基于PDF模糊查询的向量知识库构建方法及装置、设备、介质
- 国知局
- 2024-09-05 14:25:08
本技术涉及一种基于pdf模糊查询的向量知识库构建方法及装置、设备、介质,属于自然语言处理。
背景技术:
1、pdf文档在当今生活中扮演着重要的角色,被广泛应用于电子文档的交换、共享、存储和阅读,涵盖了商业、教育、科研、技术等各个领域,在应用中保证了信息的可靠性和准确性。
2、目前存在多种pdf文档处理工具,可以用于提取、解析和处理pdf文档中的文本信息,例如pypdf2、pdfplumber、ocrmypdf等。但发明人在实际操作中发现处理pdf文档时,会遇见文档中存在表格且表格方向并非正常阅读方向的问题,可能是横向排列或者其他非传统方向。这种情况导致了常规工具无法正确识别和解析表格内容,进而影响了文档的正确读取和处理。在读取的同时会出现文字颠倒、乱码等现象,使用者可能无法正确获取文档中的信息,导致工作效率降低或者出现错误。同时在读取表格时若表格存在合并单元格,则单元格内容无法完全读取,导致部分信息丢失或不完整。这会给用户带来困扰,降低了文档的可用性和可读性。不仅影响了文档处理工具的正常运行,也给使用者带来了不便和困扰。
3、这些问题严重影响了pdf文档的处理和使用体验,在使用工具的时候影响了用户对pdf文档的正常解读和使用,则丢失了pdf文档原有的稳定性等。
4、进一步的,在构建向量知识库的阶段需要正确解读pdf文档以便构建,若处理工具选择不当则无法构建正确的向量知识库。
技术实现思路
1、为解决上述技术问题,本技术的实施例分别提供了一种基于pdf模糊查询的向量知识库构建方法及装置、设备、介质,在面对pdf文档多样性时,针对现有技术存在的读取表格方向不正常、文字颠倒、乱码以及合并单元格内容不完整等问题,本技术旨在提供一种可靠的解决方案,使用户能够更有效地处理pdf文档,并提高处理的准确性和效率,在读取文档后正确的构建向量知识库。通过改进pdf文档的处理方法,本发明旨在提高用户对pdf文档的使用体验,进一步促进数字化文档的交流、共享和应用,满足用户对高效、便捷文档处理的需求。
2、本技术的其他特性和优点将通过下面的详细描述变得显然,或部分地通过本技术的实践而习得。
3、根据本技术实施例的一个方面,提供了一种基于pdf模糊查询的向量知识库构建方法,所述方法包括:
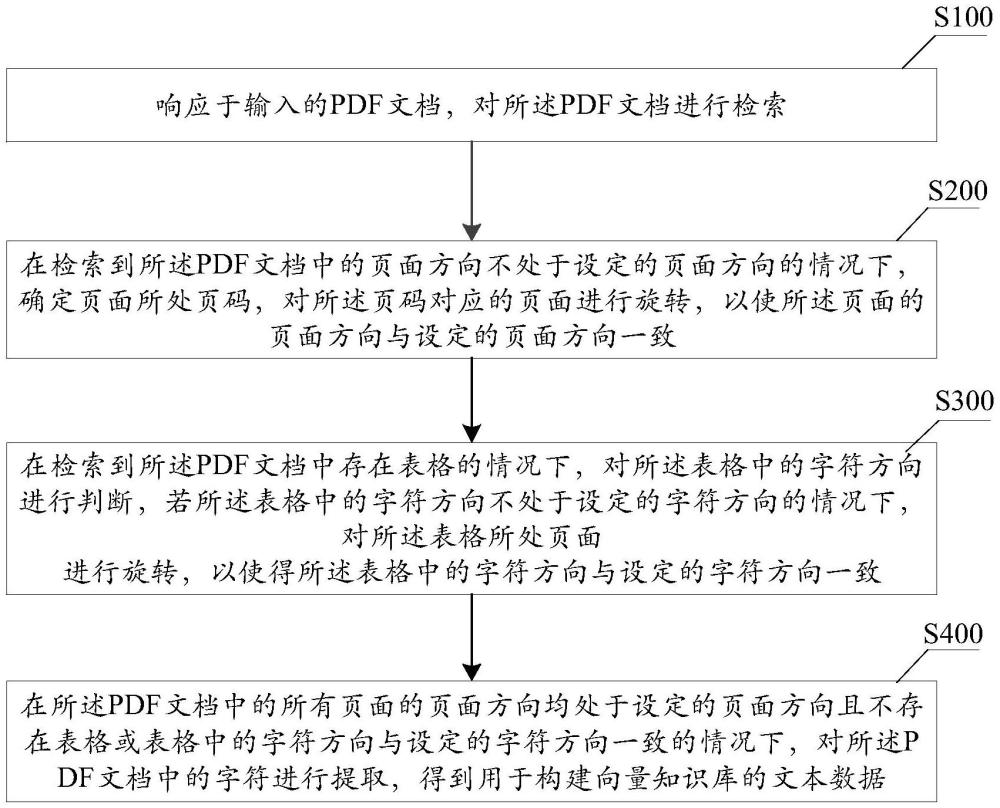
4、响应于输入的pdf文档,对所述pdf文档进行检索;
5、在检索到所述pdf文档中的页面方向不处于设定的页面方向的情况下,确定页面所处页码,对所述页码对应的页面进行旋转,以使所述页面的页面方向与设定的页面方向一致;
6、在检索到所述pdf文档中存在表格的情况下,对所述表格中的字符方向进行判断,若所述表格中的字符方向不处于设定的字符方向的情况下,对所述表格所处页面进行旋转,以使得所述表格中的字符方向与设定的字符方向一致;
7、在所述pdf文档中的所有页面的页面方向均处于设定的页面方向且不存在表格或表格中的字符方向与设定的字符方向一致的情况下,对所述pdf文档中的字符进行提取,得到用于构建向量知识库的文本数据。
8、进一步地,所述设定的页面方向为页面中的字符顺应从左往右的方向。
9、进一步地,所述设定的字符方向为表格中的字符顺应从左往右的方向。
10、进一步地,在得到用于构建向量知识库的文本数据之后,所述方法还包括:
11、将所述文本数据转化为txt文档格式数据,并进行保存。
12、进一步地,所述方法还包括:
13、将输入的pdf文档存储于第一文件夹,处理后的pdf文档存储于第二文件夹,txt文档格式数据存储于第三文件夹,其中处理后的pdf文档为经过页面旋转和表格旋转处理后的pdf文档。
14、进一步地,所述方法还包括:
15、响应于输入的pdf文档,在本地不存在第一文件夹的情况下,自动生成第一文件夹以存储输入的pdf文档;
16、在本地不存在第二文件夹的情况下,自动生成第二文件夹以存储处理后的pdf文档;
17、在本地不存在第三文件夹的情况下,自动生成第三文件夹以存储txt文档格式数据。
18、进一步地,在对所述表格所处页面进行旋转,以使得所述表格中的字符方向与设定的字符方向一致后,所述方法还包括:识别页面旋转后的表格。
19、根据本技术实施例的一个方面,提供了一种基于pdf模糊查询的向量知识库构建装置,包括:
20、文档获取单元,被配置为响应于输入的pdf文档,对所述pdf文档进行检索;
21、第一旋转单元,被配置为在检索到所述pdf文档中的页面方向不处于设定的页面方向的情况下,确定页面所处页码,对所述页码对应的页面进行旋转,以使所述页面的页面方向与设定的页面方向一致;
22、第二旋转单元,被配置为在检索到所述pdf文档中存在表格的情况下,对所述表格中的字符方向进行判断,若所述表格中的字符方向不处于设定的字符方向的情况下,对所述表格所处页面进行旋转,以使得所述表格中的字符方向与设定的字符方向一致;
23、数据转换单元,被配置为在所述pdf文档中的所有页面的页面方向均处于设定的页面方向且不存在表格或表格中的字符方向与设定的字符方向一致的情况下,对所述pdf文档中的字符进行提取,得到用于构建向量知识库的文本数据。
24、根据本技术实施例的一个方面,提供了一种电子设备,包括:控制器;存储器,用于存储一个或多个程序,当所述一个或多个程序被所述控制器执行时,使得所述控制器实现上所述的基于pdf模糊查询的向量知识库构建方法。
25、根据本技术实施例的一个方面,还提供了一种计算机可读存储介质,其上存储有计算机可读指令,当所述计算机可读指令被计算机的处理器执行时,使计算机执行上述的基于pdf模糊查询的向量知识库构建方法。
26、根据本技术实施例的一个方面,还提供了一种计算机程序产品或计算机程序,该计算机程序产品或计算机程序包括计算机指令,该计算机指令存储在计算机可读存储介质中。计算机设备的处理器从计算机可读存储介质读取该计算机指令,处理器执行该计算机指令,使得该计算机设备执行上述的基于pdf模糊查询的向量知识库构建方法。
27、在本技术的实施例所提供的技术方案中,至少具有以下优点:
28、1、文本提取准确性提高:通过对pdf文档进行合理的旋转处理和合并单元格的拆分操作,本技术提高了文本提取的准确性,降低了文字颠倒、乱码等现象的出现概率,使得提取的文本数据更加准确可靠。
29、2、处理效率提升:本技术通过代码自动化实现了pdf文档的处理和文字提取过程,大大提高了处理效率,减少了人工干预的时间和成本。
30、3、数据转换方便:将提取的文本数据转换为txt文档格式,方便后续的向量知识库构建。这样的数据格式具有普适性和可扩展性,为进一步的数据处理和应用提供了便利。
31、4、提升文档处理效率:本技术能够有效地提升pdf文档的处理效率,为企业、科研机构等提供了更加高效的文档处理方案,节省了大量的时间和人力成本。
32、5、促进信息共享和应用:通过提高pdf文档的处理准确性和可读性,本技术促进了数字化文档的交流、共享和应用,为信息共享和知识传播提供了便利条件,推动了数字化转型和信息化建设的发展。
33、6、技术创新和产业推动:本技术代表了在pdf文档处理领域的技术创新,具有较高的技术含量和应用价值,有望推动相关产业的发展,促进技术创新和产业升级。
34、应理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本技术。
本文地址:https://www.jishuxx.com/zhuanli/20240905/286352.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表