一种多车自动驾驶博弈协同定向规划方法、装置及介质
- 国知局
- 2024-10-09 15:10:41
本发明涉及自动驾驶技术,尤其是涉及一种多车自动驾驶博弈协同定向规划方法、装置及介质。
背景技术:
1、自动驾驶汽车,又称无人驾驶汽车、电脑驾驶汽车或轮式移动机器人,它依靠人工智能、视觉计算、雷达、监控装置和全球定位系统协同合作,让电脑可以在没有人的主动操作下实现车路协同,自动安全地操作机动车辆。
2、现有的基于强化学习的多无人车自动驾驶定向规划算法通常是独立的多智能体强化学习算法,无人驾驶车辆独立训练,这类方法难以兼顾车辆间的协作,导致车辆密度大时通过路口的效率降低。同时当前多无人车自动驾驶定向规划应用的基于dqn的强化学习算法只能输出一个方向盘和油门的耦合动作,导致预测精度较低,控制不稳定。
技术实现思路
1、本发明的目的就是为了克服上述现有技术存在的预测精度低,通过效率低的缺陷而提供一种多车自动驾驶博弈协同定向规划方法、装置及介质。
2、本发明的目的可以通过以下技术方案来实现:
3、一种多车自动驾驶博弈协同定向规划方法,包括以下步骤:
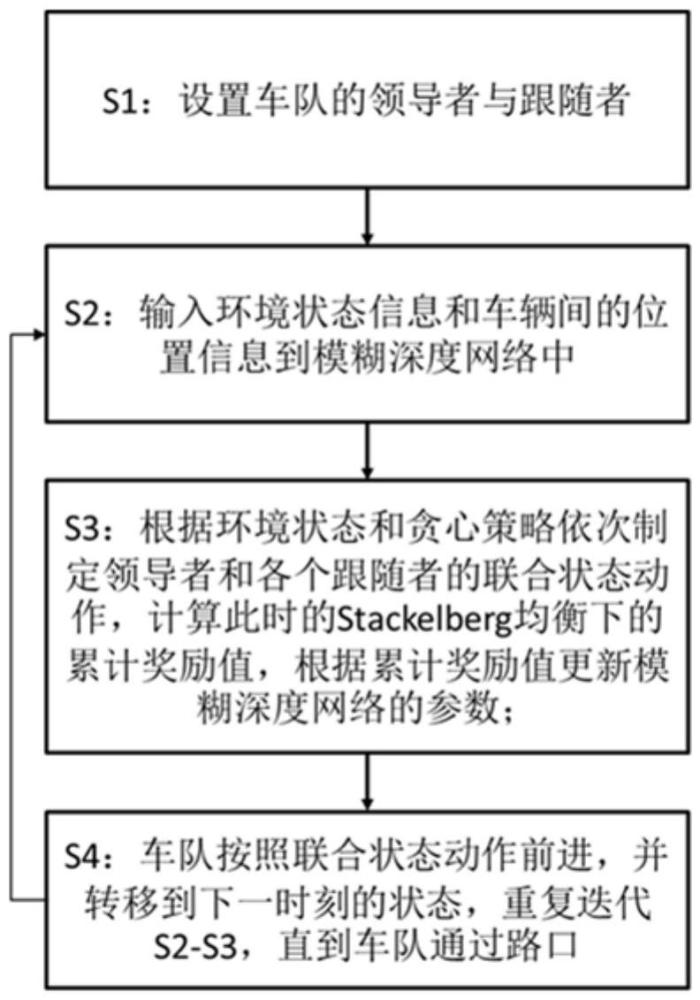
4、s1:将车队按次序排列,第一辆车设置为领导者,将后续车辆均设置为跟随者;
5、s2:将环境状态信息和车辆间的位置信息作为状态量输入设计的模糊深度网络;
6、s3:通过模糊深度网络,根据环境状态和贪心策略选择领导者的最优动作,根据领导者、环境状态和前序的跟随者依次选择各个跟随者的最优动作,得到联合状态动作,计算此时的stackelberg均衡下的累计奖励值,根据累计奖励值更新模糊深度网络的参数;
7、s4:车队按照联合状态动作前进,并转移到下一时刻的状态,重复迭代s2-s3,直到车队通过路口。
8、进一步地,stackelberg均衡的博弈公式为:
9、
10、式中,σi(·)为无人车i的策略,为其余无人车的策略,gi(·)为无人车i随时间的累积效用,s0为初始状态。
11、进一步地,stackelberg均衡的的均衡条件为:
12、
13、式中,mk(·)表示智能体k在联合动作下的回报函数。
14、进一步地,奖励值为当所有车辆采取stackelberg均衡解时的累积奖励之和,计算表达式为:
15、
16、式中,(σ1,...,σn)表示stackelberg均衡策略,ri(s,a1,...,an)是状态s下采取联合动作(a1,...,an)的奖励,vi(s',σ1,...,σn)表示在区间内每辆车都服从stackelberg均衡策略所得到的累计奖励和。
17、进一步地,迭代过程中,奖励值的计算表达式为:
18、
19、式中,α为学习率,γ为衰减率,是在状态s'下所得到的stackelberg均衡值。
20、进一步地,联合动作的奖励计算表达式为:
21、
22、式中,rt为时间步长t的积分奖励,ξ∈[0,1]是平衡rt2和rt3比例的参数,rt2和rt3分别代表水平方向的奖励和竖直方向的惩罚,d为车辆中心与上一目标点的距离,d0为相邻两目标点间的距离,t为相邻两车中心点的距离,t0为相邻两车中心点的期望距离。
23、进一步地,最优动作包括转向角动作空间和油门动作空间。
24、进一步地,模糊深度网络的输出为模糊变量,计算模糊变量的平均值,得到转向角动作空间和油门动作空间的数值,表达式为:
25、
26、式中,和分别为时间步长为t的转角和油门的最终输出值,u(·)表示隶属度函数,即对应运动命令的概率,ns和na分别表示舵角和油门作用的最大隶属度数。
27、本发明的第二方面,一种多车自动驾驶博弈协同定向规划装置,包括存储器、处理器,以及存储于存储器中的程序,其特征在于,处理器执行程序时实现如上任一的一种多车自动驾驶博弈协同定向规划方法。
28、本发明的第三方面,一种存储介质,其上存储有程序,其特征在于,程序被执行时实现如上任一的一种多车自动驾驶博弈协同定向规划方法。
29、与现有技术相比,本发明具有以下有益效果:
30、1)本发明结合stakelberg博弈方法,将多无人车自动驾驶运动规划问题建模为stakelberg博弈问题,将头车作为领导者,其余车辆作为跟随者根据环境状态信息和车辆间的位置信息依次进行决策得到各自的最优路径,其均衡表现为所有无人车采取合作策略,按照固定车距排队通过路口,提高通过路口的效率。
31、2)本发明去模糊化的方法引入到方法中,考虑方向角和油门两个控制命令,使用最后全连接层神经节点输出的五个模糊变量的平均值作为时间步长t的方向盘角度和油门的数值,实现方向盘和油门的独立输出,降低动作空间的维度,提高预测精度。
32、3)本发明通过全局路径提高训练效率,将无人车的路径划分为多个离散的子目标点,以此来计算奖励和更新状态。当车辆到达一个子目标点时,更新下一个子目标点作为状态量输入到神经网络中,提升期望车道跟踪的训练效率。
技术特征:1.一种多车自动驾驶博弈协同定向规划方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的一种多车自动驾驶博弈协同定向规划方法,其特征在于,所述stackelberg均衡的博弈公式为:
3.根据权利要求2所述的一种多车自动驾驶博弈协同定向规划方法,其特征在于,所述stackelberg均衡的的均衡条件为:
4.根据权利要求1所述的一种多车自动驾驶博弈协同定向规划方法,其特征在于,所述奖励值为当所有车辆采取stackelberg均衡解时的累积奖励之和,计算表达式为:
5.根据权利要求4所述的一种多车自动驾驶博弈协同定向规划方法,其特征在于,所述迭代过程中,奖励值的计算表达式为:
6.根据权利要求4所述的一种多车自动驾驶博弈协同定向规划方法,其特征在于,所述联合动作的奖励计算表达式为:
7.根据权利要求1所述的一种多车自动驾驶博弈协同定向规划方法,其特征在于,所述最优动作包括转向角动作空间和油门动作空间。
8.根据权利要求7所述的一种多车自动驾驶博弈协同定向规划方法,其特征在于,所述模糊深度网络的输出为模糊变量,计算模糊变量的平均值,得到转向角动作空间和油门动作空间的数值,表达式为:
9.一种多车自动驾驶博弈协同定向规划装置,包括存储器、处理器,以及存储于所述存储器中的程序,其特征在于,所述处理器执行所述程序时实现如权利要求1-8中任一所述的一种多车自动驾驶博弈协同定向规划方法。
10.一种存储介质,其上存储有程序,其特征在于,所述程序被执行时实现如权利要求1-8中任一所述的一种多车自动驾驶博弈协同定向规划方法。
技术总结本发明涉及一种多车自动驾驶博弈协同定向规划方法、装置及介质,方法包括以下步骤:将车队按次序排列,第一辆车设置为领导者,将后续车辆均设置为跟随者;将环境状态信息和车辆间的位置信息作为状态量输入设计的模糊深度网络;通过模糊深度网络,根据环境状态和贪心策略选择领导者的最优动作,根据领导者、环境状态和前序的跟随者依次选择各个跟随者的最优动作,得到联合状态动作,计算此时的Stackelberg均衡下的累计奖励值,根据累计奖励值更新模糊深度网络的参数;车队按照联合状态动作前进,并转移到下一时刻的状态,重复迭代,直到车队通过路口。与现有技术相比,本发明具有通过效率高、预测精度高等优点。技术研发人员:柳春,景冠博,徐梁,孟亦真,任肖强,修贤超,刘晗笑,汪小帆受保护的技术使用者:上海大学技术研发日:技术公布日:2024/9/29本文地址:https://www.jishuxx.com/zhuanli/20241009/307941.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。