一种海量数据实现高效索引和检索的方法与流程
- 国知局
- 2024-08-22 14:59:20
本发明涉及数据检索,特别涉及一种海量数据实现高效索引和检索的方法。
背景技术:
1、在信息时代,数据的处理在很多时候都需要按照指定的关键字查找出相关内容,例如,通过搜索引擎,只要输入关键字,即可查询得到与该关键字相关的内容。再例如,对数据库进行查询,可以按照某个字段查询得到该字段的全部数据。传统数据库的查询是通过在数据库中建立的索引来完成的。在某些应用环境下,需要记录的数据量是实时变化的,针对这种情况,通常的做法是建立不同粒度的索引,比如,每分钟建立一次“分钟索引数据”,每小时将所有“分钟索引数据”重新处理,建立“小时索引数据”,每天将“小时索引数据”重新处理,建立“天索引数据”,每周将“天索引数据”重新处理,建立“周索引数据”,每月将“周索引数据”重新处理,建立“月索引数据”。在上述每种索引数据中,均包括两种数据:数据文件和索引记录。其中,“月索引数据”作为最终的索引数据。数据文件为实时记录的数据,通常为磁盘上的文件,而索引记录则是放在数据库中。在进行数据查询时,需要从索引记录中读取每个要查询的关键字(比如手机号)在上述各粒度的数据文件中的位置信息,根据该位置信息打开多个数据文件,定位到每个数据文件的开始位置,读取该数据文件,并对读取的数据解压缩后匹配得到与该查询关键字相关的所有记录。
2、随着互联网的发展和智能设备的普及,海量数据的产生和存储成为了一个巨大的挑战。如何高效地处理和检索这些海量数据成为了计算机领域研究的热点之一。在这里,我们采用信息检索的方法:首先对海量数据建立索引,通过对数据索引进行检索,获取所关心的信息。在信息安全领域我们对于信息的实时性要求是非常高的,当有敏感信息出现时,我们希望用尽量短的时间来找到它。但是,海量数据自身的特点决定了对海量数据的处理有很大的困难,目前面临的问题包括:(1)海量数据的索引在空间上非常大;(2)怎样在尽可能短的时间内建立索引,即建立索引的效率:(3)如何对海量数据怎样高效的检索。
3、鉴于此,需要一种海量数据实现高效索引和检索的方法。
技术实现思路
1、针对现有技术中存在的上述问题,本发明提供了一种海量数据实现高效索引和检索的方法,能够解决了背景技术存在的问题。具体技术方案如下:
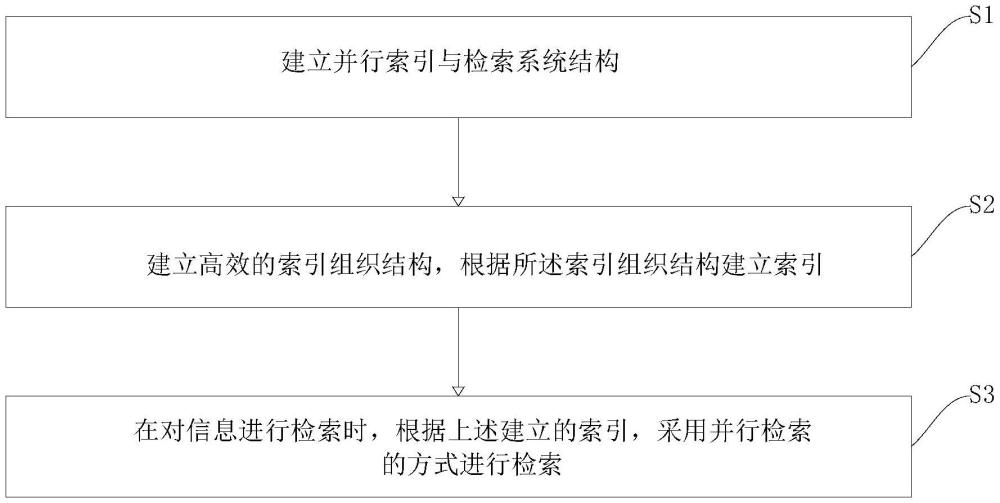
2、一种海量数据实现高效索引和检索方法,包括以下步骤:
3、建立并行索引与检索系统结构;
4、建立高效的索引组织结构,根据所述索引组织结构建立索引;
5、在对信息进行检索时,根据上述建立的索引,采用并行检索的方式进行检索。
6、优选的,所述并行索引与检索系统结构包括若干个对原始数据的存储网络的索引器,每个索引器对应一个索引,每个索引对应一个检索服务器,所有的检索服务器通过检索控制器控制。
7、优选的,所述索引组织结构为倒排文件结构,所述建立索引包括词法分析以及生成倒排文件。
8、优选的,所述词法分析中采用以词作为索引单位,且所述以词作为索引单位时,并选择对应的词表。
9、优选的,所述词表采用静态词表;在进行索引过程中,构建适合检索的中文词典、英文词典以及特殊词典;所述特殊词典包括26个英文字母,部分常用的字母组合,10个阿拉伯数字,部分代表年份的4位阿拉伯数字。
10、优选的,所述词法分析阶段生成由关键词、文档号位置信息构成的三元组。
11、优选的,将所述关键词映射成唯一的一个关键词id。
12、优选的,所述倒排文件的生成过程包括以下步骤:
13、将词法分析阶段生成的由关键词、文档号位置信息构成的三元组,把三元组按照关键词的顺序进行排序;
14、于相同的关键词将其所在的文档号和偏移位置进行合并,将合并后的结果写在倒排索引文件中;
15、再获取一部分三元组,按照上面的方法建立好倒排文件,把新生成的倒排文件与以往的倒排文件进行合并,重复上述操作直到所有文档建成索引。
16、优选的,所述词法分析阶段从磁盘中读取数据时,对不同的磁盘来进行操作,从一块磁盘中读取数据,而向另一块磁盘中写索引文件。
17、优选的,采用gamma压缩算法对索引文件的压缩
18、与现有技术相比,本发明的有益效果为:
19、本发明中,通过并行索引与检索系统结构,能够显著提高数据处理的效率和准确性,使得企业和组织能够更快地从大量复杂的数据中提取有价值的信息,从而做出更加明智的决策。
技术特征:1.一种海量数据实现高效索引和检索方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的海量数据实现高效索引和检索方法,其特征在于,所述并行索引与检索系统结构包括若干个对原始数据的存储网络的索引器,每个索引器对应一个索引,每个索引对应一个检索服务器,所有的检索服务器通过检索控制器控制。
3.根据权利要求1所述的海量数据实现高效索引和检索方法,其特征在于,所述索引组织结构为倒排文件结构,所述建立索引包括词法分析以及生成倒排文件。
4.根据权利要求3所述的海量数据实现高效索引和检索方法,其特征在于,所述词法分析中采用以词作为索引单位,且所述以词作为索引单位时,并选择对应的词表。
5.根据权利要求4所述的海量数据实现高效索引和检索方法,其特征在于,所述词表采用静态词表;在进行索引过程中,构建适合检索的中文词典、英文词典以及特殊词典;所述特殊词典包括26个英文字母,部分常用的字母组合,10个阿拉伯数字,部分代表年份的4位阿拉伯数字。
6.根据权利要求3所述的海量数据实现高效索引和检索方法,其特征在于,所述词法分析阶段生成由关键词、文档号位置信息构成的三元组。
7.根据权利要求6所述的海量数据实现高效索引和检索方法,其特征在于,将所述关键词映射成唯一的一个关键词id。
8.根据权利要求6所述的海量数据实现高效索引和检索方法,其特征在于,所述倒排文件的生成过程包括以下步骤:
9.根据权利要求3所述的海量数据实现高效索引和检索方法,其特征在于,所述词法分析阶段从磁盘中读取数据时,对不同的磁盘来进行操作,从一块磁盘中读取数据,而向另一块磁盘中写索引文件。
10.根据权利要求9所述的海量数据实现高效索引和检索方法,其特征在于,采用gamma压缩算法对索引文件的压缩。
技术总结本发明公开了一种海量数据实现高效索引和检索方法,涉及数据检索技术领域,包括以下步骤:建立并行索引与检索系统结构;建立高效的索引组织结构,根据所述索引组织结构建立索引;在对信息进行检索时,根据上述建立的索引,采用并行检索的方式进行检索。本发明通过并行索引与检索系统结构,能够显著提高数据处理的效率和准确性,使得企业和组织能够更快地从大量复杂的数据中提取有价值的信息,从而做出更加明智的决策。技术研发人员:黄安妮,符嘉成,潘俊冰,廖邓彬,陈柏龄,莫晓盈,贺冠博,廖晓芸受保护的技术使用者:广西电网有限责任公司技术研发日:技术公布日:2024/8/20本文地址:https://www.jishuxx.com/zhuanli/20240822/280681.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。