基于数据仓库中JSON数据的压缩方法、装置、车辆及介质与流程
- 国知局
- 2024-09-19 14:34:29
本技术涉及大数据分析,特别涉及一种基于数据仓库中json数据的压缩方法、装置、车辆及介质。
背景技术:
1、在车辆网数据处理领域,面对大规模数据的挑战,业内常采用原始16进制报文或解析后的json格式报文,然而,这两种方式存在以下技术问题:
2、1、原始16进制报文:解析成本高,不具可行性,限制了数据实际应用价值。
3、2、解析后的json格式报文:数据集巨大,其中定义了数以千计的字段,但并不是每一个字段都包含有值,存储成本高,数据体积大,存储开销显著。
4、3、频繁变动的数据结构:json数据格式的灵活性,尽管对于动态扩展字段非常适用,但对于数据仓库这种相对固定的环境来说,json格式并不是最优选择,其复杂度高,维护成本大,对动态数据难以灵活适应。
5、目前,现有技术可使用通用的数据存储和压缩技术,其实现技术手段如下:
6、1、关系型数据库:用于存储和查询数据;
7、2、数据压缩算法(例如gzip、snappy):用于压缩数据以节省存储空间;
8、3、自定义数据处理流程:为了满足数据仓库的需求,通常需要构建定制的数据处理流程,包括数据转换和清理。
9、然而,现有技术无法有效应对巨大的数据集中的空值字段,浪费存储空间,且json格式的灵活性增加了数据处理的复杂性,降低了查询性能,此外,现有技术的效率和性能在数据仓库环境下不够理想,导致资源浪费和性能下降,亟待解决。
技术实现思路
1、本技术提供一种基于数据仓库中json数据的压缩方法、装置、车辆及介质,以解决现有技术无法有效应对巨大的数据集中的空值字段,浪费存储空间,且json格式的灵活性增加了数据处理的复杂性,降低了查询性能,此外,现有技术的效率和性能在数据仓库环境下不够理想,导致资源浪费和性能下降等问题。
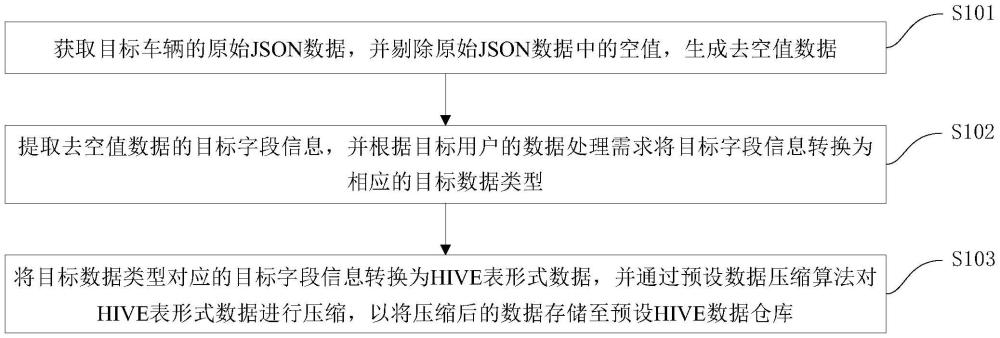
2、本技术第一方面实施例提供一种基于数据仓库中json数据的压缩方法,包括以下步骤:获取目标车辆的原始json数据,并剔除所述原始json数据中的空值,生成去空值数据;提取所述去空值数据的目标字段信息,并根据目标用户的数据处理需求将所述目标字段信息转换为相应的目标数据类型;将所述目标数据类型对应的目标字段信息转换为hive表形式数据,并通过预设数据压缩算法对所述hive表形式数据进行压缩,以将压缩后的数据存储至预设hive数据仓库。
3、可选地,在本技术的一个实施例中,所述剔除所述原始json数据中的空值,生成去空值数据,包括:遍历所述原始json数据的所有层级,检测每个层级的每个键值对是否存在空值,且获取并删除所述原始json数据的所有空值,以生成所述去空值数据。
4、可选地,在本技术的一个实施例中,所述提取所述去空值数据的目标字段信息,并根据目标用户的数据处理需求将所述目标字段信息转换为相应的目标数据类型,包括:提取所述去空值数据中第一层的每个键值对,并将所述第一层的每个键值对中的值转换为字符串类型,以得到所述去空值数据对应的第一层值转换数据,且将所述第一层值转换数据存储为第一层map类型数据;基于所述第一层map类型数据,确定所述去空值数据中第二层的每个json_str字段,并对所述每个json_str字段进行解析操作,以生成目标类型解析数据,且将目标类型解析数据存储为第二层map类型数据。
5、可选地,在本技术的一个实施例中,所述将所述目标数据类型对应的目标字段信息转换为hive表形式数据,包括:分别确定所述第一层map类型数据和的所述第二层map类型数据的列名和数据类型,以根据所述列名和数据类型将所述第一层map类型数据和所述第二层map类型数据表示为hive表形式数据;在所述第一层map类型数据对应的hive表形式数据中增加ext额外字段,得到所述第一层map类型数据对应的补充hive表形式数据;合并所述补充hive表形式数据和所述第二层map类型数据对应的hive表形式数据,以得到所述去空值数据对应的目标字段信息。
6、可选地,在本技术的一个实施例中,所述通过预设数据压缩算法对所述hive表形式数据进行压缩,以将压缩后的数据存储至预设hive数据仓库中,包括:将所述hive表形式数据转换为orc格式数据,并通过snappy压缩算法压缩所述orc格式数据,以得到orc格式压缩数据,且将所述orc格式压缩数据存储至所述预设hive数据仓库中。
7、本技术第二方面实施例提供一种基于数据仓库中json数据的压缩装置,包括:剔除模块,用于获取目标车辆的原始json数据,并剔除所述原始json数据中的空值,生成去空值数据;提取模块,用于提取所述去空值数据的目标字段信息,并根据目标用户的数据处理需求将所述目标字段信息转换为相应的目标数据类型;压缩模块,用于将所述目标数据类型对应的目标字段信息转换为hive表形式数据,并通过预设数据压缩算法对所述hive表形式数据进行压缩,以将压缩后的数据存储至预设hive数据仓库。
8、可选地,在本技术的一个实施例中,所述剔除模块包括:遍历单元,用于遍历所述原始json数据的所有层级,检测每个层级的每个键值对是否存在空值,且获取并删除所述原始json数据的所有空值,以生成所述去空值数据。
9、可选地,在本技术的一个实施例中,所述提取模块包括:第一转换单元,用于提取所述去空值数据中第一层的每个键值对,并将所述第一层的每个键值对中的值转换为字符串类型,以得到所述去空值数据对应的第一层值转换数据,且将所述第一层值转换数据存储为第一层map类型数据;解析单元,用于基于所述第一层map类型数据,确定所述去空值数据中第二层的每个json_str字段,并对所述每个json_str字段进行解析操作,以生成目标类型解析数据,且将目标类型解析数据存储为第二层map类型数据。
10、可选地,在本技术的一个实施例中,所述压缩模块包括:确定单元,用于分别确定所述第一层map类型数据和的所述第二层map类型数据的列名和数据类型,以根据所述列名和数据类型将所述第一层map类型数据和所述第二层map类型数据表示为hive表形式数据;增加单元,用于在所述第一层map类型数据对应的hive表形式数据中增加ext额外字段,得到所述第一层map类型数据对应的补充hive表形式数据;合并单元,用于合并所述补充hive表形式数据和所述第二层map类型数据对应的hive表形式数据,以得到所述去空值数据对应的目标字段信息。
11、可选地,在本技术的一个实施例中,所述压缩模块还包括:第二转换单元,用于将所述hive表形式数据转换为orc格式数据,并通过snappy压缩算法压缩所述orc格式数据,以得到orc格式压缩数据,且将所述orc格式压缩数据存储至所述预设hive数据仓库中。
12、本技术第三方面实施例提供一种车辆,包括:存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述程序,以实现如上述实施例所述的基于数据仓库中json数据的压缩方法。
13、本技术第四方面实施例提供一种计算机可读存储介质,所述计算机可读存储介质存储计算机程序,该程序被处理器执行时实现如上的基于数据仓库中json数据的压缩方法。
14、由此,本技术的实施例具有以下有益效果:
15、本技术的实施例可通过获取目标车辆的原始json数据,并剔除原始json数据中的空值,生成去空值数据;提取去空值数据的目标字段信息,并根据目标用户的数据处理需求将目标字段信息转换为相应的目标数据类型;将目标数据类型对应的目标字段信息转换为hive表形式数据,并通过预设数据压缩算法对hive表形式数据进行压缩,以将压缩后的数据存储至预设hive数据仓库。本技术能够有效提高json数据在数据仓库中的读取性能,以满足数据分析和查询需求,显著减小数据存储需求,降低存储空间成本,且充分利用hive分布式数据仓库能力,优化数据存储和查询过程。由此,解决了现有技术无法有效应对巨大的数据集中的空值字段,浪费存储空间,且json格式的灵活性增加了数据处理的复杂性,降低了查询性能,此外,现有技术的效率和性能在数据仓库环境下不够理想,导致资源浪费和性能下降等问题。
16、本技术附加的方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本技术的实践了解到。
本文地址:https://www.jishuxx.com/zhuanli/20240919/298926.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。