一种面向大规模网络舆情的Elasticsearch检索优化系统的制作方法
- 国知局
- 2024-08-22 14:49:54
本发明涉及一种检索优化系统,特别是一种面向大规模网络舆情的elasticsearch检索优化系统。
背景技术:
1、近年来,社交平台迅速普及并快速发展,用户在网络上生成了大量社交媒体信息,包括文本、图像、视频等形式,成为了用户覆盖范围最广、信息巨大、传播速度快、社会影响广且极具发展潜力的互联网服务。社交网络形成的舆情数据中蕴含着海量信息亟需分析挖掘,多以非结构化文本数据为主,并带有丰富的图片、视频等模态信息。为了满足快速定向分析,搜索引擎在数据检索的准确性和速度上变得至关重要。传统数据库对于海量数据全文索引存储结构方面存在限制,基于elasticsearch分布式检索引擎(简称es)的开源分布式全文检索引擎应运而生,目前db搜索引擎排名第一,被广泛应用于金融、购物、社交等。
2、然而舆情数据在使用elasticsearch进行检索时仍存在如下问题:1)索引分片数如何设定;2)分片在集群节点如何放置;3)负载如何均衡。工程应用实践表明,舆情大数据具备的共同特点:一是超大的数据规模,并且持续上升;二是非结构数据占比超过整个数据集90%;三是跨平台多组合式条件查询需求;四是针对具有时效性的特征数据,数据qos会随着时间衰减。
技术实现思路
1、发明目的:本发明所要解决的技术问题是针对现有技术的不足,提供一种面向大规模网络舆情的elasticsearch检索优化系统。
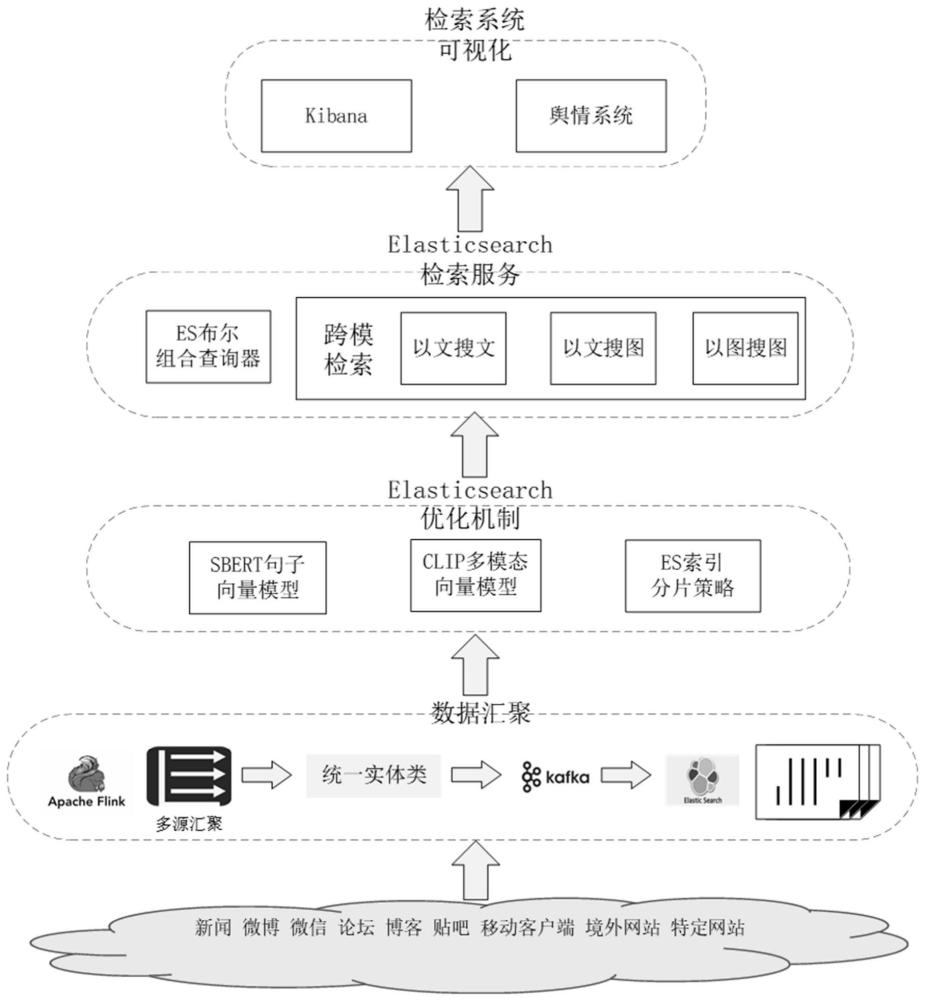
2、为了解决上述技术问题,本发明公开了一种面向大规模网络舆情的elasticsearch检索优化系统,包括:数据汇聚模块、优化机制和检索服务模块;其中:
3、所述数据汇聚模块,用于对网络舆情多模态数据,经过预处理后得到的中间数据发送到分布式消息总线kafka中,最终持久化保存到elasticsearch分布式检索引擎中;
4、所述优化机制,包括:基于深度学习模型sbert构建文本语义向量,用于实现语义检索;基于clip多模态对比学习模型将网络舆情多模态数据中的文本和图片转成文本向量和图片向量,用于向量检索;采用分片优化策略优化elasticsearch分布式检索引擎的检索性能;
5、所述检索服务模块,用于使用布尔组合查询器,基于优化机制中构建的文本语义向量、文本向量和图片向量,进行多模态检索。
6、进一步的,所述数据汇聚模块中的网络舆情多模态数据,为不同来源介质、不同媒体平台及不同格式的数据;其中,不同来源介质,至少包括:数据库、文件及采用接口方式接入。
7、进一步的,所述数据汇聚模块中的预处理,至少包括:
8、采用分布式流式计算框架flink,对所述网络舆情多模态数据进行加载、抽取和转换;
9、将网络舆情多模态数据通过md5进行关联,得到中间数据,其中,图片数据和视频数据下载后转成base64进行存储。
10、进一步的,所述优化机制,具体包括以下步骤:
11、步骤1,基于深度学习模型sbert构建文本语义向量,具体包括:
12、将网络舆情多模态数据中的文本数据中的字段采用sbert深度学习模型,构建预设维数的向量,并存储在数据库中;
13、步骤2,基于clip多模态对比学习模型将网络舆情多模态数据中的文本和图片转成文本向量和图片向量,具体包括:
14、将网络舆情多模态数据中的图片,通过预训练的clip多模态对比学习模型,编码成预设维度的向量,并存储在数据库中;
15、步骤3,采用分片优化策略优化elasticsearch分布式检索引擎的检索性能,其中,所述的分片优化策略,包括:
16、步骤3-1,建立索引冷热分离机制;
17、步骤3-2,索引分片数确定;
18、步骤3-3,设置索引分片放置策略。
19、进一步的,步骤3-1中所述的建立索引冷热分离机制,具体包括:
20、步骤3-1-1,根据数据库中的元数据信息创建索引类型;
21、步骤3-1-2,对网络舆情多模态数据中的文本数据采用全文检索字段类型,构建分词索引;
22、步骤3-1-3,将所述分词索引与其他字段索引组合成索引模板;
23、步骤3-1-4,根据所述elasticsearch分布式检索引擎的业务数据量,按预设时间段构建索引;
24、步骤3-1-5,根据所述elasticsearch分布式检索引擎的业务场景设置索引冷热机制,具体如下:
25、根据预设的qos数据服务需求,将时间最新的索引放入热数据即高配置节点上,将其他历史数据放入冷数据即低配置节点中;
26、步骤3-1-6,根据业务按照时间段为索引分段并构建别名,用于跨索引查询;
27、步骤3-1-7,定期将热数据分片迁移到冷数据即低配置节点上。
28、进一步的,步骤3-2中所述的索引分片数确定,即根据所述elasticsearch分布式检索引擎处理的数据量的大小以及所述elasticsearch分布式检索引擎的负载情况,设计索引的分片数,具体包括:
29、步骤3-2-1,对所述elasticsearch分布式检索引擎的各节点性能进行校验,同时满足以下条件则判定当前节点为可用节点,将对应节点数组nodearr[]位置置为1:
30、条件1,校验当前节点i的磁盘使用率dsi、磁盘io使用率dsioi、jvm内存使用率mri及cpu使用率cpui,若上述各指标使用率都不超过90%,则判定为满足条件1;
31、条件2,校验当前节点的现有分片数量sni,若小于当前节点i的最大分片数量mni,则判定为满足条件2;
32、步骤3-2-2,计算初始主分片数量shardnum1,具体如下:
33、
34、其中,d表示所述elasticsearch分布式检索引擎的索引业务数据量大小;
35、步骤3-2-3,计算每个节点放置的主分片数量n,具体如下:
36、
37、其中,nau表示可用节点数量;当n>x时,取n=x,其中,x表示节点i允许同一索引最大分片数量;
38、所述的可用节点个数nau,计算方法如下:
39、若任一节点的现有分片数sni与主分片数量n的和大于等于当前节点i的最大分片数量mni时,则判定该节点不可用,更新节点数组nodearr[]对应值为0,可用节点由更新后的nodearri[]数组得到,即可用节点个数为:
40、步骤3-2-4,计算初始主分片数量shardnum2,具体如下:
41、
42、步骤3-2-5,计算索引分片数shardnum,具体如下:
43、
44、其中,k1和k2为权重系数,k1+k2=1,θ为扩展系数,用于衡量索引数据量扩展度,θ∈(0,1]。
45、进一步的,步骤3-3中所述的设置索引分片放置策略,具体包括:
46、步骤3-3-1,选取性能指标参数,包括:cpu使用率、jvm内存使用率和磁盘io使用率;
47、步骤3-3-2,对所述elasticsearch分布式检索引擎中的性能指标参数进行检测,具体包括:
48、采用kibana工具进行资源监控,并以f秒为采集频率,d分钟为采集周期,计算每个采集周期的各性能指标参数的平均值,并将结果保存;基于二次指数平滑法对各性能指标参数进行预测,通过调整平滑系数α值来计算偏方差s,取偏方差s最小时对应的平滑系数α值;
49、步骤3-3-3,指标权重判定,即通过历史性能指标参数进行统计分析,采用熵值法确定指标权重,具体如下:
50、步骤3-3-3-1,构建负载信息决策矩阵m,如下:
51、
52、其中,n代表采集周期数,caun、maun和daion分别代表第n个采集周期的cpu使用率、jvm内存使用率和磁盘io使用率;
53、步骤3-3-3-2,对负载信息决策矩阵m的每列进行标准化处理,得到决策r,如下:
54、
55、其中,第t行第1列元素第t行第2列元素第t行第3列元素决策r的每一列满足归一性,即即每一列值的和为1,其中,j=1,2,3,表示指标参数的序号;
56、步骤3-3-3-3,利用熵公式计算性能指标参数的不确定度,用ej表示第j个性能指标参数的熵,如下:
57、
58、其中,常数k=1/ln(n);
59、步骤3-3-3-4,定义dj为第j个性能指标参数的贡献度,如下:
60、dj=1-ej
61、步骤3-3-3-5,计算性能指标参数的客观权重值,如下:
62、
63、其中,woj代表第j个性能指标参数的客观权重值,且wo1+wo2+wo3=1;
64、步骤3-3-4,根据客观权重值设置分片数,具体包括:
65、步骤3-3-4-1,根据步骤3-3-3得到cpu使用率、jvm内存使用率和磁盘io使用率三种指标的客观权重值分别为wo1、wo2和wo3;
66、步骤3-3-4-2,通过上述客观权重值来获得每个节点的处理能力cai,如下:
67、
68、其中,分别代表采用二次指数平滑法进行预测后得到的cpu使用率、jvm内存使用率和磁盘io使用率,i代表第i节点;
69、步骤3-3-4-3,计算每个节点应分配的数据量占比即所述的分片数,如下:
70、
71、其中,dpi代表第i节点应分配的数据量占比,m为节点数量;
72、步骤3-3-4-4,若每个节点可用分片数小于步骤3-3-4-3中计算得到的分片数,则修改该节点的分片上限参数。
73、进一步的,所述检索服务模块,具体包括:
74、所述的布尔组合查询器,对应所述elasticsearch分布式检索引擎中的布尔查询算子;
75、所述的多模态检索,至少包括:以文搜文、以文搜图和以图搜图。
76、进一步的,步骤1和步骤2中所述的预设维数为768维。
77、进一步的,步骤1和步骤2中所述的进行存储,即采用dense_vector向量类型存储。
78、有益效果:
79、1、本发明通过深度预训练模型sbert构建句子语义向量,实现语义检索,克服了传统只能进行关键词检索导致关键信息丢失的问题,增加了召回率。
80、2、本发明通过clip多模态模型构建文本和图片向量,实现以文搜图和以图搜图。
81、3、本发明在索引创建采用冷热分离、分片数设置及分片放置策略,实现集群负载均衡,降低了用户响应时延和系统软硬件开销。
82、4、本发明设计出布尔组合查询器,满足了用户复杂的业务检索场景。
83、综上所述,本发明相对传统网络舆情elasticsearch检索系统,在功能上,满足了大规模网络舆情领域复杂组合业务查询需求,实现了布尔组合、以文搜文、以文搜图和以图搜图检索功能;在性能上,信息检索召回率和时延上得到了较大提升。整体增加了用户体验,提供了强而稳定的数据支撑服务,创造了商业价值。
本文地址:https://www.jishuxx.com/zhuanli/20240822/280044.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表