一种基于区块链的资产处理溯源方法及系统与流程
- 国知局
- 2024-08-22 15:11:10
本技术涉及资产溯源领域,特别涉及一种基于区块链的资产处理溯源方法及系统。
背景技术:
1、随着经济全球化的深入发展和金融市场的日益复杂,资产处理已成为各行业共同关注的焦点。传统的资产处理方式往往依赖于中心化的管理模式,存在着数据不透明、流程不规范、风险难控等诸多问题,难以适应当前复杂多变的经济环境和监管要求。特别是在资产溯源领域,由于涉及环节众多、数据来源分散、流转路径复杂,导致资产溯源效率低下,难以实现资产全生命周期的可视化管理和风险防控。
2、为了应对这些挑战,区块链技术由于其去中心化、不可篡改和透明性的特点,已被认为是解决资产溯源问题的一种有效技术。然而,即使是在区块链应用中,传统的资产溯源方法仍面临处理效率低下和数据处理能力有限的问题。
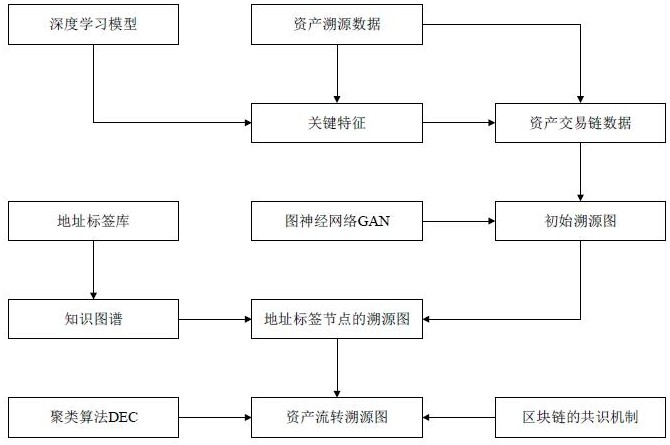
3、在相关技术中,比如中国专利文献cn117829990a中提供了一种基于区块链的资产流转溯源方法、装置、设备及存储介质,涉及区块链技术领域,展示资产从源头到终点的路径和交易记录,对资产的流向和所有权变更进行可视化。所述方法包括:获取数据仓库中存储的多条资产溯源数据进行预处理,并对预处理后的资产溯源数据进行特征匹配,将资产溯源数据归纳为多个资产交易链数据;将多个资产交易链数据输入至图神经网络模型,构建初始溯源图;获取地址标签库;根据地址标签库,将初始溯源图中的地址节点替换为对应的地址标签节点,并对地址标签节点进行聚类,得到资产流转溯源图。但是该方案在构建溯源图时主要依赖于地址库标签,用于替换初始溯源图中的地址节点为对应的标签节点,需要维护和更新标签库,在节点替换和映射过程中,需要耗费大量的节点算力,因此该方案的溯源效率有待进一步提高。
技术实现思路
1、针对现有技术中存在的资产溯源效率低的问题,本技术提供了一种基于区块链的资产处理溯源方法及系统,通过图神经网络构建初始溯源图,利用聚类算法对地址标签节点进行聚类等,提高了资产溯源效率。
2、技术方案,本技术的目的通过以下技术方案实现。
3、本说明书的一个方面提供一种基于区块链的资产处理溯源方法,包括:数据预处理阶段:从分布式数据仓库中获取原始的资产溯源数据,这些数据通常包括资产交易记录、地址信息、时间戳等。对原始数据进行清洗、格式转换、字段提取等预处理操作,去除噪声数据,将数据转换为便于后续处理的结构化形式。预处理后的资产溯源数据将作为后续特征提取和资产交易链划分的输入。特征提取与资产交易链划分阶段:将预处理后的资产溯源数据输入到预训练的深度学习模型中,如卷积神经网络(cnn)或循环神经网络(rnn),提取数据的关键特征。这些特征刻画资产交易行为的模式、异常等信息。根据提取的关键特征,采用聚类或分类算法将资产溯源数据划分为多个资产交易链数据。每个资产交易链数据包含至少两个地址信息,表示资产在这些地址之间的转移过程。资产交易链数据将作为下一步构建初始溯源图的输入。构建初始溯源图阶段:将资产交易链数据输入到图神经网络(graph attention network)中,构建初始溯源图。在初始溯源图中,每个节点表示一个地址,节点之间的边表示相连的两个地址节点之间的资产转移信息,如转移金额、时间戳等。通过图神经网络对节点和边的特征进行学习和更新,捕捉资产流转过程中的关键信息和模式。将构建好的初始溯源图经过数字签名和哈希运算后上传到区块链网络中,确保数据的完整性和不可篡改性。构建知识图谱阶段:获取预先构建好的地址标签库,其中每个地址标签表示一个实体(如个人、机构、项目等)对应的至少一个资产地址。基于地址标签库构建知识图谱,采用实体-关系-属性的三元组形式表示地址标签与实体之间的语义关联,(地址a,属于,个人x),(个人x,投资,项目y)等。将地址标签库和知识图谱经过数字签名和哈希运算后上传到区块链网络中,方便后续溯源图构建过程中的节点映射和语义推理。溯源图节点映射阶段:将初始溯源图与知识图谱进行匹配,对于初始溯源图中的每个地址节点,在知识图谱中查找对应的地址标签节点。如果匹配成功,则用知识图谱中的地址标签节点替换初始溯源图中的地址节点;如果匹配失败,则保留原有的地址节点。节点映射完成后,通过区块链网络的共识机制(如工作量证明、权益证明等)对映射结果进行验证,确保映射过程的正确性和一致性。验证通过后,将映射后的溯源图作为地址标签节点的溯源图,并将其上传到区块链网络中。溯源图聚类阶段:将地址标签节点的溯源图输入到基于深度学习的聚类算法(deep embedded clustering)中进行聚类分析。通过深度神经网络学习地址标签节点的低维嵌入表示,并在嵌入空间中采用k-means等聚类算法对节点进行聚类。聚类过程通过最小化节点嵌入与聚类中心之间的距离,同时最大化不同聚类簇之间的距离,得到最优的聚类结果。将聚类结果通过区块链网络的共识机制进行验证,确保不同节点对聚类结果达成一致。将一致性验证后的聚类结果作为最终的资产流转溯源图,并将其上传到区块链网络中,方便后续的溯源查询和分析。
4、优选的,在阶段,为了提高金融数据溯源效率,采取以下几种数据预处理技术和方法:对异常值进行识别和处理,如通过统计方法(如z-score、箱线图等)或领域知识设定阈值,识别异常的交易金额、频次等,并进行删除或修正。对时间戳字段进行格式化处理,转换为统一的日期时间格式(如iso8601),并根据需要对时间戳进行时区调整。对金额字段进行单位规范化处理,将所有金额转换为统一的币种和单位(如人民币元),便于后续的汇总计算和比较分析。将来自不同数据源(如不同银行、支付机构等)的资产溯源数据进行集成,根据共同的字段(如交易id、地址等)进行数据匹配和合并。对集成后的数据进行一致性检查,确保相同实体的属性在不同数据源中的一致性,如地址信息、实体名称等。基于原始字段衍生出新的特征,如根据交易时间戳计算交易频次、交易间隔等,根据交易金额计算账户余额、资金流入流出等。
5、优选的,优化知识图谱的构建过程,提高地址标签与实体之间语义关联的表示能力,采用将地址标签库中的实体、关系、属性转换为符号化的表示形式,如(实体1,关系,实体2)、(实体,属性,属性值)等三元组形式。采用知识图谱嵌入模型(如transe、transr等)对三元组进行训练,学习实体、关系、属性在低维向量空间中的分布式表示。transe模型通过优化(h+r≈t)的目标函数,学习实体和关系的向量表示,使得对于正确的三元组(h,r,t),实体h的向量加上关系r的向量应该接近实体t的向量。transr模型在transe的基础上,引入了关系特定的映射矩阵,将实体和关系映射到不同的向量空间,提高了知识图谱嵌入的表达能力。通过知识图谱嵌入,在低维向量空间中度量实体、关系、属性之间的语义相似性,发现隐含的语义关联,为后续知识图谱构建提供更加丰富和准确的先验知识。根据地址标签库和知识图谱嵌入的结果,构建初始的知识图谱,其中节点表示实体,边表示实体之间的关系,节点和边的属性分别表示实体和关系的属性。采用图神经网络(如gcn、gat等)对知识图谱进行表示学习,学习节点的低维嵌入表示。gcn(graph convolutional network)通过在图结构上定义卷积操作,聚合节点的邻居信息,更新节点的特征表示。通过图神经网络的表示学习,在保留知识图谱结构信息的同时,学习节点的低维语义表示,提高知识图谱的表达能力和泛化能力。将知识图谱的节点和边信息进行序列化,转换为key-value对的形式。其中,key是节点或边的唯一标识符,value是节点或边的属性信息。采用区块链的状态数据库(如leveldb、rocksdb等)存储序列化后的知识图谱数据。状态数据库以key-value对的形式存储数据,支持快速的随机读写操作。在区块链网络中,每个节点都维护一份完整的状态数据库副本,通过共识机制确保不同节点之间状态数据库的一致性。当有新的知识图谱更新操作时,先将更新操作以事务的形式提交到区块链网络,经过共识验证后,再执行状态数据库的更新。通过将知识图谱存储在区块链的状态数据库中,利用区块链的不可篡改性和可追溯性,确保知识图谱数据的安全和可信。同时,区块链网络的分布式存储也提高了知识图谱的可用性和容错性。基于构建好的知识图谱,进行各种知识推理和查询操作,如实体链接、关系预测、属性补全等。利用知识图谱嵌入模型,计算实体、关系、属性之间的语义相似度,实现语义搜索和推荐等应用。
6、优选地,在阶段,根据知识图谱中的地址标签,将初始溯源图中的地址节点替换为对应的地址标签节点,并利用区块链的共识机制对节点替换结果进行验证,得到地址标签节点的溯源图。将知识图谱数据存储在图数据库(如neo4j)中。建立地址hash值到地址标签节点的倒排索引,加速后续的查询过程。从区块链的状态数据库中读取初始溯源图数据,包括地址节点、边信息等。将初始溯源图数据加载到内存中,形成图数据结构。遍历初始溯源图中的每个地址节点,根据地址hash值在图数据库中查询对应的地址标签节点。利用倒排索引加速查询过程,快速定位到潜在的匹配节点。对于每个地址节点,计算其与查询到的地址标签节点的字符串相似度(如编辑距离)。设定相似度阈值(如0.8),用于判断是否匹配成功。如果相似度大于等于阈值,则将地址节点替换为对应的地址标签节点。如果相似度小于阈值,则暂时保留原有的地址节点,并记录到未匹配列表中。在替换节点的同时,更新溯源图的边信息。采用增量更新的方式,只更新与替换节点相关的边。将节点替换和边更新操作封装在一个事务中,保证原子性和一致性。采用分布式图处理框架(如apache giraph)对溯源图进行并行化处理。将节点替换和边更新的任务分发到多个计算节点上,提高处理效率。处理完成后,生成地址标签节点的溯源图。将溯源图数据序列化为protocol buffers格式,并采用差分编码和数据压缩技术,减小数据的存储和传输开销。将序列化后的溯源图数据构建为区块链交易。通过状态通道技术将多次更新操作合并为一次状态转换,减少区块链的交易确认等待时间。将构建好的区块链交易广播到区块链网络中。区块链网络中的节点接收到交易后,对交易进行验证和共识。
7、进一步的,在阶段,采用深度学习模型对预处理后的资产溯源数据进行特征提取。对原始的资产溯源数据进行清洗、转换和标准化等预处理操作。将预处理后的资产溯源数据按照时间序列的方式组织,形成时序数据。将时序数据划分为固定长度的时间窗口,每个时间窗口表示一个数据样本。将预处理后的资产溯源数据输入卷积神经网络中。通过卷积层对输入数据进行卷积操作,提取局部特征。卷积层通过滑动卷积核对输入数据进行扫描,生成特征图(feature map)。通过池化层对特征图进行下采样,减小特征图的尺寸,提取显著特征。经过多个卷积层和池化层的叠加,得到局部特征向量。将卷积神经网络提取的局部特征向量输入至循环神经网络中。循环神经网络采用多层长短期记忆网络(lstm)和注意力机制。通过多层lstm对局部特征向量进行时序特征提取,捕捉特征在时间维度上的依赖关系。每一层lstm接收上一层lstm的输出和当前时间步的局部特征向量,生成当前时间步的隐藏状态。通过多层lstm的堆叠,提取局部特征向量的多尺度时序特征,得到多尺度时序特征向量。在循环神经网络的基础上引入注意力机制,加强对关键时序特征的关注。通过计算多尺度时序特征向量在不同时间步的相似度,生成注意力分布。相似度计算采用点积、余弦相似度等方法。根据注意力分布,调整不同时间步的多尺度时序特征的重要性权重。重要性权重较高的时间步表示对应的时序特征更加重要,需要给予更多关注。根据调整后的重要性权重,对多尺度时序特征向量进行加权求和。加权求和的结果作为最终的时序特征向量。时序特征向量包含了资产溯源数据在时间维度上的关键特征信息。将卷积神经网络提取的局部特征向量和循环神经网络提取的时序特征向量进行拼接。拼接后的特征向量作为资产溯源数据的关键特征表示。关键特征向量包含了资产溯源数据的局部特征和时序特征,全面刻画了数据的特征信息。将拼接后的关键特征向量输出,供后续的任务使用,如资产溯源、风险评估等。关键特征向量作为下游任务的输入,如传入分类器、聚类算法等。
8、其中,局部特征提取是指从数据的局部区域中提取有意义的特征表示。在资产溯源数据的场景中,局部特征理解为数据在某个特定时间窗口或区间内的显著特征。这些特征能够刻画资产在局部范围内的行为模式、交易特点等信息。通过提取局部特征,捕捉资产溯源数据在不同时间段或区间内的关键信息,为后续的时序特征提取和整体特征表示提供基础。优选地,使用卷积神经网络对预处理后的资产溯源数据进行局部特征提取,包括:在卷积层中引入空洞卷积,通过在卷积核中插入空洞(零值),扩大卷积核的感受野。空洞卷积在不增加参数量和计算量的情况下,捕捉更大范围内的局部特征。通过调整空洞率(dilation rate),控制卷积核感受野的大小,提取不同尺度的局部特征。
9、进一步的,在将局部特征向量和时序特征向量拼接,作为关键特征的过程中,采用注意力机制和全连接层对特征进行加权融合和非线性变换。对局部特征向量和时序特征向量分别应用注意力机制。通过注意力机制计算局部特征向量中每个特征的局部重要性权重。同样地,通过注意力机制计算时序特征向量中每个特征的时序重要性权重。注意力机制采用自注意力机制、键值对注意力机制等方式实现。根据局部重要性权重和时序重要性权重,对局部特征向量和时序特征向量进行加权融合。将局部特征向量与其对应的局部重要性权重进行逐元素相乘,得到加权后的局部特征向量。将时序特征向量与其对应的时序重要性权重进行逐元素相乘,得到加权后的时序特征向量。将加权后的局部特征向量和时序特征向量进行拼接或相加,得到融合特征向量。将融合特征向量输入全连接层,通过全连接层对融合特征向量进行非线性变换。全连接层采用多层结构,每层之间使用非线性激活函数进行非线性变换。全连接层的计算过程如下:第一层:对融合特征向量x进行线性变换,并应用非线性激活函数g,得到第一层的输出:。第二层:对第一层的输出进行线性变换,并应用非线性激活函数h,得到第二层的输出:。特征交互层:将第二层的输出与交互特征矩阵进行特征叉乘,捕获不同特征之间的高阶交互和组合关系:。第三层:对特征交互层的输出进行线性变换,并应用非线性激活函数r,得到第三层的输出:。
10、第四层:将第三层的输出与原始融合特征向量x进行拼接,并进行线性变换,最后应用非线性激活函数f,得到关键特征向量y:。全连接层的输出即为关键特征向量y。关键特征向量综合了局部特征和时序特征的信息,并通过注意力机制和全连接层的非线性变换,提取了高层次的抽象特征表示。关键特征向量用于后续的任务,如资产溯源、风险评估等。
11、具体的,融合特征向量x首先通过第一层、第二层的非线性变换g和h提取高阶交互特征和抽象特征,然后在第二层和第三层之间引入特征交互层,通过特征叉乘操作⊗显式地建模不同特征之间的高阶交互和组合关系,得到交互增强的抽象特征。接着,通过第三层的非线性变换r和残差连接对抽象特征进行优化和增强,最后通过第四层的非线性变换f进行特征筛选和组合,得到最终的关键特征向量y。在第二层和第三层之间引入特征交互层,通过特征叉乘操作显式地建模不同特征之间的高阶交互和组合关系,将第二层非线性变换的输出通过权重矩阵和偏置项进行线性变换,得到交互特征矩阵:;将第二层非线性变换的输出与交互特征矩阵进行特征叉乘操作,生成高阶交互特征矩阵:;特征叉乘操作通过将两个特征矩阵按元素相乘,然后展平为向量来实现,捕获不同特征之间的高阶交互和组合关系。将高阶交互特征矩阵输入到第三层非线性变换中,得到交互增强的抽象特征:。最后,将交互增强的抽象特征与残差连接相加,并输入到第四层非线性变换中,得到最终的关键特征向量。通过引入特征交互层,能够显式地建模不同特征之间的高阶交互和组合关系,捕获特征之间的相关性和依赖性,挖掘融合特征向量中蕴含的复杂非线性关系,提高关键特征提取的表达能力和精度。特征交互层作为一种补充和增强机制,与残差连接和多层非线性变换相结合,进一步提升了关键特征提取的性能和泛化能力。
12、进一步的,将预处理后的资产溯源数据按关键特征划分为多个资产交易链数据。对预处理后的资产溯源数据进行关键特征提取,获得每个资产溯源数据的关键特征向量。关键特征提取采用卷积神经网络和循环神经网络相结合的方式,如前面所述的技术方案。计算预处理后的资产溯源数据的关键特征向量之间的欧式距离,作为关键特征相似度。欧式距离计算公式如下:,其中,x和y表示两个关键特征向量,i表示向量的维度。欧式距离越小,表示两个资产溯源数据的关键特征越相似。采用预训练的语言模型对预处理后的资产溯源数据进行语义编码,得到语义向量。预训练的语言模型是bert、gpt等大规模语言模型,它们在大量文本数据上进行预训练,能够捕捉词汇和句子的语义信息。将资产溯源数据输入预训练的语言模型,通过前向传播得到相应的语义向量表示。计算语义向量之间的余弦相似度,作为语义相似度。余弦相似度计算公式如下:,其中,x和y表示两个语义向量,dot表示向量点积,norm表示向量的l2范数。余弦相似度的取值范围在-1到1之间,值越大表示两个资产溯源数据的语义越相似。根据得到的关键特征相似度和语义相似度,采用聚类算法对预处理后的资产溯源数据进行聚类。聚类算法选择k-means、dbscan、层次聚类等常用的聚类算法。将关键特征相似度和语义相似度作为聚类算法的输入特征,通过优化聚类目标函数,将相似的资产溯源数据划分到同一个聚类中。聚类算法的目标是最小化类内距离,最大化类间距离,使得同一个聚类内的资产溯源数据在关键特征和语义上都相似,不同聚类之间的资产溯源数据在关键特征和语义上有明显区别。根据聚类结果,将预处理后的资产溯源数据划分为多个资产交易链数据。每个聚类对应一个资产交易链,包含了关键特征和语义上相似的资产溯源数据。资产交易链数据表示了资产在不同交易环节之间的流转和关联关系,体现了资产的溯源过程。
13、进一步的,根据得到的关键特征相似度和语义相似度,采用聚类算法对预处理后的资产溯源数据进行聚类,包括:将得到的关键特征相似度和语义相似度进行归一化处理,使它们的取值范围统一到[0,1]之间。归一化处理采用最大-最小归一化(min-maxnormalization)或者z-score归一化等方法。归一化处理后,关键特征相似度和语义相似度具有相同的尺度,便于后续的融合和计算。将归一化处理后的关键特征相似度和语义相似度进行加权融合。根据关键特征相似度和语义相似度的重要性,分配不同的权重系数。加权融合的公式如下:,其中,和分别表示关键特征相似度和语义相似度的权重系数,满足。加权融合后得到的融合相似度综合考虑了关键特征和语义两个方面的相似性。
14、具体的,构建融合相似度矩阵包括:将预处理后的资产溯源数据表示为一个列表或数组,记为data_list。data_list中的每个元素表示一个资产溯源数据,包含了该数据的关键特征和语义信息。记录资产溯源数据的数量为n。创建一个大小为n×n的零矩阵,记为similarity_matrix。similarity_matrix的行和列分别对应资产溯源数据的索引。矩阵的每个元素初始化为0,表示尚未计算相似度。使用两层嵌套循环遍历资产溯源数据列表data_list。外层循环变量i从0到n-1,表示当前处理的资产溯源数据的索引。内层循环变量j从i+1到n-1,表示与当前资产溯源数据进行比较的其他资产溯源数据的索引。对于每对资产溯源数据data_list[i]和data_list[j],计算它们之间的融合相似度。融合相似度的计算方法如下:提取data_list[i]和data_list[j]的关键特征向量,分别记为feature_i和feature_j。计算feature_i和feature_j之间的欧式距离,记为feature_distance。提取data_list[i]和data_list[j]的语义向量,分别记为semantic_i和semantic_j。计算semantic_i和semantic_j之间的余弦相似度,记为semantic_similarity。对feature_distance和semantic_similarity进行归一化处理,得到归一化后的相似度值。将归一化后的feature_distance和semantic_similarity进行加权融合,得到融合相似度fusion_similarity。
15、将计算得到的融合相似度fusion_similarity赋值给similarity_matrix[i][j]和similarity_matrix[j][i]。由于相似度矩阵是对称的,所以similarity_matrix[i][j]和similarity_matrix[j][i]的值相同。将融合相似度矩阵similarity_matrix的对角线元素设置为1。对角线元素表示每个资产溯源数据与自身的相似度,通常设置为最大值1。返回构建完成的融合相似度矩阵similarity_matrix。similarity_matrix是一个对称矩阵,其中每个元素similarity_matrix[i][j]表示资产溯源数据i和j之间的融合相似度。通过嵌套循环遍历资产溯源数据列表,计算每对资产溯源数据之间的融合相似度,并将结果存储在相似度矩阵中。融合相似度的计算综合考虑了关键特征相似度和语义相似度,通过加权融合的方式得到最终的相似度值。
16、基于融合相似度矩阵,采用kruskal算法构建预处理后的资产溯源数据的最小生成树。最小生成树表示预处理后的资产溯源数据在融合相似度空间中的最小连通子图。kruskal算法通过贪心策略,依次选择权重最小的边,构建最小生成树。得到最小生成树的边集合和对应的边权重集合,其中边权重表示两个资产溯源数据之间的融合相似度。根据最小生成树的边权重集合,采用截断距离算法确定hdbscan聚类的参数eps和参数min_samples。将边权重集合按顺序排序,通过截断距离算法获取权重分布的拐点。将拐点对应的边权重作为参数eps,表示聚类的邻域半径。将拐点之前的边数量作为参数min_samples,表示形成高密度区域所需的最小样本数。将融合相似度矩阵作为hdbscan聚类的输入,根据确定的参数eps和参数min_samples进行聚类。
17、hdbscan聚类采用密度可达的方式对资产溯源数据进行聚合,将密度相连的数据点划分到同一个聚类中。通过hdbscan聚类得到初步的划分结果,每个聚类对应一个资产交易链。对初步的划分结果进行层次聚类,计算资产交易链数据之间的平均相似度。平均相似度表示两个资产交易链中所有数据点之间相似度的平均值。将平均相似度大于预设阈值的资产交易链数据进行合并,形成更大的资产交易链。合并操作通过迭代的方式进行,直到无法再进行合并为止。经过层次聚类和合并后,得到最终的资产交易链数据划分结果。每个资产交易链包含了一组关键特征和语义上相似的资产溯源数据,表示资产在不同交易环节之间的流转和关联关系。
18、进一步的,采用密度可达的方式对资产溯源数据进行聚合,包括:将预处理后的资产溯源数据表示为一个列表或数组,记为data_list。data_list中的每个元素表示一个资产溯源数据,包含了该数据的关键特征和语义信息。记录资产溯源数据的数量为n。设置hdbscan聚类算法的参数eps和min_samples。eps表示聚类的邻域半径,min_samples表示形成高密度区域所需的最小样本数。这两个参数通过最小生成树的边权重集合和截断距离算法来确定,如前面所述。创建一个空列表clusters,用于存储聚类簇。创建一个大小为n的数组point_labels,用于存储每个资产溯源数据点的标记。point_labels中的元素初始化为-1,表示未被访问过。使用循环遍历资产溯源数据列表data_list,循环变量i从0到n-1。
19、对于每个资产溯源数据点data_list[i],执行以下步骤:如果point_labels[i]不等于-1,表示该点已经被访问过,跳过该点,继续下一个点的处理。计算data_list[i]的eps邻域内的数据点数量,记为neighbor_count。如果neighbor_count大于等于min_samples,将data_list[i]标记为核心点,point_labels[i]设置为当前聚类簇的编号。如果data_list[i]是核心点,则创建一个新的聚类簇,将data_list[i]添加到该聚类簇中,并将该聚类簇添加到clusters列表中。如果data_list[i]是核心点,则对其eps邻域内的所有数据点进行扩展:对于eps邻域内的每个数据点data_list[j],如果point_labels[j]等于-1,则将其标记为当前聚类簇的编号,并将其添加到当前聚类簇中。如果point_labels[j]不等于-1,表示该点已经被分配到其他聚类簇中,跳过该点。如果data_list[i]不是核心点,则继续处理下一个数据点。遍历point_labels数组,对于值为-1的元素,表示对应的资产溯源数据点既不是核心点也不是边界点,将其标记为噪声点。噪声点不归入任何聚类簇,保留-1的标记。返回clusters列表,其中每个元素表示一个聚类簇,包含了属于该聚类簇的资产溯源数据点。返回point_labels数组,表示每个资产溯源数据点的聚类标记,噪声点的标记为-1。通过遍历资产溯源数据点,根据eps邻域内的数据点数量判断核心点,并对核心点进行扩展,将密度相连的数据点归入同一个聚类簇。对于不满足核心点条件的数据点,如果其eps邻域内存在核心点,则将其标记为边界点,并归入相应的聚类簇。既不是核心点也不是边界点的数据点被标记为噪声点,不归入任何聚类簇。最终得到的聚类结果包含了多个聚类簇和噪声点,实现了对资产溯源数据的有效聚合和划分。
20、进一步的,构建初始溯源图,包括:从资产交易链数据中提取地址信息,将每个唯一的地址表示为一个地址节点。对于每个地址节点,提取其属性特征,如交易金额、交易频率、交易时间等,构建节点特征向量。将地址节点和对应的节点特征向量作为图神经网络的输入节点。采用图注意力层(graph attention layer)对地址节点进行特征更新。通过注意力机制计算地址节点之间的注意力权重矩阵,权重矩阵表示节点之间的相关性和重要性。
21、注意力权重的计算公式如下:,其中,a表示注意力权重向量,用于计算节点之间的注意力权重。a的维度为(2*hidden_size,1),其中hidden_size表示节点特征向量的维度。表示节点i的权重矩阵,用于将节点i的特征向量映射到隐藏空间。的维度为(hidden_size,input_size),其中input_size表示节点特征向量的原始维度。表示节点j的权重矩阵,用于将节点j的特征向量映射到隐藏空间。的维度与相同。表示节点i的特征向量,表示节点i的原始特征表示。表示节点j的特征向量,表示节点j的原始特征表示。||表示拼接操作,将节点i和节点j映射后的特征向量拼接在一起,形成一个长度为2*hidden_size的向量。b表示偏置项,用于增加模型的灵活性和表达能力。b的维度为(2*hidden_size,1)。leaky relu:激活函数,用于引入非线性变换,提高模型的表达能力。leaky relu相比于relu函数,在负值部分具有一个小的负斜率,避免了“死亡relu”问题。softmax:归一化函数,用于将注意力权重归一化到[0,1]的范围内,使得所有权重之和为1。具体的,引入节点独立的权重矩阵和,替代原公式中共享的权重矩阵w。这样为不同的节点学习特定的特征变换,提高模型的表达能力和灵活性。添加偏置项b,增加模型的自由度,使得模型能够学习到更复杂的注意力权重分布。使用leaky relu激活函数替代原公式中的relu函数,避免“死亡relu”问题,提高模型的收敛性和稳定性。
22、根据注意力权重矩阵,对地址节点的特征进行加权求和,更新节点的特征表示。采用多头注意力机制(multi-head attention)对地址节点进行特征更新。使用多个独立的图注意力层并行计算地址节点的注意力权重矩阵,每个图注意力层使用不同的权重矩阵。将不同图注意力层的输出进行拼接,作为多头注意力的输出。
23、多头注意力的计算公式如下:,其中,各个参数的意义如下:表示第i个图注意力层的输出,表示使用第i个注意力头计算得到的节点特征表示。的维度为(num_nodes,hidden_size),其中num_nodes表示节点的数量,hidden_size表示隐藏层的维度。concat:拼接操作,将k个注意力头的输出拼接在一起,形成一个长度为k*hidden_size的向量。表示输出权重矩阵,用于将拼接后的多头注意力输出映射到最终的输出特征空间。的维度为(k*hidden_size,output_size),其中output_size表示最终输出特征的维度。表示输出偏置项,用于增加模型的灵活性和表达能力。的维度为(output_size,)。layer norm表示层归一化操作,用于对多头注意力的输出进行归一化,使其具有零均值和单位方差。layer norm加速模型的收敛速度,提高模型的稳定性和泛化能力。具体的,引入输出偏置项,增加模型的自由度,使得模型能够学习到更复杂的特征变换。在多头注意力的输出上应用层归一化操作layer norm,对输出进行归一化处理。层归一化加速模型的收敛速度,提高模型的稳定性和泛化能力。它通过将输出转换为零均值和单位方差的分布,使得不同层之间的输出分布更加一致,减少了内部协变量偏移的问题。通过拼接操作将多个注意力头的输出组合在一起,形成一个长度为k*hidden_size的向量。使用输出权重矩阵对拼接后的多头注意力输出进行线性变换,将其映射到最终的输出特征空间。这样增加模型的灵活性,允许模型学习到更加复杂和抽象的特征表示。
24、输出权重矩阵的具体表达式如下:<mstyle displaystyle="true" mathcolor="#000000"><msub><mi>w</mi><mi>o</mi></msub><mi>=</mi><mrow><mo>[</mo><mrow><msub><mi>w</mi><mn>1</mn></msub><mi>,</mi><msub><mi>w</mi><mn>2</mn></msub><mi>,.....,</mi><msub><mi>w</mi><mi>outputsize</mi></msub></mrow><mo>]</mo></mrow></mstyle>,其中,表示输出权重矩阵的第i列,即第i个输出特征对应的权重向量。的维度为(k*hidden_size,1)。k表示注意力头的数量。hidden_size表示每个注意力头的隐藏层维度。output_size表示最终输出特征的维度。输出权重矩阵看作是由output_size个列向量组成的矩阵,每个列向量对应一个输出特征。的作用是将拼接后的多头注意力输出(维度为k*hidden_size)映射到最终的输出特征空间(维度为output_size)。输出权重矩阵通常使用随机初始化的方式进行初始化,使用xavier初始化或kaiming初始化等方法。
25、根据多头注意力的输出,通过图池化层(graph pooling layer)对地址节点的特征表示进行池化操作。图池化层使用最大池化、平均池化或其他池化方式,将节点的特征进行聚合和压缩。通过图池化层得到地址节点的高层特征表示,减小特征维度并提取重要信息。根据地址节点的高层特征表示,通过全连接层(fully connected layer)将地址节点从高维特征空间映射到低维嵌入空间。
26、全连接层的计算公式如下: 其中,各个参数的意义如下:表示高层特征,即全连接层的输入特征。它是之前层的输出,如卷积层或注意力层的输出。的维度为(input_size,)。表示注意力权重,表示不同特征之间的重要性和相关性。的维度为(input_size,),与高层特征的维度相同。表示逐元素乘法操作,将高层特征和注意力权重进行逐元素相乘,得到加权后的特征表示。表示第一个权重矩阵,用于将加权后的特征表示映射到一个中间特征空间。的维度为(hidden_size,input_size),其中hidden_size表示中间特征空间的维度。表示第一个偏置项,用于增加模型的灵活性和表达能力。的维度为(hidden_size)。activation:激活函数,如relu或tanh,用于引入非线性变换,提高模型的表达能力。表示第二个权重矩阵,用于将注意力权重映射到一个中间特征空间。的维度为(hidden_size,input_size)。表示第二个偏置项,用于增加模型的灵活性和表达能力。的维度为(hidden_size)。具体的,引入注意力权重,通过逐元素乘法操作将其与高层特征进行融合,得到加权后的特征表示。这样根据不同特征的重要性和相关性,对高层特征进行自适应的调整和加权,突出关键信息,抑制噪声和冗余信息。使用两个独立的全连接层分别处理加权后的特征表示和注意力权重,得到两个中间特征表示。将两个中间特征表示相加,得到最终的嵌入表示。相加操作将两个中间特征表示进行融合,捕捉它们之间的互补信息,提高嵌入表示的质量和丰富性。在两个全连接层中分别引入偏置项和,增加模型的灵活性和表达能力,使得模型能够学习到更复杂的特征变换和映射关系。
27、通过全连接层得到地址节点的嵌入向量表示,嵌入向量捕捉了节点的语义信息和结构特征。根据地址节点的嵌入向量表示,通过计算节点嵌入向量之间的欧式距离,构建地址节点之间的边。欧式距离越小,表示两个地址节点在嵌入空间中越相似,边的权重越大。通过设置距离阈值,将距离小于阈值的节点对连接起来,形成初始溯源图的边。初始溯源图的节点为地址节点,边表示地址节点之间的相似性和关联性。采用区块链的智能合约对构建的初始溯源图进行数字签名和哈希运算。使用区块链的共识机制,如工作量证明(pow)或权益证明(pos),在区块链网络中对初始溯源图的签名和哈希值达成一致。将初始溯源图作为一个区块添加到区块链中,确保溯源图的不可篡改性和可追溯性。区块链的共识机制保证了初始溯源图的可信度和安全性,防止数据伪造和篡改。图神经网络通过注意力机制和多头注意力机制对地址节点进行特征更新和聚合,捕捉节点之间的关联性和重要性。嵌入向量表示将节点映射到低维空间,便于构建节点之间的边。
28、本说明书的另一个方面还提供一种基于区块链的资产处理溯源系统,用于执行本技术的一种基于区块链的资产处理溯源方法。
29、有益效果,相比于现有技术,本技术的优点在于:
30、采用深度学习模型对资产溯源数据进行特征提取,通过卷积神经网络提取局部特征,通过循环神经网络提取时序特征,并引入注意力机制对多尺度时序特征进行加权融合,提高了资产溯源数据的特征表示能力,增强了关键特征的判别性和鲁棒性。
31、采用基于关键特征相似度和语义相似度的聚类算法,对资产溯源数据进行资产交易链划分,通过计算关键特征向量之间的欧氏距离和语义向量之间的余弦相似度,构建融合相似度矩阵,利用最小生成树算法和密度聚类算法进行资产交易链的自适应划分,克服了传统方法对参数敏感、聚类结果不稳定的缺陷,提高了资产交易链划分的精度和可靠性。
32、引入图神经网络构建初始溯源图,将资产交易链数据映射为图结构数据,通过图注意力层和多头注意力机制,自适应地学习地址节点之间的拓扑结构关系和语义关联关系,捕获了溯源图中蕴含的高阶交互模式和长程依赖关系,挖掘了溯源图的深层特征表示。
33、融合知识图谱和地址标签库,对初始溯源图中的地址节点进行语义映射,将地址节点替换为对应的地址标签节点,引入了外部领域知识,赋予了溯源图以明确的语义描述和丰富的属性信息,提高了溯源图的可解释性和可读性。
34、采用深度嵌入聚类算法对地址标签节点进行聚类,通过图卷积神经网络提取地址标签节点的局部结构特征,通过图注意力机制获取地址标签节点之间的全局关联特征,并进行特征融合,得到地址标签节点的综合特征表示向量;利用图自编码器结构实现特征压缩和降维,在低维嵌入空间中应用k-means算法进行节点聚类,有效平衡了聚类的准确性和效率。
35、将资产交易链划分结果、初始溯源图、地址标签映射结果、资产流转溯源图等关键信息存储在区块链上,利用区块链的去中心化、防篡改、可追溯等特性,保证了资产处理溯源过程的透明性和数据安全性,实现了资产流转的全流程可视化追踪。
本文地址:https://www.jishuxx.com/zhuanli/20240822/281536.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。