一种基于人工智能的人岗智能匹配方法及系统与流程
- 国知局
- 2024-08-22 15:08:52
本发明属于人工智能应用领域,具体是一种基于人工智能的人岗智能匹配方法及系统。
背景技术:
1、随着人工智能技术的不断进步,特别是语言模型的发展,使得计算机能够更精准地理解和处理自然语言,为人岗匹配系统提供了强大的工具和技术基础。随着全球经济的发展和劳动力市场的竞争加剧,企业和求职者对更高效、更精准的招聘匹配服务的需求日益增长,这促使了人岗智能匹配系统的迅速发展和应用。传统的招聘过程中,信息不对称和匹配效率低下常常导致效率低下和用户体验差。智能匹配系统通过数据驱动的方法,能够为用户提供个性化、精准的职位推荐,显著提升了用户体验和满意度。基于大数据分析和机器学习算法,人岗智能匹配系统能够从海量的招聘需求和求职者数据中提取有价值的信息,支持企业更精确地制定招聘策略,同时为求职者提供更符合其职业发展规划的职位推荐。
2、现有的人岗智能匹配方案,大多分别对招聘方和求职者推荐合适的信息,难以进行相互推荐,同时通过根据一方的信息出现筛选遗漏的问题,不利于为招聘方和求职者匹配到合适的信息。
技术实现思路
1、本发明旨在至少解决现有技术中存在的技术问题之一;为此,本发明提出了一种基于人工智能的人岗智能匹配方法及系统,用于解决难以进行相互推荐,同时通过根据一方的信息出现筛选遗漏的问题,不利于为招聘方和求职者匹配到合适的信息的技术问题。
2、为解决上述问题,本发明的第一方面提供了一种基于人工智能的人岗智能匹配方法,包括以下步骤:
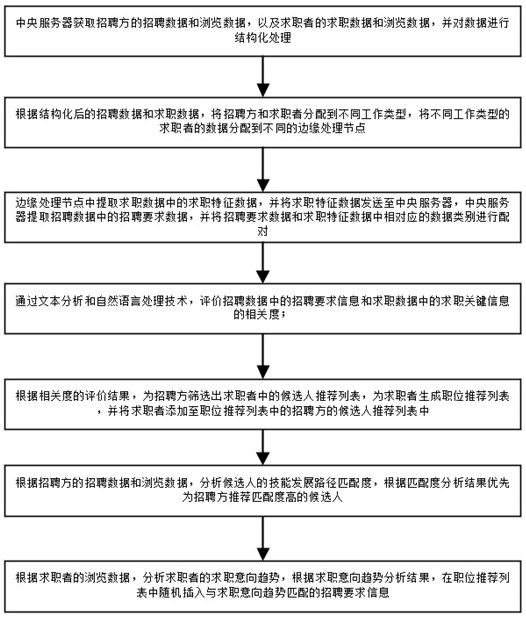
3、中央服务器获取招聘方的招聘数据和浏览数据,以及求职者的求职数据和浏览数据,并对数据进行结构化处理;通过nlp自然语言处理技术对招聘数据和求职数据进行结构化处理,并转化为结构化数据;
4、根据结构化后的招聘数据和求职数据,将招聘方和求职者分配到不同工作类型,将不同工作类型的求职者的数据分配到不同的边缘处理节点;
5、边缘处理节点中提取求职数据中的求职特征数据,并将求职特征数据发送至中央服务器,中央服务器提取招聘数据中的招聘要求数据,并将招聘要求数据和求职特征数据中相对应的数据类别进行配对,通过文本分析和自然语言处理技术,评价招聘数据中的招聘要求信息和求职数据中的求职关键信息的相关度;
6、根据相关度的评价结果,为招聘方筛选出求职者中的候选人推荐列表,为求职者生成职位推荐列表,并将求职者添加至职位推荐列表中的招聘方的候选人推荐列表中;
7、根据招聘方的招聘数据和浏览数据,分析候选人的技能发展路径匹配度,根据匹配度分析结果优先为招聘方推荐匹配度高的候选人;
8、根据求职者的浏览数据,分析求职者的求职意向趋势,根据求职意向趋势分析结果,在职位推荐列表中随机插入与求职意向趋势匹配的招聘要求信息。
9、作为本发明进一步的方案:根据结构化后的招聘数据和求职数据,将招聘方和求职者分配到不同工作类型,将不同工作类型的求职者的数据分配到不同的边缘处理节点,包括以下步骤:
10、根据结构化后的招聘数据和求职数据,获取招聘方的招聘意向和求职者的工作领域;
11、将招聘方和求职者分配到不同的工作类型,包括:技术类型、金融与财务类型、医疗类型、销售类型、教培类型、媒体类型、制造类型、法律类型和艺术类型。
12、作为本发明进一步的方案:招聘要求数据包括:技能要求、教育背景要求、工作经验要求、项目成果要求和薪资范围;
13、求职特征数据包括:技能、教育背景、工作经验、项目成果和薪资要求。
14、作为本发明进一步的方案:将招聘要求数据和求职特征数据中相对应的数据类别进行配对,通过文本分析和自然语言处理技术,评价招聘数据中的招聘要求信息和求职数据中的求职关键信息的相关度,包括以下步骤:
15、将招聘要求数据和求职特征数据中,关于技能、教育、工作经验、项目成果和薪资的相对应的数据类别进行配对;
16、将文本统一成标准格式,将所有文字转换为中文,并对缩写词进行扩充;
17、通过jieba分词技术,将每个数据类别中的文本拆分为词组;
18、通过tf-idf算法,计算每个词组在文档中的tf-idf值,根据招聘要求数据和求职特征数据中,每个数据类别中词组的tf-idf值,筛选每个数据类别的关键词;
19、通过word2vec语言模型,将关键词映射到高维空间中,计算招聘要求数据和求职特征数据中,对应数据类别中的关键词的相似度;
20、通过glove词向量模型,通过统计招聘要求数据和求职特征数据中,每个数据类别中词组中各词组数据进行匹配,根据匹配的词组构建对应的词向量;评估招聘要求数据和求职特征数据中,每个数据类别中对应词向量的余弦相似度,将得到的余弦相似度转换为百分比,计算对应数据类别语义匹配程度;
21、根据对应数据类别中的关键词之间的相似度和评估的对应数据类别语义匹配程度,计算招聘数据中的招聘要求信息和求职数据中的求职关键信息的相关度评价值。
22、作为本发明进一步的方案:评估招聘要求数据和求职特征数据中,每个数据类别中对应词向量的余弦相似度,将得到的余弦相似度转换为百分比,计算对应数据类别语义匹配程度,包括以下步骤:
23、计算招聘要求数据和求职特征数据中,每个数据类别中对应词向量的余弦相似度,通过以下公式进行:
24、
25、其中,cosvj为第j个对应词向量对的余弦相似度,v1j为数据类别中第j个词向量,v2j为数据类别中与第j个词向量对应的词向量,v1j·v2j表示词向量v1j和v2j的点积,∣v1j∣和∣v2j∣是第j个对应词向量对的向量范数;
26、将得到的余弦相似度转换为百分比,计算对应数据类别语义匹配程度,通过以下公式进行转换:
27、
28、其中,sy为对应数据类别语义匹配程度,j∈(1,2,…,m),m为对应词向量的总数。
29、作为本发明进一步的方案:将对应数据类别中的关键词的相似度和评估的对应数据类别语义匹配程度,计算招聘数据中的招聘要求信息和求职数据中的求职关键信息的相关度评价值,包括以下步骤:
30、将对应数据类别中的关键词的相似度,根据关键词的tf-idf值,通过以下公式,计算关键词整体相似度评价值:
31、
32、其中,sg为关键词整体相似度评价值,tfi为第i个关键词的tf-idf值,si为第i个关键词相似度,i∈(1,2,…,n),n为关键词的总数;
33、根据关键词整体相似度评价值和对应数据类别语义匹配程度,计算招聘数据中的招聘要求信息和求职数据中的求职关键信息的相关度评价值。
34、作为本发明进一步的方案:通过以下公式,计算招聘数据中的招聘要求信息和求职数据中的求职关键信息的相关度评价值:
35、
36、其中,e为招聘要求信息和求职关键信息对应数据类别的相关度评价值。
37、作为本发明进一步的方案:根据招聘方的招聘数据和浏览数据,分析候选人的技能发展路径匹配度,根据匹配度分析结果优先为招聘方推荐匹配度高的候选人,包括以下步骤:
38、获取求职特征数据中的技能、工作经验和项目成果数据,通过自然语言处理技术提取能力关键词;例如编程语言、软件工具、领域专业知识等。
39、对于每个能力关键词,以时间序列数据,记录候选人在不同时间点上的技能信息;
40、通过时间序列数据,分析能力关键词之间的关联;
41、基于关联分析的结果,将能力关键词进行分组,筛选两年内分组中能力关键词数量增长最多的分组,将筛选出的能力关键词分组设定为候选人的技能发展方向技能分组;
42、获取招聘方的招聘要求信息和浏览数据,通过自然语言处理技术提取招聘方的招聘要求信息和浏览数据中的能力关键词,将提取出的关键词的集合作为招聘能力关键词分组;
43、候选人的技能发展方向技能分组与招聘能力关键词分组之间进行匹配度分析,将分析结果作为候选人的技能发展路径匹配度,根据匹配度分析结果优先为招聘方推荐匹配度高的候选人。
44、作为本发明进一步的方案:根据求职者的浏览数据,分析求职者的求职意向趋势,根据求职意向趋势分析结果,在职位推荐列表中随机插入与求职意向趋势匹配的招聘要求信息,包括以下步骤:
45、根据求职者的浏览数据,提取浏览数据中的访问职位类别、关键词搜索记录和访问职位招聘要求信息关键词;
46、提取访问职位类别数据的关键词,将访问职位类别数据的关键词和关键词搜索记录和访问职位招聘要求信息关键词,组成求职意向关键词分组;
47、对求职意向关键词分组中的关键词中间进行关联分析,将关联分析结果,将关联度大于预设阈值的关键词分组到同一求职意向的子群组;
48、分析每个求职意向的子群组中,最近半年内关键词增长趋势,将关键词增长趋势最快的求职意向的子群组作为求职者的最新求职意向组;
49、分析求职者的最新求职意向组中的关键词与招聘方招聘数据中的招聘要求信息的相关度,根据相关度分析结果筛选招聘方的招聘要求信息,并将筛选出的招聘方的招聘要求信息随机插入到求职者的职位推荐列表中。
50、作为本发明另一方面的方案:一种基于人工智能的人岗智能匹配系统,包括:
51、数据结构化处理模块:中央服务器获取招聘方的招聘数据和浏览数据,以及求职者的求职数据和浏览数据,并对数据进行结构化处理;通过nlp自然语言处理技术对招聘数据和求职数据进行结构化处理,并转化为结构化数据;
52、数据分配模块:根据结构化后的招聘数据和求职数据,将招聘方和求职者分配到不同工作类型,将不同工作类型的求职者的数据分配到不同的边缘处理节点;
53、相关度分析模块:边缘处理节点中提取求职数据中的求职特征数据,并将求职特征数据发送至中央服务器,中央服务器提取招聘数据中的招聘要求数据,并将招聘要求数据和求职特征数据中相对应的数据类别进行配对,通过文本分析和自然语言处理技术,评价招聘数据中的招聘要求信息和求职数据中的求职关键信息的相关度;
54、推荐列表构建模块:根据相关度的评价结果,为招聘方筛选出求职者中的候选人推荐列表,为求职者生成职位推荐列表,并将求职者添加至职位推荐列表中的招聘方的候选人推荐列表中;
55、候选人推荐模块:根据招聘方的招聘数据和浏览数据,分析候选人的技能发展路径匹配度,根据匹配度分析结果优先为招聘方推荐匹配度高的候选人;
56、求职意向分析模块:根据求职者的浏览数据,分析求职者的求职意向趋势,根据求职意向趋势分析结果,在职位推荐列表中随机插入与求职意向趋势匹配的招聘要求信息。
57、与现有技术相比,本发明的有益效果是:
58、本发明通过将不同工作类型的求职者的数据分配到不同的边缘处理节点,增强对求职者数据的保护,提高数据安全性和隐私保护水平;同时,将处理任务分配到多个边缘节点上可以有效地分担中央服务器的负荷,支持系统的水平扩展,适应处理大规模数据和复杂计算的需求。边缘节点可以存储和处理部分数据,即使在无法访问中央服务器的情况下,仍能够进行部分数据处理和分析,增强系统的稳定性和可靠性。通过文本分析和自然语言处理技术,评价招聘数据中的招聘要求信息和求职数据中的求职关键信息的相关度,可以更精确地理解求职者的兴趣和偏好,从而为其推荐符合其求职意向的职位,提高招聘匹配的效率和成功率。
59、本发明通过根据相关度的评价结果,为招聘方筛选出求职者中的候选人推荐列表,为求职者生成职位推荐列表,并将求职者添加至职位推荐列表中的招聘方的候选人推荐列表中;通过相关度评价结果精确地匹配求职者和招聘方的需求,从而提高候选人与职位的匹配度,减少招聘过程中的误配情况,提升招聘效率和成功率。通过构建推荐列表,求职者生成职位推荐列表,并将求职者添加至职位推荐列表中的招聘方的候选人推荐列表中,相互推荐的模式,避免通过根据一方的信息出现筛选遗漏的问题,提升了求职者和招聘方的满意度和体验,使他们更容易找到合适的职位或候选人。
本文地址:https://www.jishuxx.com/zhuanli/20240822/281369.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。