一种基于智能语音分析生成人物性格画像的方法及装置与流程
- 国知局
- 2024-09-11 14:46:35
本发明涉及语音分析,并且更具体地,涉及一种基于智能语音分析生成人物性格画像的方法及装置。
背景技术:
1、现如今,客户中心包含大量客户信息和客户资料,如何从海量的数据中准确查找对应的客户成为棘手的问题,因此可以将海量用户信息进行处理,生成生动的用户画像,但是如何将一个生硬的客户资料,形成一个比较生动的客户人物性格画像,使对接的业务人员在与客户沟通中能轻松把握客户性格与喜好,成为亟待解决的技术问题。
技术实现思路
1、针对现有技术的不足,本发明提供一种基于智能语音分析生成人物性格画像的方法及装置。
2、根据本发明的一个方面,提供了一种基于智能语音分析生成人物性格画像的方法,包括:
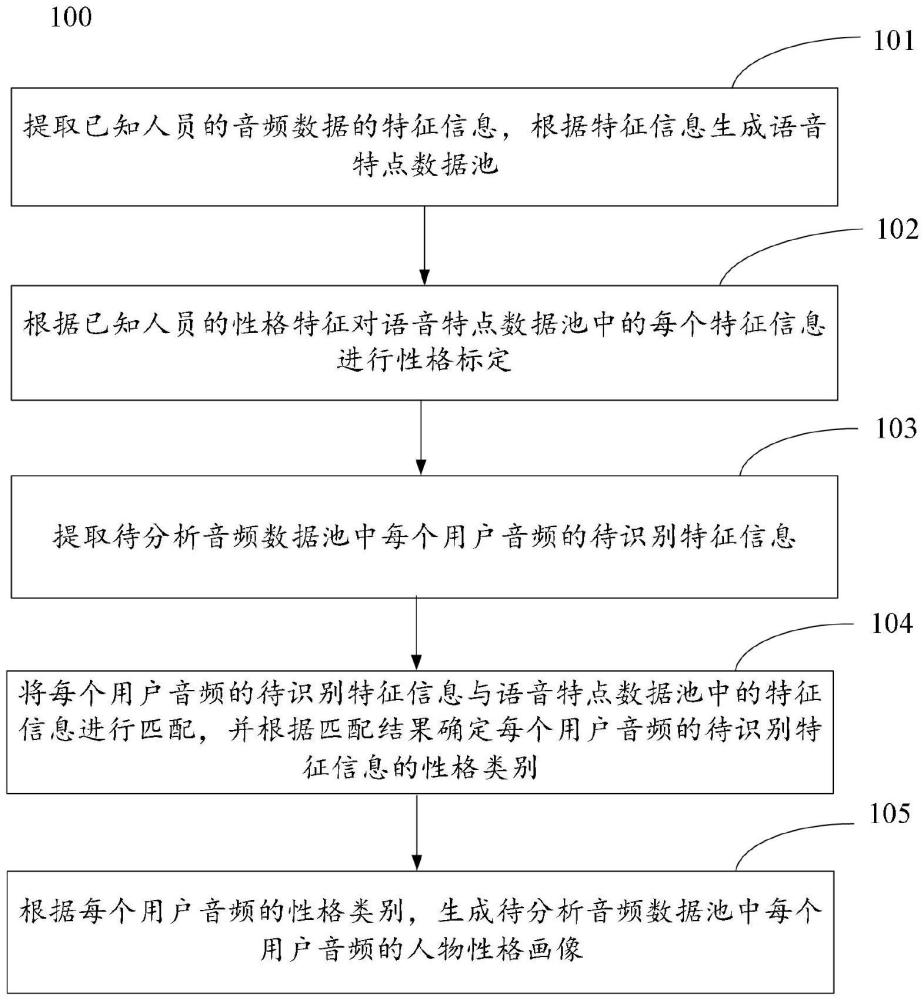
3、提取已知人员的音频数据的特征信息,根据特征信息生成语音特点数据池;
4、根据已知人员的性格特征对语音特点数据池中的每个特征信息进行性格标定;
5、提取待分析音频数据池中每个用户音频的待识别特征信息;
6、将每个用户音频的待识别特征信息与语音特点数据池中的特征信息进行匹配,并根据匹配结果确定每个用户音频的待识别特征信息的性格类别;
7、根据每个用户音频的性格类别,生成待分析音频数据池中每个用户音频的人物性格画像。
8、可选地,提取已知人员的音频数据的特征信息,包括:
9、将已知人员的音频数据转换为音频信号;
10、利用盲源分离法将音频信号进行人声和背景声音分离,获取音频数据中的人声;
11、提取人声中的特征信息,其中特征信息包括:音调特征、音色特征、语速特征以及语气特征。
12、可选地,提取人声中的特征信息,包括:
13、利用梅尔谱方法从人声中提取音色特征;
14、根据人声中的频率高低,确定音调特征;
15、根据人声中的频率速度,确定语速特征;
16、提取人声中的感情色彩词,确定语气特征。
17、可选地,利用梅尔谱方法从人声中提取音色,包括:
18、计算人声的梅尔频谱;
19、根据梅尔频谱提取音色特征;
20、利用htm模型计算梅尔频谱的htm特征,获取音色特征的谐波结构以及时域调制信息。
21、可选地,利用htm模型计算梅尔频谱htm特征,获取音色特征的谐波结构以及时域调制信息,包括:
22、利用htm模型获取梅尔频谱每个输入特征的激活状态;
23、根据每个输入特征的激活状态,计算每个输入特征的活跃度分数;
24、对所有输入特征的活跃度分数进行降序排列,并根据预设阈值,选取htm特征;
25、根据预设时间窗口内的每个细胞连接的输入特征的活跃度分数,计算htm模型中每个细胞的总输入信号值;
26、将总输入信号值大于预设阈值的该细胞进行激活;
27、将预设时间窗口内活跃度分数最高的细胞设置为活跃状态;
28、根据激活状态以及活跃状态的细胞,确定梅尔频谱的每个预设时间窗口内的htm特征,获取音色特征的谐波结构以及时域调制信息。
29、可选地,其中激活状态的计算公式为:
30、p(t)=sigmoid(sum(w*x))
31、其中,p(t)表示激活输入特征的概率,即激活状态,w表示连接权重,x表示输入特征的输入信号值,sigmoid函数将输入信号值映射到0和1之间;
32、活跃度分数的计算公式为:
33、a(t)=p(t)-k*avg(p)
34、其中a(t)表示输入特征的活跃度分数,k表示一个常数,avg(p)表示所有输入特征的激活概率的均值;
35、细胞的总输入信号值的计算公式为:
36、input(t)=sum(a(t)*w)
37、其中input(t)表示细胞的输入信号值,a(t)表示连接的输入特征的活跃度得分,w表示连接权重。
38、可选地,将每个用户音频的待识别特征信息与语音特点数据池中的特征信息进行匹配,并根据匹配结果确定每个用户音频的待识别特征信息的性格类别,包括:
39、计算每个用户音频的待识别特征信息与语音特点数据池中所有特征信息的相似度;
40、选取相似度最高的特征信息作为待识别特征信息的匹配结果;
41、根据匹配结果对应的特征信息标定的性格数据,确定每个用户音频的待识别特征信息的性格类别。
42、根据本发明的另一个方面,提供了一种基于智能语音分析生成人物性格画像的装置,包括:
43、第一提取模块,用于提取已知人员的音频数据的特征信息,根据特征信息生成语音特点数据池;
44、标定模块,用于根据已知人员的性格特征对语音特点数据池中的每个特征信息进行性格标定;
45、第二提取模块,用于提取待分析音频数据池中每个用户音频的待识别特征信息;
46、匹配模块,用于将每个用户音频的待识别特征信息与语音特点数据池中的特征信息进行匹配,并根据匹配结果确定每个用户音频的待识别特征信息的性格类别;
47、生成模块,用于根据每个用户音频的性格类别,生成待分析音频数据池中每个用户音频的人物性格画像。
48、根据本发明的又一个方面,提供了一种计算机可读存储介质,所述存储介质存储有计算机程序,所述计算机程序用于执行本发明上述任一方面所述的方法。
49、根据本发明的又一个方面,提供了一种电子设备,所述电子设备包括:处理器;用于存储所述处理器可执行指令的存储器;所述处理器,用于从所述存储器中读取所述可执行指令,并执行所述指令以实现本发明上述任一方面所述的方法。
50、从而,本申请通过智能语音分析生成语音特点数据池,在通过对客户的语音分析匹配对应性格类别,生成人物性格画像,轻松的完成了上万客户的人物性格画像,销售及业务人员在与客户对话中,实现轻松把握对方人物性格的技术效果。
技术特征:1.一种基于智能语音分析生成人物性格画像的方法,其特征在于,包括:
2.根据权利要求1所述的方法,其特征在于,提取已知人员的音频数据的特征信息,包括:
3.根据权利要求2所述的方法,其特征在于,提取人声中的所述特征信息,包括:
4.根据权利要求3所述的方法,其特征在于,利用梅尔谱方法从所述人声中提取所述音色,包括:
5.根据权利要求4所述的方法,其特征在于,利用htm模型计算所述梅尔频谱htm特征,获取所述音色特征的谐波结构以及时域调制信息,包括:
6.根据权利要求5所述的方法,其特征在于,其中所述激活状态的计算公式为:
7.根据权利要求1所述的方法,其特征在于,将每个用户音频的所述待识别特征信息与所述语音特点数据池中的所述特征信息进行匹配,并根据匹配结果确定每个用户音频的所述待识别特征信息的性格类别,包括:
8.一种基于智能语音分析生成人物性格画像的装置,其特征在于,包括:
9.一种计算机可读存储介质,其特征在于,所述存储介质存储有计算机程序,所述计算机程序用于执行上述权利要求1-7任一所述的方法。
10.一种电子设备,其特征在于,所述电子设备包括:
技术总结本发明公开了一种基于智能语音分析生成人物性格画像的方法及装置。其中,方法包括:提取已知人员的音频数据的特征信息,根据特征信息生成语音特点数据池;根据已知人员的性格特征对语音特点数据池中的每个特征信息进行性格标定;提取待分析音频数据池中每个用户音频的待识别特征信息;将每个用户音频的待识别特征信息与语音特点数据池中的特征信息进行匹配,并根据匹配结果确定每个用户音频的待识别特征信息的性格类别;根据每个用户音频的性格类别,生成待分析音频数据池中每个用户音频的人物性格画像。技术研发人员:刘琨玥,王浩,薛富恩受保护的技术使用者:北京安锐卓越信息技术股份有限公司技术研发日:技术公布日:2024/9/9本文地址:https://www.jishuxx.com/zhuanli/20240911/292109.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表