一种多模态认知信息与知识库动态整合方法及系统
- 国知局
- 2024-09-14 14:30:00
本发明涉及知识库动态整合,具体涉及一种多模态认知信息与知识库动态整合方法及系统。
背景技术:
1、认知实体链接(cognitive entity linking,简称cel)涉及将自然语言文本中的提及实体链接到知识库中的相应实体。这些实体可以是现实世界中的个人、地点、组织,或者是知识库内的特定实体。人类认知可以通过各种模态的信息载体来表达,例如文本或图像。在自然语言和结构化知识之间建立联系有助于人类认知和知识库的统一,使计算机更好地理解人类社会。具体而言,认知实体链接有助于更深入地理解文本的语义。通过将认知中的实体与知识库中的实体进行链接,系统可以获取有关这些实体的额外信息,提升对文本含义的理解。除了促进人类认知的统一,认知实体链接还有助于丰富知识库中的信息。通过实体链接,可以向知识库添加新的关系和属性,从而增强其完整性和准确性。近年来,认知实体链接任务在研究人员中引起了越来越多的关注。
2、然而,现有方法面临两个主要挑战:(a)研究人员没有充分考虑数据集中的模糊实体表示可能不能有效地代表知识库中的实体。通常,文本描述被用作知识库中实体的表示,如果计算得到的特征被视为类似于实体表示,那么实体链接任务就被视为完成。然而,在这个过程中,由于模糊实体表示与知识库实体的语义之间存在不一致,即使特征学习得很好,链接过程也可能失败。现有方法过于专注于增强特征学习方面,忽视了实体表示中的模糊性。(b)现有工作对图像的理解仍然存在有限。作为文本的关键补充源,图像信息值得更多关注。像ghmfc和mmel这样的方法通过对图像进行编码来增强图像信息与实体表示之间的链接能力。然而,图像信息对于识别实体身份的影响有限。一幅相同的图像,经过图像编码器和大模型提取的特征各不相同,但由于对图像的综合理解不足,它难以识别身份信息。
3、认知实体链接在很大程度上影响并促进了人类对信息的深刻理解和认知。认知实体链接作为统一人类认知与结构化知识存储库的重要手段:1. 语义一致性的保证:认知实体链接通过将认知中提及的实体与知识库对齐,确保了语义一致性。它有助于消除歧义,确保在上下文变化的情况下对特定实体的解释保持清晰。2. 认知信息的增强: 认知实体链接为个体提供了更丰富、更深刻的认知体验。通过将实体与背景知识关联,个体可以全面地理解实体的含义,从而提升他们对信息的认知意识。3. 集成知识获取: 这有助于打破信息孤岛,使人们能够轻松跨越不同领域、文本和知识源获取信息,促进认知水平的整体提升。能够跨越不同领域、文本和知识来源获取信息,促进认知水平的全面提高。
4、现有的实体链接数据集及其实体表示方法包括:1. wikimel 和 richpedia使用来自wikidata的简洁属性,这种表示缺乏对实体的代表性,因为许多实体共享相似的属性。容易将准确的认知错误地链接到错误的实体上。2. weibo 使用来自微博的个体,使用用户撰写的个人简介作为实体表示。这些个人简介依赖于用户生成的内容,可能包含偏见或错误,并且不能准确反映广大公众对实体的理解。3. wikidiverse 使用从维基百科收集的图像作为实体表示。然而,由于角度和时间等因素,图像可能偏离一个人的真实外貌,缺乏实时准确性。4. wikiperson 类似于wikimel,使用个体的属性作为代表,但以更简化的方式,但是属性不足以代表个体。总的来说,现有的认知实体链接方法存在一个问题,即实体表示未能有效地代表实体。更重要的是,这些表示是手动从维基百科或其他知识库中收集的,只能代表实体在特定时间点的状态。随着时间和事件的推移,人们对实体的理解也在变化。在这种情况下,刚性且不够灵活的实体表示可能导致错误。此外,当提及的实体不在数据集中时,就没有相应的实体表示,这可能导致实体链接中的潜在问题。
技术实现思路
1、本发明要解决的技术问题:针对现有技术的上述问题,提供一种多模态认知信息与知识库动态整合方法及系统,本发明旨在实现对多模态认知实体信息的动态性收集,将知识库中的实体与现实世界的信息进行动态化的整合和链接。
2、为了解决上述技术问题,本发明采用的技术方案为:
3、一种多模态认知信息与知识库动态整合方法,包括下述步骤:
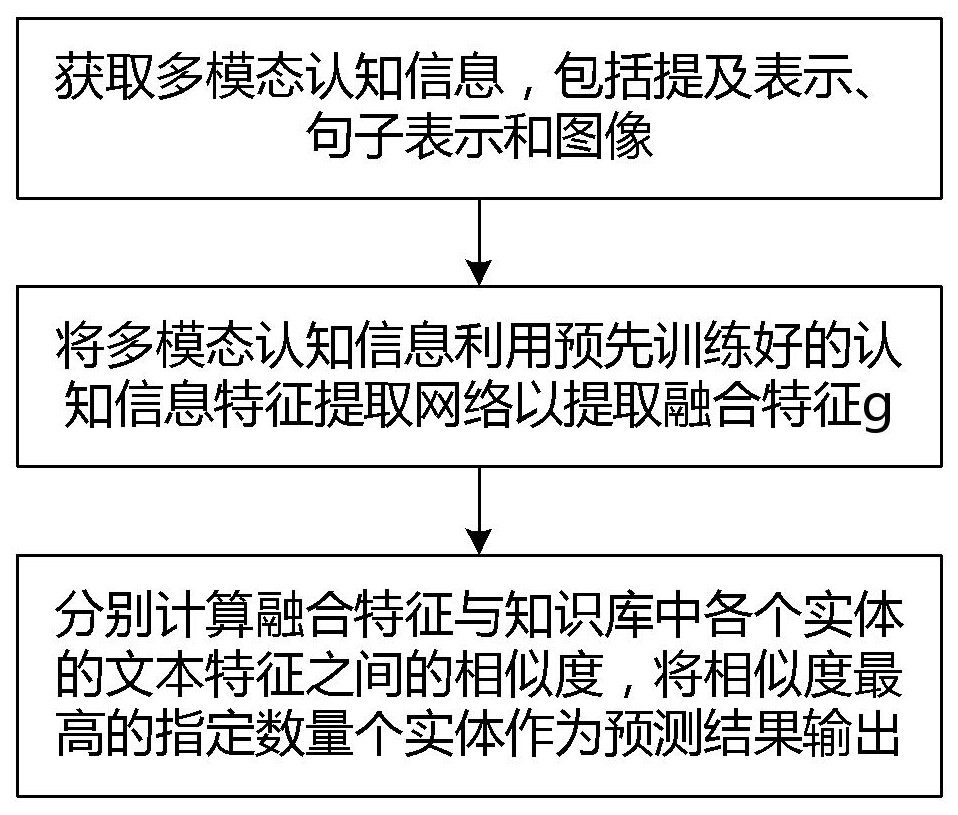
4、s101,获取多模态认知信息,包括提及表示、句子表示和图像;
5、s102,将多模态认知信息利用预先训练好的动态集成多模式认知信息提取网络dimc以提取融合特征g,包括:将提及表示、句子表示拼接后输入文本编码器,再经过多头注意力提取得到文本特征;将图像输入图像编码器,再经过多头注意力提取得到图像特征,同时将图像输入用于从图像中提取信息的专家模型提取信息后输入文本编码器得到专家特征;然后将文本特征、图像特征以及专家特征融合得到融合特征;
6、s103,分别计算融合特征与知识库中各个实体的文本特征之间的相似度,所述知识库中各个实体的文本特征为知识库中各个实体输入大语言模型得到的输出文本通过文本编码器编码得到,将相似度最高的指定数量个实体作为预测结果输出。
7、可选地,步骤s102中将提及表示、句子表示拼接后输入文本编码器时,将提及表示、句子表示拼接的方式为将提及表示的开始位置添加开始标记“[cls]”、结束位置添加结束标记“[sep]”后再与句子表示拼接。
8、可选地,步骤s102中经过多头注意力提取得到文本特征的函数表达式为:
9、,
10、上式中,softmax为softmax激活函数,、和为随机初始化的投影矩阵,表示专家特征,为文本编码器输出的特征,为文本编码器输出的特征和特征的隐藏大小。
11、可选地,步骤s102中经过多头注意力提取得到图像特征的函数表达式为:
12、,
13、上式中,softmax为softmax激活函数,、和为随机初始化的投影矩阵,表示专家特征,为图像编码器输出的特征,为文本编码器输出的特征和特征的隐藏大小。
14、可选地,步骤s102中将图像输入用于从图像中提取信息的专家模型提取信息后输入文本编码器得到专家特征包括:提取图像的描述,使用用于询问实体是谁或什么的提示词向预设的大语言模型查询获取图像的详细信息,将图像的描述和详细信息结合开始标记“[cls]”、结束标记“[sep]”组合为专家信息,将专家信息输入文本编码器得到专家特征。
15、可选地,步骤s102中将文本特征、图像特征以及专家特征融合得到融合特征的函数表达式为:
16、,
17、上式中,表示融合特征,表示图像特征,表示专家特征,表示文本特征。
18、可选地,步骤s102中的动态集成多模式认知信息提取网络dimc在训练时采用的损失函数的函数表达式为:
19、,
20、上式中,表示损失函数,为训练样本的数量,为和的相似度,为和的相似度,为第个样本的融合特征,为第个样本在知识库中对应实体的文本特征的正样本表示,为第个样本在知识库中对应实体的文本特征的负样本表示,为负样本数量,为自然常数。
21、此外,本发明还提供一种多模态认知信息与知识库动态整合系统,包括相互连接的微处理器和存储器,所述微处理器被编程或配置以执行所述多模态认知信息与知识库动态整合方法。
22、此外,本发明还提供一种计算机可读存储介质,该计算机可读存储介质中存储有计算机程序/指令,该算机程序/指令被编程或配置以通过处理器执行所述多模态认知信息与知识库动态整合方法。
23、此外,本发明还提供一种计算机程序产品,包括计算机程序/指令,该算机程序/指令被编程或配置以通过处理器执行所述多模态认知信息与知识库动态整合方法。
24、和现有技术相比,本发明主要具有下述优点:
25、1、为了解决现有模型信息利用不足的问题,本发明包括将多模态认知信息利用预先训练好的动态集成多模式认知信息提取网络dimc以提取融合特征g,包括:将提及表示、句子表示拼接后输入文本编码器,再经过多头注意力提取得到文本特征;将图像输入图像编码器,再经过多头注意力提取得到图像特征,同时将图像输入用于从图像中提取信息的专家模型提取信息后输入文本编码器得到专家特征;然后将文本特征、图像特征以及专家特征融合得到融合特征,通过上述方法实现了一种动态集成多模式认知信息(dimc)方法,利用大型语言模型对图像的理解能力设计提示从图像中提取信息,例如获取图像标题或查询图像中个体的身份,改善了从图像中提取信息的能力,克服了现有局限性,有助于更深入地理解人类认知和知识库,推动自然语言处理和人工智能的发展。
26、2、本发明包括将多模态认知信息利用预先训练好的动态集成多模式认知信息提取网络dimc以提取融合特征g,该方法具有强大的能力,可以较好的完成动态链接任务,将现实世界中非结构化、口语化的信息与知识库中结构化、条理化的实体进行链接与统一。
27、3、针对模糊实体表示的问题,该问题妨碍了人类认知和知识库的统一,本发明中的知识库中各个实体的文本特征为知识库中各个实体输入大语言模型得到的输出文本通过文本编码器编码得到,利用大语言模型在知识库上的快速学习能力,动态提取实体的表示,解决了模糊的实体表示问题。
本文地址:https://www.jishuxx.com/zhuanli/20240914/294405.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。