一种基于医学fMRI数据的混合数据增强无监督域自适应分类方法
- 国知局
- 2024-08-30 14:34:10
本发明涉及功能核磁共振成像分类领域,尤其涉及一种基于医学fmri数据的混合数据增强无监督域自适应分类方法。
背景技术:
1、功能核磁共振成像(fmri)是一种用于测量人脑活动的非侵入性神经影像技术,能够帮助研究人员探索认知、感知、情绪和记忆等脑功能的工作机制。fmri数据提供了较高的空间分辨率,也包含了时间维度上的丰富信息。目前,基于静息态功能核磁共振成像(rs-fmri)和机器学习结合的算法模型在fmri数据的分类任务上取得了令人瞩目的成果。但是,由于采集设备和操作的异质性,公开数据集中来自不同医疗站点间的fmri数据往往存在明显的特征分布差异。这使得已经在大规模数据集上训练好的模型应用于新站点数据执行分类任务时会面临域偏移问题。
2、医学数据稀少、分布差异大是阻碍深度学习模型在跨站点实现医学数据分类的重要因素之一。为了解决这些问题,许多研究通过域适应的方法完成跨站点任务下的分类目标。zhang等人在2020年发表的“transport-based joint distribution alignment formulti-site autism spectrum disorder diagnosis using resting-state fmri”中公开了面对域适应任务时,设计了一种多站点多路并行的自适应深度学习框架,并基于最优传输算法在每对源域和目标域中同时进行联合分布对齐。wang等人在2020年发表的“unsupervised graph domain adaptation for neurodevelopmental disordersdiagnosis”中公开了在研究图数据的无监督域适应时,以渐进特征对齐的方式逐步可靠地对齐两个域的图表示,并使用无监督信息正则化器来有效学习图嵌入以增强特征对齐。由于不同站点数据的分布差异较大以及数据稀缺,仅依靠对齐与对抗策略并不能取得高效的预测结果。域间的数据分布差异是客观存在的,而特征对齐方法通常需要大量的源域数据来进行特征分布的调整和对齐。如果源域数据量不足或者源域和目标域之间存在较大的分布差异,特征对齐的效果可能会受到限制,并且可能会产生过拟合现象或边缘拟合现象。通过数据增强方式对原始数据进行扩充,生成更多样化的数据样本。这样可以增加域适应模型的训练数据量,从而提高模型的泛化能力和鲁棒性。此外,数据增强可以模拟不同域中的变化和差异,使得模型能够更好地适应目标域的特征分布。相比之下,单一的特征对齐会将跨域数据的特征分布拟合到源域的分布,但并没有学习到更有意义的分类信息,限制了模型对目标域的适应能力。
技术实现思路
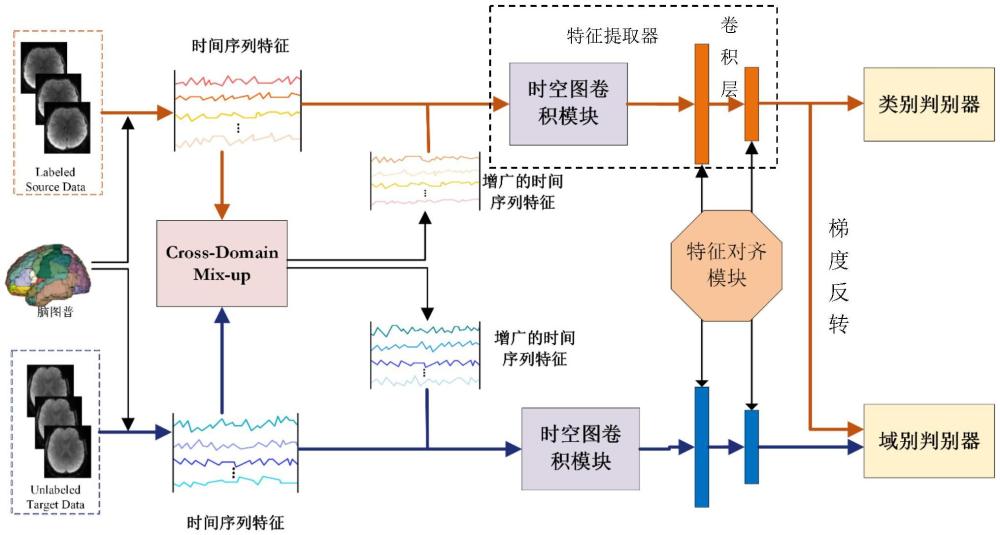
1、本发明针对由于不同站点数据的分布差异较大以及数据稀缺,仅依靠对齐与对抗策略并不能取得高效的预测结果的问题,提出一种基于医学fmri数据的混合数据增强无监督域自适应分类方法,所述方法包括:
2、s1:获取fmri数据中各个大脑区域中的平均时间序列;
3、s2:选取n个感兴趣区域roi,根据全部样本数据对每个roi的时序特征进行归一化处理;
4、s3:通过cross-domain mix-up生成新样本;
5、s4:根据原始fmri数据和生成新样本构建图数据;
6、s5:使用时空图卷积神经网络对图数据进行特征学习;
7、s6:将时空图卷积神经网络学习后的特征进行特征对齐和域对抗;
8、s7:根据类判别器对目标域样本做出分类预测。
9、进一步的,还提出一种优选方式,所述步骤s3包括:
10、λmxs+(1-λm)xt=xs-mix,yd=′source′,yc=yc(xs)
11、λmxt+(1-λm)xs=xt-mix,yd=′target′,yc=′none′
12、其中,xs为源域数据特征,xt为目标域数据特征,yd为样本的域别标签,yc为样本的类别标签;λm为比例系数;xs-mix为由源域数据特征主导的生成数据;xt-mix为由目标域数据特征主导的生成数据;source为源域,target为目标域。
13、进一步的,还提出一种优选方式,所述λm大于0.5。
14、进一步的,还提出一种优选方式,所述步骤s4包括:
15、将静息态功能性磁共振成像rs-fmri中获取的血液氧水平依赖性信号表示为无向时空图g=(x,v,e),其中,x为时序信号特征、v为顶点、e为边缘集合;v={vti|t=1,...,t;i=1...,n}表示第t个时间点的顶点集中的特定节点。
16、进一步的,还提出一种优选方式,所述步骤s5包括:
17、所述时空图卷积神经网络包含一个空间卷积核和一个时间卷积核;所述空间卷积核用于在空间维度上进行卷积操作,从图数据中提取出不同区域之间的关系;时间卷积核用于在时间维度上进行卷积操作,捕捉出fmri数据的时间特性;
18、在图卷积过程中,所有源域数据和目标域数据共享一个基于所有数据的计算得到的邻接矩阵,所述邻接矩阵用于定义邻居节点之间的关系,并在消息传递过程中指导特征的聚合。
19、进一步的,还提出一种优选方式,所述步骤s6包括:
20、将学习到的时空特征展平,将所述学习到的时空特征转换成一维向量;
21、使用n个一维卷积层神经网络学习一维向量中的高阶信息;
22、采用最大平均差异约束损失函数对齐每个卷积层中来自两个不同域的样本特征;
23、将特征输入至域判别器进行源域或目标域的判断。
24、进一步的,还提出一种优选方式,所述步骤s7包括:
25、将对齐后的特征输入到类判别器中预测目标域样本的类别;
26、使用分类任务的损失函数度量类判别器的预测结果与真实标签之间的差异,总体损失如下:
27、l=λ1lc+λ2ld+λ3lf
28、其中,λ1、λ2、λ3都是超参数,lc分类损失函数,ld域对抗损失函数,lf为特征对齐损失函数。
29、基于同一发明构思,本发明提出一种计算机设备,包括存储器和处理器,所述存储器中存储有计算机程序,当所述处理器运行所述存储器存储的计算机程序时,所述处理器执行如上述中任一项中所述的一种基于医学fmri数据的混合数据增强无监督域自适应分类方法。
30、基于同一发明构思,本发明还提出一种计算机可读存储介质,其特征在于,所述计算机可读存储介质用于储存计算机程序,所述计算机程序执行上述任一项所述的一种基于医学fmri数据的混合数据增强无监督域自适应分类方法。
31、本发明的有益之处在于:
32、本发明所提出的一种基于医学fmri数据的混合数据增强无监督域自适应分类方法,解决了医学fmri数据在不同的研究站点中可能存在分布差异,对分类模型性能产生负面影响的问题。本方法通过引入域自适应技术,能够在不同站点之间进行特征对齐和域对抗操作,减小不同站点数据的差异,从而提高模型的泛化能力。
33、由于医学fmri数据的采集成本较高,样本数量通常较少,这会使得建立强大的分类模型变得困难。本发明提出的方法通过采用混合数据增强技术,即cross-domainmix-up生成新样本,从而可以在有限的数据集上增加样本数量,缓解数据稀缺问题。
34、本发明所提出的一种基于医学fmri数据的混合数据增强无监督域自适应分类方法中,通过特征对齐和域对抗操作,可以减小不同站点数据之间的分布差异,提高模型的泛化能力。这对于基于医学fmri数据的分类任务非常重要,因为不同站点的数据可能具有不同的噪声、扫描参数或仪器差异等。通过cross-domain mix-up生成新样本,可以增加数据集的样本数量,缓解数据稀缺问题。这对于建立准确和鲁棒的分类模型非常有益,因为充足的样本数量可以帮助模型更好地学习数据的特征和结构。结合时空图卷积神经网络有效地处理具有时序和空间结构的医学fmri数据。通过使用图卷积神经网络对构建的图数据进行特征学习,可以更好地捕获大脑区域之间的关联性信息,并提高分类模型的性能。
35、本发明通过设计了一个新颖的无监督单源域自适应模型用于跨站点分类任务,并在公开数据集的实验中达到了最优性能。
36、本发明提出了cross-domain mix-up的方式对fmri进行数据增强,它能同时提供了类别伪标签和域别伪标签用于模型训练,根据混合比例给不同的样本提供了不同的类别标签和域别标签。
37、本发明通过共享邻接矩阵、特征对齐和域对抗的方式有效地提升了跨站点分析fmri数据的能力。
38、本发明使用与分类任务高度相关的脑区能进行试验从而显著提升了分类性能。
39、本发明应用于医学数据分类领域。
本文地址:https://www.jishuxx.com/zhuanli/20240830/282752.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表