一种用于中文医疗嵌套命名的实体识别方法
- 国知局
- 2024-09-11 14:39:37
本发明属于自然语言处理命名实体识别领域,具体涉及一种用于中文医疗嵌套命名的实体识别方法。
背景技术:
1、随着人工智能技术的飞速发展和互联网数据的爆炸式增长,如何从海量的数据中迅速准确地提取关键的信息并挖掘其潜在的价值,是一项急需解决的任务。这些数据产生渠道众多,而大部分都是非结构化数据,给人们快速获取有效信息带来了较多困难。如何将这些非结构化数据转换为结构化数据,以进行高效利用,是当前亟需解决的问题。数据的丰富带来了对强有力的数据分析工具的需求,人们迫切需要一些自动化工具帮助进行海量信息处理,并且希望能够提供更高层次的数据分析功能,从而更好地对决策或科研工作提供支持,让计算机帮助用户分析数据、理解数据,从大量数据中提取知识模式,进而帮助用户基于丰富的数据作出一系列决策。
2、医疗行业也不例外,其中医疗命名实体识别(medical named entityrecognition,mner)是医学关系提取、医疗知识图谱构建等各项任务的基础,旨在从海量的非结构化医疗数据中识别有价值的医学信息并将其归类到预先定义好的类别,如疾病、药物、症状、临床表现等,是医疗文本数据挖掘的关键任务。医疗命名实体识别相较于其他任务往往更具挑战性,因为医疗实体往往来源于医学教材、医学百科、临床路径、病历、医学期刊、检验报告等,但是这些医学文本中蕴含了大量的专业知识和丰富的医学术语、而且还存在缩写、嵌套等不规范的表达,这就使得一般的命名实体识别模型不能直接用于处理医疗文本的实体识别。另外,相比于其他语言的命名实体识别任务,中文命名实体识别的难度更大,主要是中文文本中字符之间没有空格等分隔符,实体边界很难确定。
3、对医疗命名实体识别进行分析中常采用机器学习的方法,这种方法通常使用大量的标注数据来训练模型,然后使用该模型来识别新的文本中的实体。但是机器学习算法的性能很大程度上取决于训练数据的质量和数量,如果数据存在噪声、不平衡或缺失等问题,可能会影响模型的性能。相比于传统的实体识别方法,深度学习方法一般拥有强大的特征学习能力、泛化能力,适用于大规模数据处理,也可以处理复杂问题。不过深度学习模型需要大量的标注数据来训练,数据需求量大,这在实际应用中会因为标注数据需要耗费大量的人力和时间。
技术实现思路
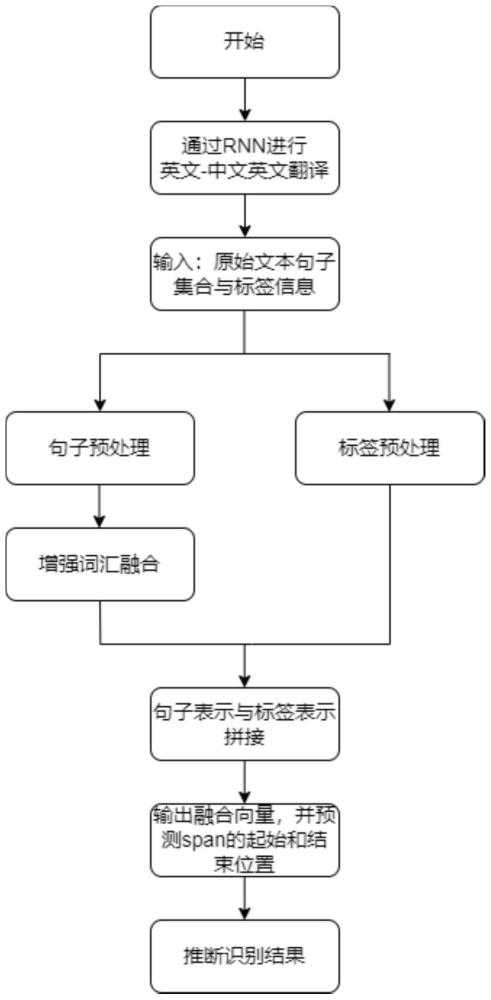
1、为解决以上现有技术存在的问题,本发明提出了一种用于中文医疗嵌套命名的实体识别方法,该方法包括:获取公开数据集,对公开数据集中的数据进行预处理;采用循环神经网络rnn对预处理后的数据进行处理,得到英文-中文翻译数据;获取原始文本句子集合,构建类别标签信息;将原始文本句子集合中的句子和类别标签信息分别输入到bert的编码器中,得到标签信息向量表示和句子向量表示;将英文-中文翻译数据输入到bert模型中,得到增强的词汇表;分别对句子向量表示和标签信息向量表示进行预处理;根据增强的词汇表对预处理后的句子向量表示进行词汇增强,得到增强后的句子向量表示;将增强后的句子向量表示与预处理后的标签信息向量表示进行拼接融合,将融合后的向量表示输入到实体识别模型中,得到实体的识别结果。
2、本发明的有益效果:
3、本发明通过循环神经网络rnn对数据进行翻译,得到英文-中文翻译数据,通过英文-中文翻译数据对原始文本向量进行词汇增强处理;将增强后的文本向量与标签信息向量进行融合,并输入到实体识别模型中进行识别,从而提高了实体识别的准确率。本发明通过传统的机器翻译模型rnn把大量的英文命名实体数据翻译成中文,并且利用这些翻译后的中文数据来增强中文命名实体识别模型;然后将bert和词汇信息的上下文表示直接集成到神经序列标注模型中,并且结合qa查询字段,引入来自不同类别的知识,以解决嵌套实体识别问题。
技术特征:1.一种用于中文医疗嵌套命名的实体识别方法,其特征在于,包括:获取公开数据集,对公开数据集中的数据进行预处理;采用循环神经网络rnn对预处理后的数据进行处理,得到英文-中文翻译数据;获取原始文本句子集合,构建类别标签信息;将原始文本句子集合中的句子和类别标签信息分别输入到bert的编码器中,得到标签信息向量表示和句子向量表示;将英文-中文翻译数据输入到bert模型中,得到增强的词汇表;分别对句子向量表示和标签信息向量表示进行预处理;根据增强的词汇表对预处理后的句子向量表示进行词汇增强,得到增强后的句子向量表示;将增强后的句子向量表示与预处理后的标签信息向量表示进行拼接融合,将融合后的向量表示输入到实体识别模型中,得到实体的识别结果。
2.根据权利要求1所述的一种用于中文医疗嵌套命名的实体识别方法,其特征在于,对公开数据集中的数据进行预处理包括去除重复句子、处理噪声数据以及标准化文本。
3.根据权利要求1所述的一种用于中文医疗嵌套命名的实体识别方法,其特征在于,采用循环神经网络rnn对预处理后的数据进行处理包括:将预处理的文本数据转换成词嵌入向量表示;将英文句子输入到编码器中,得到语义向量;将每个时间步的输出作为下一个时间步的输入,在编码器的最后一个时间步使用其隐藏状态作为整个输入序列的语义表示,使用rnn解码器对目标语言序列进行解码,生成预测序列;使用交叉熵损失函数来衡量预测序列与目标序列之间的差异,并选择adam优化器来最小化损失函数,更新模型参数。
4.根据权利要求1所述的一种用于中文医疗嵌套命名的实体识别方法,其特征在于,类别标签信息包括疾病、临床表现、药物、医疗设备、医疗程序、身体、医学检验项目、微生物类以及科室九大类别。
5.根据权利要求1所述的一种用于中文医疗嵌套命名的实体识别方法,其特征在于,对句子向量表示和标签信息向量表示进行预处理包括:
6.根据权利要求1所述的一种用于中文医疗嵌套命名的实体识别方法,其特征在于,根据增强的词汇表对预处理后的句子向量表示进行词汇增强包括:采用字符编码层将句子中的每个中文字符转换为一个向量;获取词汇表,构建softlexicon特征,根据softlexicon特征构建词典g;将输入的句子和词典g匹配,得到每个字符匹配上的对应单词类别标签,并对对应类别标签所对应的单词进行集合,其中类别标签包括开始、中间、结尾以及单字四个类别;判断集合是否为空,如果集合为空,则用“none”表示;否则将四个集合的表示和字嵌入拼接,然后对序列进行建模,即将词典信息加入到bert模型中,使得句子中的单词学习词典特征,得到词汇增强后的句子向量表示。
7.根据权利要求1所述的一种用于中文医疗嵌套命名的实体识别方法,其特征在于,将增强后的句子向量表示与标签信息向量表示进行拼接融合包括:采用注意力机制模块对增强后的句子向量表示和标签信息向量表示进行融合。
8.根据权利要求1所述的一种用于中文医疗嵌套命名的实体识别方法,其特征在于,将融合后的向量表示输入到实体识别模型中进行处理包括:将融合后的文本表达输入到tanh激活函数中,得到非线表示结果;将非线表示结果输入到一个全连接层中,以得到每个文本token的分数以及每个标签类别的分数;根据每个文本token的分数和每个标签类别的分数判断该token是否是实体的一部分以及每个token属于每个标签类别的概率;根据判断结果采用softmax函数来预测span的位置token。
技术总结本发明属于命名实体识别领域,具体涉及一种用于中文医疗嵌套命名的实体识别方法,包括:获取公开数据集,对公开数据集进行预处理;采用循环神经网络RNN对预处理后的数据进行处理,得到翻译数据;获取原始文本句子集合,构建类别标签信息;将句子和类别标签信息分别输入到编码器中,得到标签信息向量表示和句子向量表示;将翻译数据输入到Bert模型中,得到增强的词汇表;分别对句子向量表示和标签信息向量表示进行预处理;对预处理后的句子向量表示进行词汇增强;将增强后的句子向量表示与标签信息向量表示进行拼接融合,将融合后的向量表示输入到实体识别模型中,得到实体的识别结果;本发明引入不同类别的知识,解决了嵌套实体识别问题。技术研发人员:张清华,袁艺菡,罗南方受保护的技术使用者:重庆邮电大学技术研发日:技术公布日:2024/9/9本文地址:https://www.jishuxx.com/zhuanli/20240911/291737.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表