基于证据理论的产业链校正方法、系统和设备
- 国知局
- 2024-10-09 16:09:10
本发明涉及自然语言处理,具体而言,涉及一种基于证据理论的产业链校正方法、系统和设备。
背景技术:
1、产业链是产业经济学中的一个概念,即产供销,从原料到消费者手中的整个产业链条,是各个部门之间基于一定的技术经济关联,并依据特定的逻辑关系和时空布局关系客观形成的链条式关联关系形态。
2、目前,关于产业链的构建主要有两种方式:一种是传统的人工方式,另一种是基于机器学习的方法,例如申请号为202310260247.6的中国发明专利,公开了一种产业链构建和迭代扩充开发方法,其根据产业语料获取上下位关系和并列语义关系得到新词之间的关系,构建产业链树,设计专属的数据存储结构存储,迭代并扩充产业链树构建产业链。申请号为202211674470.7的中国发明专利,公开了一种企业产业链构建、授信方法、装置、服务器及存储介质,其根据税务数据构建神经网络寻找上下游企业,进而根据关联下游企业和下游企业的信息构建企业产业链。申请号为202210254413.7的中国发明专利,公开了一种产业链构建方法、设备及存储介质,其根据词训练模型在企业数据的基础构建产业链。
3、但上述方法因为数据源单一、主观偏差和信息滞后的问题,容易导致产业链中部分关系构建错误。为解决该问题,本发明提出一种基于证据理论的产业链校正方法及系统,该方法通过互联网数据检索现有产业链,应用证据理论判断产业链三元组的可信度,优化现有产业链,为决策者提供更为可靠的依据。
技术实现思路
1、本发明旨在至少解决现有技术中存在的技术问题之一。
2、为此,本发明第一方面提供了一种基于证据理论的产业链校正方法。
3、本发明第二方面提供了一种基于证据理论的产业链校正系统。
4、本发明第三方面提供了一种计算机设备。
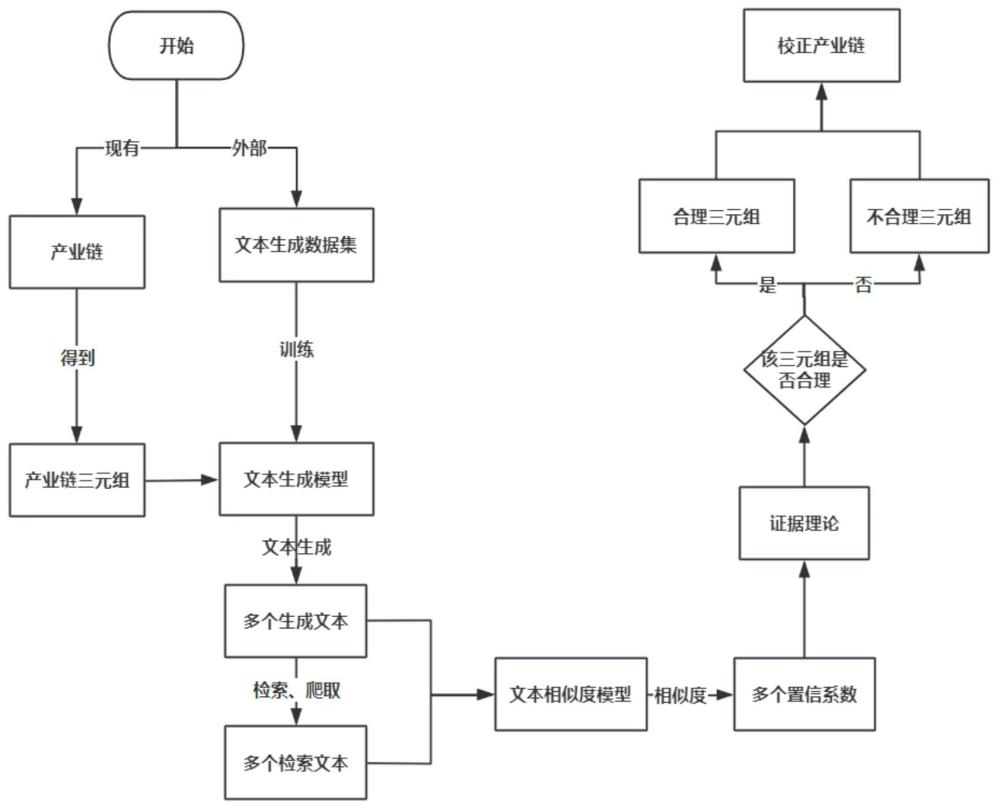
5、本发明提出的基于证据理论的产业链校正方法,包括:
6、根据已有产业链信息,获取具有上下游关系的产业链三元组;
7、使用外部数据集训练文本生成模型,基于所述文本生成模型生成若干个与产业链三元组相关的生成文本;其中,所述外部数据集包括用以表示产品上下游的三元组,以及描述该三元组的文本;
8、搭建文本相似度模型,并使用公开数据集训练文本相似度模型;
9、从搜索引擎逐一检索所述生成文本,每个生成文本的检索任务包括收集检索结果,并通过文本相似度模型计算生成文本与检索文本的相似度,将最高相似度值作为该生成文本的置信系数;
10、应用证据理论构建信任分配函数,使用置信系数计算信任函数值,根据信任函数值将产品三元组划分为合理三元组或不合理三元组,并基于划分结果校正产业链。
11、根据本发明上述技术方案的基于证据理论的产业链校正方法,还可以具有以下附加技术特征:
12、在上述技术方案中,所述根据已有产业链信息,获取具有上下游关系的产业链三元组,包括:
13、基于图论表示已有产业链,其中,每个节点表示为产品或服务,节点之间存在上游或者下游的关系,且产业链中的任意两个节点之间至少有一条连通路径,将每条连通路径定义为边;
14、提取产业链中相邻节点及其关系,得到具有上下游关系的产业链三元组。
15、在上述技术方案中,所述使用外部数据集训练文本生成模型,基于所述文本生成模型生成若干个与产业链三元组相关的生成文本,包括:
16、所述外部数据集为文本生成数据集,所述文本生成数据集包括由两个实体和关系组成的三元组,以及三条相互独立的用以描述该三元组的文本;
17、使用文本生成数据集训练文本生成模型,所述文本生成模型用于根据产业链三元组生成三句相互独立的用以描述产业链三元组的文本。
18、在上述技术方案中,所述使用文本生成数据集训练文本生成模型,包括:
19、将文本生成数据集中的每条数据分为输入文本和目标文本,其中,输入文本为由两个实体和关系组成的三元组,目标文本为三条相互独立的用以描述该三元组的文本;
20、将每条数据映射为模型内部的词汇表中的字符编码,返回一个带输入序列和目标序列的字典;
21、输入序列通过transformer编码器得到上下文相关的语义表示向量;
22、构建训练函数根据输入序列张量训练模型,将模型的输出结果与目标序列进行比较;使用交叉熵损失函数计算损失值,根据损失值进行反向传播,优化模型参数。
23、在上述技术方案中,所述搭建文本相似度模型,并使用公开数据集训练文本相似度模型,包括:
24、搭建计算文本相似度的孪生神经网络,所述孪生神经网络包括将文本转换为向量的嵌入层、捕捉上下文前后信息的双向lstm层以及计算文本相似度得分的线性层;
25、其中,公开数据集为公开的文本匹配数据集。
26、在上述技术方案中,所述从搜索引擎逐一检索所述生成文本,每个生成文本的检索任务包括收集检索结果,并通过文本相似度模型计算生成文本与检索文本的相似度,将最高相似度值作为该生成文本的置信系数,包括:
27、在搜索引擎中检索所述生成文本,并设计爬虫脚本获取检索结果;所述爬虫脚本包括:根据生成文本的内容构造搜索查询,获取目标网页,然后利用搜索引擎的特殊标签定位网页中的指定文本,爬取多个与生成文本相关的文本;
28、使用文本相似度模型计算生成文本和检索文本的文本相似度,得到多个相似度值,将最高的相似度值作为该生成文本的置信系数;其中,每个产业链三元组具有至少一个生成文本,产业链三元组具有与生成文本数量匹配的y个置信系数。
29、在上述技术方案中,所述应用证据理论构建信任分配函数,使用置信系数计算信任函数值,根据信任函数值将产品三元组划分为合理三元组或不合理三元组,并基于划分结果校正产业链,包括:
30、基于置信系数结合ds证据理论设计识别框架和信任分配函数;
31、其中,设计识别框架θ,,识别框架θ里面所有命题互斥,表示此三元组合理,表示此三元组不合理;和分别表示第i个置信系数对命题和命题的置信度,即信任函数值,且+=1;
32、对信任函数值进行计算,比较和大小;当大于时认为该三元组合理,小于时认为该三元组不合理,将所有产业链三元组分为合理和不合理两类,删除不合理的三元组,得到校正后的产业链。
33、在上述技术方案中,所述信任函数值的计算方法包括:
34、计算冲突系数k,计算公式为:
35、
36、其中,n表示置信系数的数量,i和j分别表示置信系数的编号;
37、使用ds合成规则合成计算命题的信任函数值,计算公式为:
38、
39、同理可以计算得到命题的信任函数值。
40、本发明提供的一种基于证据理论的产业链校正系统,包括:
41、数据处理模块,根据已有产业链信息,获取具有上下游关系的产业链三元组;
42、文本生成模块,使用外部数据集训练文本生成模型,基于所述文本生成模型生成若干个与产业链三元组相关的生成文本;其中,所述外部数据集包括用以表示产品上下游的三元组,以及描述该三元组的文本;
43、文本相似度模块,搭建文本相似度模型,并使用公开数据集训练文本相似度模型;
44、置信系数模块,从搜索引擎逐一检索所述生成文本,每个生成文本的检索任务包括收集检索结果,并通过文本相似度模型计算生成文本与检索文本的相似度,将最高相似度值作为该生成文本的置信系数;
45、三元组校正模块,应用证据理论构建信任分配函数,使用置信系数计算信任函数值,根据信任函数值将产品三元组划分为合理三元组或不合理三元组,并基于划分结果校正产业链。
46、本发明提供的一种计算机设备,包括处理器和存储器,所述存储器中存储有计算机程序,当所述计算机程序被所述处理器加载并执行时实现如上述技术方案中任一项所述的基于证据理论的产业链校正方法。
47、综上所述,由于采用了上述技术特征,本发明的有益效果是:
48、本发明中基于证据理论校正产业链,具体地,本发明结合预训练模型和数据挖掘得到产业链的相关信息,通过证据理论判断产业链三元组的合理性,校正产业链。有效解决传统方法中由于数据源单一、主观偏差和信息滞后所引发的产业链关系构建错误问题,优化现有产业链,为决策者提供更为可靠的依据。
49、本发明的附加方面和优点将在下面的描述部分中变得明显,或通过本发明的实践了解到。
本文地址:https://www.jishuxx.com/zhuanli/20240929/311881.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表