值加1,用状态转移概率,表示为:
39、
40、其中,pt为状态转移概率,为概率,为t时刻状态st,进行动作at,状态转移到st+1的概率;奖励函数包括网络功率损耗、失负荷成本以及电压越限成本,表示为:
41、
42、
43、其中,rt为t时刻的智能体接收的奖励,c为电压越限值。
44、通过智能电表记录各节点功率注入pit+jqit,数据采集与监视控制系统记录变电站的有功功率和无功功率,从数据采集与监视控制系统获得节点电压值数据vit,从远程控制开关中获得开关状态αt,构建马尔可夫决策过程的状态、动作以及奖励函数。
45、通过强化学习,智能体与马尔可夫决策过程进行环境互动,不断迭代策略函数π(·∣s),在t时刻,当策略函数面对状态空间中的一个状态空间st时,将动作空间中的一个动作at进行输出,π(·∣s)的输入为实时状态空间st,实时状态st包括负载节点有功功率注入的向量,负载节点无功功率注入的向量,负载节点t时刻所有开关状态的向量,输出为动作at的概率分布,为t+1时刻开关状态的αt+1概率分布。
46、作为本发明所述的一种基于强化学习的配电网故障恢复方法的一种优选方案,其中:所述获得批量限制柔性演员-评论家算法包括将sac和批量限制强化学习结合,获得批量限制柔性演员-评论家算法。
47、sac通过策略的熵正则化奖励函数,表示为:
48、r(s,a)+τh(π(·∣s))
49、其中,r(s,a)为基于实时状态s和实时动作a获得的奖励,τ为温度参数,h(π(·∣s))为策略函数的熵,π为实时策略。
50、sac中熵正则化状态价值函数和动作价值函数表示为:
51、
52、
53、
54、其中,为基于π对动作a的期望,为基于状态转移概率p对下一个状态s′的期望,为在策略π时,下一个状态s′的状态价值函数。
55、动作价值函数包括当状态s,基于策略π,选择动作a的回报的期望值,回报指从时刻开始到回合结束的所有奖励的总合。
56、状态价值函数包括通过基于a对动作价值函数计算期望,量化状态s的好坏;价值函数和策略函数用神经网络,表示为:
57、vψ(s)、qθ(s,a)、πφ(a∣s)
58、其中,vψ(s)为通过神经网络表示的状态价值函数,qθ(s,a)为通过神经网络表示的动作价值函数,πφ(a∣s)为通过神经网络表示的策略函数,ψ、θ以及φ为神经网络的参数。
59、sac通过迭代,更新价值函数和策略函数的参数,通过价值函数的残差平方误差和动作价值函数的bellman残差的梯度,更新价值函数的参数表示为:
60、
61、其中,πnew(·∣s)为迭代结束获得的新策略,为配分函数,为基于迭代开始的策略获得的动作价值函数,为π(·∣s)和间的kl-散度。
62、作为本发明所述的一种基于强化学习的配电网故障恢复方法的一种优选方案,其中:所述获得批量限制柔性演员-评论家算法还包括状态-动作组合的外推误差∈π(s,a)和状态-动作组合的策略外推误差∈π,表示为:
63、
64、
65、其中,qπ(s,a)为真实动作价值函数,为通过批量数据进行估计的动作价值函数,为∈π(s,a)基于策略π(a∣s)对a计算期望,为基于策略μπ(s)对s计算期望,μπ为原始马尔可夫决策过程中的π引起的状态访问概率。
66、基于实时策略π,对所有状态-动作组合(s,a),当批量数据的状态转移概率等于真实值p(s′∣s,a)时,外推误差∈π=0,qπ(s,a)获得一个无误差的值。
67、作为本发明所述的一种基于强化学习的配电网故障恢复方法的一种优选方案,其中:所述获得批量限制柔性演员-评论家算法还包括历史行为策略与实时策略的差异性,为构建奖励函数的影响因素,将sac与批量限制强化学习结合,构建奖励函数。
68、历史行为策略与实时策略的差异性,是构建奖励函数的影响因素,包括从历史数据集d中获得历史行为策略,用条件变分自编码器cvae作为参数生成模型gω(a∣s),将gω(a∣s)用在行为策略πb(a|s)中。
69、cvae包括编码器cω′(z∣s,a)和解码器gω(a∣s,z),编码器将状态-动作组合映射到隐藏向量z中,解码器输出z和s采取动作a的概率,cvae最大化目标函数,获得编码器的参数ω′和解码器的参数ω,表示为:
70、
71、其中,为loggω(a∣s,z)基于编码器参数ω′的梯度dω′,对解码器输出值z计算期望,为对输出值z的期望值,p(z)为潜在变量分布,dkl(cω′(z∣s,a)||p(z))为cω′(z∣s,a)和p(z)间的kl-散度。
72、训练cvae包括从历史数据集d中采样状态-动作组合(s,a),对样本目标函数执行随机梯度上升。
73、当训练结束时,用解码器gω(a∣s,z)表示历史操作数据的行为策略。
74、将sac与批量限制强化学习结合,构建奖励函数包括kl-散度正则化与贝尔曼方程、批量限制柔性策略的评估和迭代以及批量限制柔性演员-评论家算法。
75、kl-散度正则化与贝尔曼方程包括通过目标策略和行为策略间的kl-散度正则化奖励函数,表示为:
76、rd(s,a)=r(s,a)-τdkl(π(·∣s)||πb(·∣s))
77、其中,rd(s,a)为进行修正的奖励函数,r(s,a)为原马尔可夫决策过程的奖励函数,πb(·∣s)为从历史数据集中获得的行为策略,dkl(π(·∣s)||πb(·∣s))为目标策略π(·∣s)和行为策略πb(·∣s)间的kl-散度。
78、行为策略包括观测的状态、观测的动作以及观测的奖励,在批量限制强化学习中,从历史数据中获得行为策略。
79、通过强化学习获得策略函数,基于策略函数控制智能体,kl-散度表示为:
80、dkl(π(·∣s)||πb(·∣s))=h(π(·∣s),πb(·∣s))-h(π(·∣s))
81、其中,h(π(·∣s),πb(·∣s))为π(·∣s)和πb(·∣s)的交叉熵,h(π(·∣s))为目标策略的熵。
82、交叉熵与目标策略的熵成反比;通过kl-散度正则化奖励函数,基于奖励函数,获得状态价值函数和动作价值函数bellman方程表示为:
83、
84、
85、
86、其中,为状态s′的价值;批量限制柔性策略的评估和迭代包括对实时策略π,通过批量限制柔性策略进行评估和迭代,确定动作价值函数
87、批量限制柔性策略的评估过程,表示为:
88、
89、
90、其中,为迭代过程中的算子,τ为温度参数,q(s,a)为动作价值函数,v(s′)为状态价值函数,为动作价值函数q(s′,a′),基于策略π对下一时刻动作a′计算期望,q(s′,a′)为动作价值函数,dkl(π(·∣s′)||πb(·∣s′))为π(·∣s′)和πb(·∣s′)间的kl-散度,π(·∣s′)为目标策略,πb(·∣s′)为行为策略。
91、进行初始化,表示为:
92、
93、其中,q0(s,a)为初始化的动作价值函数;状态空间和动作空间包括状态-动作组合(s,a),对任意当满足dkl(π(·∣s)||πb(·∣s))均为有界,k→∞时,序列收敛于kl-散度正则化动作价值函数k为数列序号,qk+1为第k+1个的动作价值,qk为第k个动作价值函数。
94、计算获得通过对实施策略π的参数进行调整,获得改进的策略π′。
95、批量限制柔性策略的迭代过程包括实时策略π,动作价值函数对每个迭代获得的新策略为π′(·∣s),表示为:
96、
97、其中,π′(·∣s)为迭代获得的策略,为实时迭代中的目标策略,为基于策略π′对动作a计算期望,为和πb(·∣s)间的kl-散度,为实时迭代中的目标策略。
98、对所有(s,a),且都满足为动作价值函数。
99、从任意实时策略π开始,交替使用批量限制策略评估和迭代,策略序列收敛到一个最优策略π*,对所有都满足为基于最优策略π*获得的动作价值函数。
100、作为本发明所述的一种基于强化学习的配电网故障恢复方法的一种优选方案,其中:所述获得批量限制柔性演员-评论家算法还包括评论家和演员,评论家包括和演员包括最优策略π*(a∣s),为基于最优策略π*获得的状态价值函数。
101、评论家包括通过神经网络参数化和并用bellman方程进行更新,采用目标价值网络和clipped-double q方法进行训练,训练包括设置四个神经网络vψ以及更新神经网络,表示为:
102、
103、
104、
105、
106、
107、
108、其中,θ1和θ2为q网络的神经网络参数,ψ为状态价值网络的神经网络参数,为目标状态价值网络的神经网络参数,(s,a,r,s′)为历史数据,为从历史数据集中采样的小批量,为下一状态的价值,vtarget(s)为价值网络的更新目标,为动作价值网络的输出值,为动作价值网络的输出值,为动作价值网络的输出值,为动作价值网络的输出值,为迭代中的目标策略网络,vψ(s)为价值网络vψ的输出值,为行为策略,为迭代过程中,从策略网络中获得的动作,ρ为指数平滑参数。
109、所有神经网络的输入包括状态s,价值网络vψ和输出为状态价值的单个数字,q网络的输出和为一个包括动作价值的向量,所有网络都包括隐藏层的标准前馈神经网络。
110、当通过更新神经网络训练q网络和时,参数向量保持不变,当通过vtarget(s)进行计算时,vtarget(s)中的所有参数都是固定的,对ψ进行优化。
111、从历史操作数据集中获得策略网络、价值网络以及q网络的训练数据,并转换成状态s、动作a、奖励r以及下一个状态s′的马尔可夫决策过程格式,将实时策略中采样的用于训练,且采样的动作与历史数据集中的动作不相同。
112、演员包括用φ参数化的神经网络近似策略函数πφ(·∣s),采用梯度上升更新参数,表示为:
113、
114、其中,为梯度上升,为价值网络,为计算梯度,为策略网络,为q网络,为行为策略。
115、作为本发明所述的一种基于强化学习的配电网故障恢复方法的一种优选方案,其中:所述策略网络输出开关动作包括对配电网故障恢复问题采用批量限制柔性演员-评论家算法,策略网络输出开关动作。
116、将历史数据集数据转换成状态、动作、奖励以及下一个状态元组(s,a,r,s′),历史数据集包括节点注入功率、采集的变电站数据、变电站监视控制系统的功率测量值、变电站监视控制系统的节点电压幅值以及变电站监视控制系统控制开关状态。
117、用通用深度神经网络初始化算法初始化策略网络和价值网络。
118、批量限制柔性演员-评论家算法的输入包括历史数据集和训练结束的cvae模型gω,当每次迭代时,限制柔性演员-评论家算法从批处理中进行采样,采样包括经验数据,从实时策略中进行采样操作,进行训练v网络和q网络,进行策略评估,当在每次迭代结束时,通过训练策略网络进行策略改进,策略网络通过状态-动作组合的外推误差的梯度更新参数φ,基于历史数据集在训练过程中不变,训练的cvae模型gω不进行更新。
119、限制柔性演员-评论家算法包括条件生成模型、策略网络、价值网络以及q网络。
120、在算法过程中,将收集配电网历史运行数据集,用在批量限制柔性演员-评论家算法的离线训练,条件生成模型单独进行训练。
121、基于历史行为策略与实时策略的差异性为构建奖励函数的影响因素,最大熵强化学习柔性演员-评论家算法与批量限制强化学习结合,构建奖励函数和配电网运行历史数据集,进行离线训练,获得行为策略πb(a∣s),策略网络模块包括一个训练完成的神经网络πφ(a∣s),神经网络输入网络结构和功率注入,输出一个故障恢复动作,v网络和q网络通过训练,输出的和
122、本发明的另外一个目的是提供一种基于强化学习的配电网故障恢复系统,其能通过对配电网故障恢复问题采用批量限制柔性演员-评论家算法,策略网络输出开关动作,解决了目前的配电网故障恢复方法含有效率低的问题。
123、作为本发明所述的一种基于强化学习的配电网故障恢复系统的一种优选方案,其中:包括配电网故障恢复模型转化模块,批量限制柔性演员-评论家算法模块,配电网故障恢复问题求解模块;所述配电网故障恢复模型转化模块用于构建配电网故障恢复模型,将配电网故障恢复模型转化为马尔可夫决策过程;所述批量限制柔性演员-评论家算法模块用于将最大熵强化学习柔性演员-评论家算法和批量限制强化学习结合,获得批量限制柔性演员-评论家算法;所述配电网故障恢复问题求解模块用于对配电网故障恢复问题采用批量限制柔性演员-评论家算法,策略网络输出开关动作。
124、一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序是实现一种基于强化学习的配电网故障恢复方法的步骤。
125、一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现一种基于强化学习的配电网故障恢复方法的步骤。
126、本发明的有益效果:本发明提供的一种基于强化学习的配电网故障恢复方法进行构建配电网故障恢复模型,将配电网故障恢复模型转化为马尔可夫决策过程;马尔可夫决策过程的形式化表述,为解决配电网故障恢复问题提供了一个清晰的框架,在这个框架下,系统状态、可能的动作、转移概率以及奖励函数都被明确定义,这对于设计出有效的恢复策略至关重要,实现了配电网故障恢复问题的规范化和标准化处理,为后续的算法设计和策略实施提供了坚实的基础,这不仅有助于提高解决方案的精确性和效率,还能够使问题的求解过程更加系统化和可靠;将最大熵强化学习柔性演员-评论家算法和批量限制强化学习结合,获得批量限制柔性演员-评论家算法;批量限制柔性演员-评论家算法旨在有效利用有限的历史数据进行学习,同时通过最大熵正则化鼓励策略探索,以寻找更优的解决方案,这种方法允许算法在没有与实际环境直接交互的情况下,仍能学习到有效的故障恢复策略,结合了两种算法的优点,批量限制柔性演员-评论家算法在确保学习稳定性的同时,提高了策略的泛化能力和执行效率,这为配电网故障恢复提供了一种更加灵活、高效的解决方案,能够在限制条件下获得更优的恢复策略;对配电网故障恢复问题采用批量限制柔性演员-评论家算法,策略网络输出开关动作,通过算法学习,策略网络能够根据当前电网的状态自动确定最佳的故障恢复操作,包括哪些开关应当闭合或断开,以尽快恢复正常供电,实现了配电网故障恢复过程的自动化和智能化,通过精确控制开关操作,不仅可以缩短故障恢复时间,降低故障对用户和电网的影响,还可以提高电网运营的安全性和经济性,此外,该方法还具有良好的适应性和扩展性,能够应对各种不同的故障情况,本发明在响应性、准确性以及效率性方面都取得更加良好的效果。
本文地址:https://www.jishuxx.com/zhuanli/20240808/270774.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。