面向复杂场景的自适应增强现实多样化交互方法及系统与流程
- 国知局
- 2024-09-05 14:29:11
本发明涉及增强现实,更具体地说,涉及面向复杂场景的自适应增强现实多样化交互方法及系统。
背景技术:
1、增强现实技术通过将虚拟信息实时叠加到真实场景中,创造出一种虚实融合的新型交互体验。近年来,随着计算机视觉、人工智能等技术的飞速发展,增强现实已在工业制造、医疗教育、文旅娱乐等诸多领域崭露头角,成为数字化转型的重要推动力。
2、然而,现有的增强现实系统在面对复杂动态场景时,还存在诸多亟待解决的技术挑战。首先,复杂环境下的多模态感知能力有限。由于光照变化、视角遮挡等因素影响,单一传感器难以获得场景的完整信息。直接将不同传感器数据简单拼接,又易引入冗余和噪声。如何从多源异构数据中提取互补的有效信息,形成场景的全面理解,是一大难点。
3、其次,现有系统普遍缺乏对场景内容的深层语义理解能力。大多方法仅提取浅层特征,难以刻画事物间的内在联系,语义鸿沟限制了内容生成的质量。一些研究尝试引入深度学习,但在应对开放场景的多样性变化时,泛化能力有限。此外,现有方法生成的内容缺乏多样性,难以满足不同用户的个性化需求。
4、再者,用户与虚拟内容间缺乏智能、自然的交互。大多系统采用预定义的交互逻辑,无法主动理解用户意图。一些研究探索数据驱动的交互生成,但在复杂场景下鲁棒性不足。内容的生成与呈现缺乏整体优化,导致交互体验不连贯。同时,现有方法的渲染效率普遍不高,难以在移动设备上流畅运行,影响用户沉浸感。
5、具体到算法层面,目前学界对增强现实中的一些关键技术已有初步探索,但尚存在明显不足。例如,语义分割常用的全卷积网络如fcn、segnet等,虽然可以完成像素级标注,但在复杂场景中容易丢失小目标,对不常见类别的分割精度也有待提升。三维重建中的sfm、slam等方法虽能恢复场景结构,但对动态、非刚性物体的表现欠佳。
6、此外,现有的增强现实内容生成方法主要有基于图像的合成、三维模型渲染等。基于图像的合成方法如image inpainting gan,虽然可以根据上下文信息填充场景,但生成的内容往往缺乏三维立体感。三维模型渲染如mesh r-cnn结合深度学习与图形学,可以生成更真实的内容,但需要海量的三维数据作为先验,构建成本高。这些方法生成内容的形式较为单一,缺乏灵活的参数化调控。
7、交互方面,传统系统多采用基于规则的手工设计,通用性差。一些研究尝试数据驱动的交互合成,但在复杂场景中泛化能力有限,难以适应用户意图的动态变化。现有的视觉注意力机制如attention branch network、fpn等,可以引导系统关注显著区域,但对上下文信息的建模尚不充分,难以支撑内容的持续演化。同时,现有方法普遍侧重局部交互的优化,缺乏全局的长期规划。
8、鉴于上述技术限制,现有增强现实系统在面向复杂动态场景时,还难以提供持续智能、沉浸自然的交互体验。为了突破瓶颈,一方面需要在多模态感知、语义理解、内容生成、智能交互等关键技术上取得创新突破;另一方面需要针对不同功能模块间的协同增效进行系统层面的优化设计,构建端到端的技术方案。这正是本发明的创新动机所在。
技术实现思路
1、本发明正是针对上述技术问题,提出面向复杂场景的自适应增强现实多样化交互方法及系统,本发明充分吸收了前人研究成果,并立足复杂动态场景的应用痛点,提出了一套自适应、多样化的增强现实交互范式。在多模态感知融合、分层对抗学习、参数化内容生成、强化学习驱动等方面进行了系统创新,最终形成了从感知、理解、决策到呈现的一体化技术框架。这些创新有望推动增强现实在更广阔、更贴近真实世界的应用场景中发挥革命性作用。
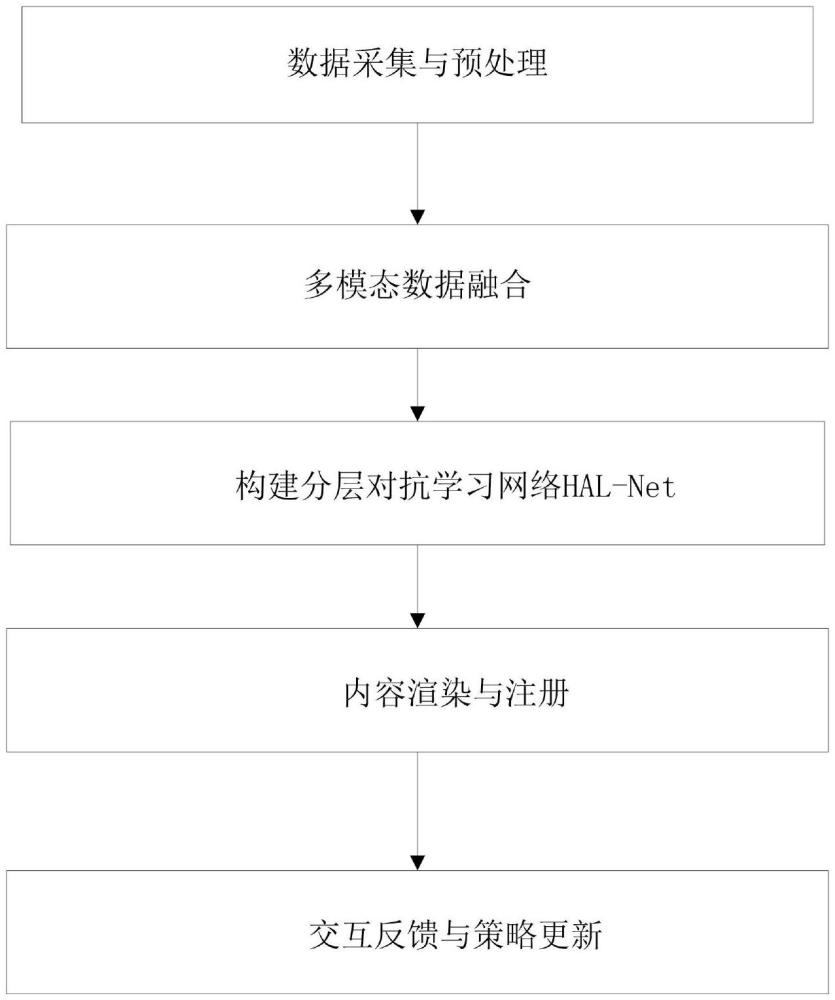
2、本发明提供面向复杂场景的自适应增强现实多样化交互方法,包括以下步骤:
3、步骤1:数据采集与预处理,使用深度相机采集复杂场景的rgb图像和深度图,用6-dof惯性传感器采集设备的位姿数据,对rgb图像进行去噪、校正和归一化处理,对深度图进行畸变校正、空洞填充和平滑滤波处理,将rgb图像、深度图和位姿数据以帧为单位同步打包;
4、步骤2:多模态数据融合,将rgb图像、深度图和位姿通过投影变换映射到公共坐标系下,得到对齐后的特征图谱;设计基于注意力机制的自适应权重融合方案,根据不同模态数据的质量和信息量自适应分配融合权重;
5、步骤3:构建分层对抗学习网络hal-net,包含对抗特征提取子网络、材质分类子网络、参数化内容生成子网络和交互驱动模型子网络,通过端到端的对抗训练提取鲁棒、判别、多样的特征表示;
6、步骤4:内容渲染与注册,将hal-net输出的内容属性参数实例化为三维虚拟内容模型,赋予材质、纹理和光照属性,利用视点跟踪算法和深度信息将虚拟内容与真实场景准确地配准,处理遮挡关系;
7、步骤5:交互反馈与策略更新,将用户对内容的语音、手势反馈编码为即时奖励,触发强化学习模型的参数更新,使内容生成策略能够自适应用户的交互意图。
8、具体地,步骤1中,深度相机为microsoft kinect,rgb图像分辨率为1920×1080,深度图分辨率为512×424;惯性传感器为mpu6050,采样频率为100hz。
9、具体地,步骤2中,基于注意力机制的自适应权重融合方案的数学描述为:将rgb图像it、深度图dt和位姿pt通过投影变换∏映射到公共坐标系下,得到对齐后的特征图谱ft=∏(it,dt,pt)。融合权重αk计算公式为:
10、其中,αk是第k个模态的融合权重k∈1,2,....,k,k为模态数;βk是通过卷积网络动态预测的权重系数,最终融合后的特征图谱f为:其中,⊙表示逐元素乘法。
11、具体地,步骤3中分层对抗学习网络hal-net的对抗特征提取子网络包含生成器g1和判别器d1,通过以下优化目标训练:
12、
13、其中,pdata是数据分布,pz是随机噪声分布;并引入teacher网络t1生成形变、遮挡样本网络g1最小化蒸馏损失:
14、具体地,步骤3中分层对抗学习网络hal-net的材质分类子网络包含生成器g1和判别器d2,通过以下优化目标训练:
15、
16、其中,c是材质类别标签,l是交叉熵损失m是与x同类但材质不同的样本,λ是平衡系数,earth mover距离用于度量特征分布的相似性。
17、具体地,步骤3中分层对抗学习网络hal-net的参数化内容生成子网络
18、包含生成器g1、g2和判别器d3通过以下优化目标联合训练:
19、
20、
21、
22、其中,为生成对抗损失,为循环一致性损失,为adain风格损失;y是真实图像,z是交互意图,s是风格图像,γ是adain参数。
23、具体地,步骤3中分层对抗学习网络hal-net的交互驱动模型子网络采用强化学习框架,将内容生成建模为马尔科夫决策过程mdp,其中,
24、状态当前生成内容、用户意图、场景上下文信息的编码向量;
25、动作内容属性参数,如形状、纹理、运动;
26、转移概率在状态s下采取动作a进入状态s′的概率;
27、奖励动作a在状态s下的即时奖励,用生成内容的真实性、多样性、匹配度指标度量;
28、折扣因子γ∈[0,1]:控制远期奖励的权重;
29、策略网络πθ(a|s)通过最大化累积奖励来优化,其中τ=(s1,a1,…,st,at)为一条轨迹,t为交互步数。
30、具体地,所述分层对抗学习网络hal-net的交互驱动模型子网络采用proximalpolicy optimization算法更新策略网络参数θ:
31、
32、其中,为优势函数的估计,β为kl散度惩罚系数。
33、具体地,步骤5中,用户通过语音、手势方式反馈对当前内容的评价,将其编码为即时奖励值,取值范围为[-1,1],正值表示正向反馈,负值表示负向反馈,绝对值大小表示反馈强度;当累积奖励值低于预设阈值时触发策略网络的更新,更新后的策略参数在下一交互步骤中生效。
34、一种面向复杂场景的自适应增强现实多样化交互系统,包括:采集模块、融合模块、学习模块、渲染模块和更新模块;所述采集模块,用于采集复杂场景的rgb图像、深度图和设备位姿数据,并进行预处理;所述融合模块,用于将异构数据映射到公共坐标系,通过注意力机制实现自适应权重融合;所述学习模块,用于构建分层对抗学习网络,提取鲁棒、判别、多样化的特征,并生成虚拟内容;所述渲染模块,用于将虚拟内容与真实场景配准,处理遮挡关系,呈现最终增强效果;所述更新模块,用于将用户交互反馈编码为即时奖励,触发策略网络参数更新,调整内容生成策略。
35、本发明具有如下有益效果:
36、1.多模态感知融合增强。采集模块获取了rgb图像、深度图和惯性数据等多源异构信息,融合模块通过投影变换实现空间对齐,并利用注意力机制自适应地平衡不同模态的贡献。这种深度融合方式充分挖掘了多模态数据的互补性,形成了对复杂场景更全面、更精准的感知能力,为后续内容生成奠定了良好基础。
37、2.分层对抗学习提升特征表示能力。学习模块采用了创新的分层对抗学习网络hal-net,设计了多个功能互补的子网络,通过端到端的联合优化,逐层提取场景的语义特征。对抗训练机制引入了多个判别器,从不同角度对生成器施加约束,teacher-student蒸馏、推土机距离等策略进一步增强了特征的判别性和鲁棒性。多层次、多侧重的特征表示为生成高质量、多样化的虚拟内容提供了坚实支撑。
38、3.参数化内容生成实现风格可控。内容生成子网络引入了adain风格迁移技术,用参考图像的风格信息调制内容特征,再经过参数化解码,即可实现同一内容在不同艺术风格下的灵活渲染。循环一致性损失保证了内容语义不被过度扭曲,由用户意图控制的风格信息则最大化了个性化表达空间。这种解耦内容和风格的生成范式,在很大程度上缓解了传统方法难以兼顾内容保真和风格多样的矛盾。
39、4.强化学习赋予内容交互智能。交互驱动子网络采用强化学习框架,通过即时奖励反馈不断优化策略网络,使之能够理解用户意图、记忆交互上下文,动态调整内容生成策略。在线策略更新使系统获得了随时间增长的适应性,可根据用户偏好的变化调整服务方式。这种主动适应机制很好地解决了静态内容难以满足交互需求的痛点,让内容可以通过与用户的持续互动变得更加智能。
40、5.高效渲染呈现沉浸体验。渲染模块利用实时头部跟踪和深度信息,将生成的虚拟内容与真实环境无缝融合,并处理物体间的遮挡关系,营造逼真的空间感。同时,采用基于物理的渲染管线和并行优化,保证了每秒30帧以上的渲染率,最大限度地避免画面卡顿和延迟,带来流畅、身临其境的沉浸体验。这种高性能、高质量的渲染使系统具备了真正应用的潜力。
41、6.软硬结合架构支撑算法落地。本系统采用了软硬一体化的架构设计,在算法创新的同时,还针对硬件平台如移动终端、ar眼镜等进行了适配和优化。模块间的数据交互、同步控制也充分考虑了硬件环境的特点。这种软硬协同使复杂算法具备了快速、高效执行的能力,让创新成果走出实验室,为真实场景应用铺平了道路。
42、7.系统模块间的协同增效。各功能模块分工明确、有机结合,形成了从感知、理解到交互、呈现的完整闭环。采集模块获取的多模态数据,为融合模块提供了丰富的信息源;融合模块智能平衡的特征表示,为学习模块准备了优质的训练材料;学习模块提炼的多层语义,让渲染模块的内容更显智能;渲染模块逼真呈现吸引用户参与,又反过来为更新模块积累了交互数据。正是得益于这种环环相扣、协同增效的流程,本系统的整体效果远胜于各模块效果的简单叠加。
43、总之,本发明巧妙地融合了计算机视觉、机器学习、人机交互、计算机图形学等多领域前沿技术,通过精心的顶层设计和反复的性能调优,最终呈现出一个高度智能化、个性化、沉浸化的复杂场景增强现实交互系统。相信这一技术成果必将在智慧城市、智能教育、虚拟博物馆等诸多热点领域得到广泛应用,为行业数字化变革注入新动能。。
本文地址:https://www.jishuxx.com/zhuanli/20240905/286696.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。