一种基于事实检索和验证增强的可解释问答方法及系统
- 国知局
- 2024-10-15 09:43:14
本发明属于自然语言处理,具体涉及一种基于事实检索和验证增强的可解释问答方法及系统。
背景技术:
1、智能问答(questionanswering,qa)是使计算机理解文章语义并且回答相关问题的技术,是自然语言处理(natural language processing,nlp)领域的一项重要研究任务,也是验证机器智能水平的有效评测手段,在信息检索、智能客服、智慧司法等领域具有广泛的应用价值。
2、近年来,随着深度学习技术的快速发展,尤其是以chatgpt为代表的大语言模型异军突起,智能问答任务的性能取得了显著提升,甚至在一些指标上超越了人类表现。然而,基于深度神经网络的语言模型本质是“黑盒”的,且随着模型参数量的不断增大以及复杂性的不断提高,问答系统的不可解释性愈加凸显,用户对于模型给出的答案通常是“知其然,而不知其所以然”,这严重阻碍了问答系统在关键领域的应用。因此,研究问答系统的可解释性至关重要,提供从问题到答案的推理过程有助于提高模型的可调式性和可信性。
3、可解释问答(explainable questionanswering,xqa)的目的是在回答一个问题的同时给出相应的解释。目前的相关研究主要集中在三方面:抽取包含答案的关键词、生成多跳的结构化解释链以及生成自由形式的文本解释。其中,结构化蕴涵树通过展示从给定事实到答案的推理过程,能够以更加清晰且丰富的形式为用户提供解释。目前结构化蕴涵树的生成得到了广泛研究,现有的大多数相关工作采用逐步的方式生成结构化推理链,rlet设计了一种基于强化学习的蕴涵树生成框架,通过句子选择模块和演绎生成模块迭代执行单步推理;nlproofs引入独立的验证机制来检验证明步骤的有效性,防止生成幻觉的无效步骤;metgen提出基于模块化的蕴涵树生成方法,且引入后向推理的方式增强证明步骤的有效性。
4、已有的结构树生成方法仍然面临两个挑战:(1)由于事实搜索空间较大而导致组合失败;(2)存在错误累积而生成无效步骤。目前的工作主要采用前向演绎推理的方式执行单步推理。演绎推理是一种自底向上的前向推理方式,需要通过迭代搜索已知事实生成中间结论,直到证明目标假设。随着新的推理结论加入知识事实,搜索空间在每次迭代中不断扩大,容易导致组合失败。此外,逐步生成方法固有地存在错误累积问题,随着证明步骤的增加,模型可能快速生成无效的证明,导致树结构的不正确性。
技术实现思路
1、针对目前结构树生成面临的搜索空间较大和错误累积的问题,本发明提供了一种基于事实检索和验证增强的可解释问答方法及系统。
2、为了达到上述目的,本发明采用了下列技术方案:
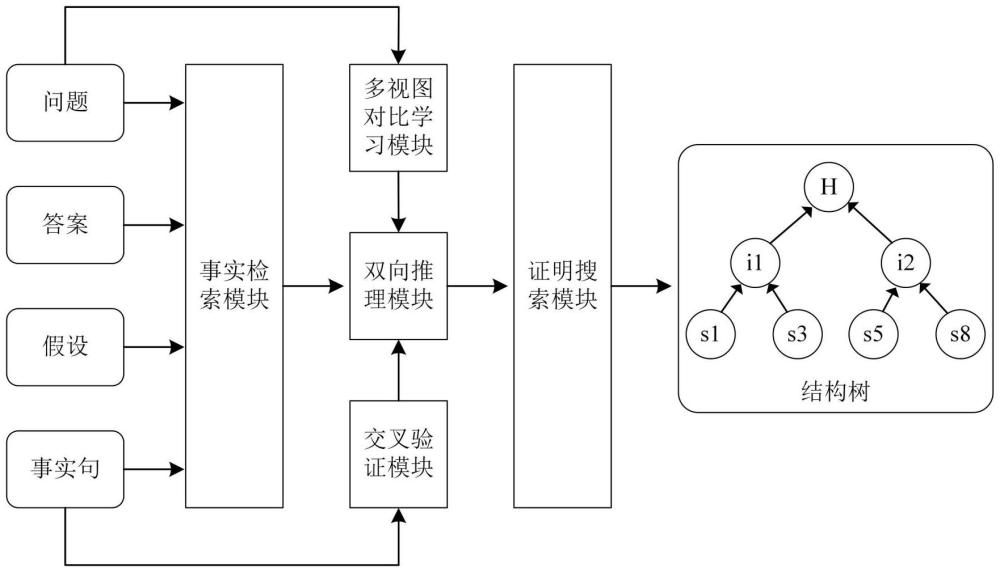
3、一种基于事实检索和验证增强的可解释问答系统,包括事实检索模块、双向推理模块、多视图对比学习模块、交叉验证模块和证明搜索模块;
4、所述事实检索模块,用于对基于上下文构建的候选事实集合进行过滤,动态剔除与目标假设(由问题和答案构建)不相关的事实以减小搜索空间;
5、所述双向推理模块,采用编码器-解码器架构的预训练语言模型t5-large分别作为演绎和溯因推理器,以演绎(自下而上)和溯因(自上而下)的方式生成单步证明步骤,并通过迭代计算分别获得演绎和溯因候选结构树;
6、所述多视图对比学习模块,在演绎和溯因推理器的编码器端利用目标假设与训练数据中给定的黄金事实句构建局部对比损失,在解码器端利用束搜索算法生成的候选步骤以及原始数据中的黄金步骤和训练批次内的其余目标步骤构建全局对比损失;
7、所述交叉验证模块,利用训练数据中的黄金步骤构建演绎和溯因数据并训练演绎和溯因评分器,以增强双向推理时单个证明步骤的可靠性;
8、所述证明搜索模块,对演绎和溯因推理获得的候选结构树进行对齐,并在联合构建的图中进行搜获以获得最佳的结构树,获得从上下文事实句到目标假设的推理步骤。
9、基于事实检索和验证增强的可解释问答系统的可解释问答方法,包括以下步骤:
10、步骤1:通过事实检索模块对基于上下文构建的候选事实集合作初步过滤,动态剔除与假设不相关的知识事实;
11、步骤2:利用双向推理模块生成单个证明步骤,其中演绎和溯因生成器分别以自下而上和自上而下的方式生成候选步骤;
12、步骤3:利用多视图对比学习模块拉近假设与黄金事实的语义距离,从相似性的角度增强证明步骤的可靠性;
13、步骤4:利用交叉验证模块对演绎和溯因步骤进行相互验证,从支持性的角度增强证明步骤的可靠性;
14、步骤5:通过证明搜索模块将双向推理获得的候选结构树进行对齐,并设计融合算法获得最佳结构树。
15、进一步,所述步骤1通过事实检索模块对候选事实集合作初步过滤,动态剔除与假设不相关的知识事实具体包括以下步骤:
16、步骤1.1,采用预训练语言模型albert作为编码器,对假设h和事实senti进行编码,采用平均池化获得假设h的句子嵌入表示h,以及每个事实的句子嵌入表示fi;
17、步骤1.2,采用由全连接神经网络构建的多层感知机获取每个事实的相关性分数,计算公式如下所示:
18、
19、其中,σ是sigmoid激活函数,[·]表示拼接操作,mlpfact是由两层前馈网络组成的多层感知机,表示每个句子的相关性分数;
20、在树结构中,如果一个事实的深度较小,即更加接近根节点,那么它应该比深度较大的事实更加接近目标假设。因此,在训练时采用一种边际排序作为检索器的损失,计算公式如下所示:
21、
22、其中,是黄金树中深度小于的事实,s-是候选事实集合s中其余的无关事实,n1是对的数量,n2是干扰事实的数量,是事实的边际,ψ是边际损失,是最终得到的损失;基于上述事实评分设计阈值对每一组候选事实集合动态筛选。
23、进一步,所述步骤2利用双向推理模块生成单个证明步骤(包括两个叶节点和一个生成的中间结论),其中演绎和溯因生成器分别以自下而上和自上而下的方式生成候选步骤具体包括以下步骤:
24、步骤2.1,采用编码器-解码器架构的预训练语言模型t5-large作为演绎和溯因推理器,分别执行自下而上和自上而下的单步证明步骤生成;
25、步骤2.1.1,从黄金树的证明步骤中分别构建演绎和溯因的训练数据,
26、步骤2.1.2,以自下而上的方式构建演绎训练数据:对于演绎,以自下而上的方式构建,每一步的输入除了假设h和事实集合外,还包括先前步骤的输出;然后,将当前时刻生成的步骤作为下一步模型输入的一部分,以此不断迭代生成证明步骤,直到输出假设的标记“hypothesis”终止;
27、步骤2.1.3,以自上而下的方式构建溯因训练数据:对于溯因,以自上而下的方式从黄金树中构建训练数据,将演绎步骤的根节点与某一个叶节点互换来构建溯因步骤,溯因模型输出步骤中的某个叶节点为上一步溯因模型生成的中间结论,然后将该步骤作为下一步溯因模型的输入并迭代生成步骤,当不再生成中间结论时终止;
28、步骤2.2,构建演绎和溯因训练数据,并分别训练演绎和溯因生成器,计算公式如下所示:
29、
30、其中,gt表示t时刻生成的证明步骤,s′表示过滤后的知识事实集合,encoder-decoder表示序列到序列模型的编码器和解码器,表示1到t-1时刻生成的所有溯因步骤;表示1到t-1时刻生成的所有溯因步骤;表示t时刻生成的演绎步骤;表示t时刻生成的溯因步骤;训练时最大化条件概率似然损失,其中演绎生成器的损失计算公式如下所示:
31、
32、其中,表示生成器的训练损失,z表示训练数据总数,步骤中的每个token表示为l表示步骤长度。
33、进一步,所述步骤3利用多视图对比学习模块拉近假设与黄金事实的语义距离,从相似性的角度增强证明步骤的可靠性具体包括以下步骤:在演绎和溯因的编码器、解码器端设计融合局部和全局信息的多视图对比学习损失,从语义表示层面拉近黄金事实与目标假设的距离,使得生成的证明步骤更加接近假设;
34、步骤3.1,在编码器端设计局部对比信息,对假设h和事实句编码后得到假设的句子表示h'以及每个事实的句子表示fi';
35、步骤3.1.1,构建正负样本:以训练数据给定的黄金树的叶节点作为正例,然后计算候选事实集合中的非黄金事实与假设的余弦相似性,分数大于某个阈值的事实也作为正例,事实集合中的其余事实为负例;
36、基于上述正负样例构建局部级别的对比损失,计算过程如下公式所示:
37、
38、其中fi′+表示黄金事实句的嵌入,s′gold是黄金事实集合,τ是可配置的温度系数超参数,fi′是所有事实句的嵌入,sim(·)是相似性度量函数,计算公式如下所示:
39、
40、其中,x,y分别表示两个句子的嵌入,xt表示对句子x的嵌入向量进行转置;
41、步骤3.2,在解码器端设计全局信息的对比损失;
42、对于生成式模型的输出,句子之间语义信息的差异并不能完全通过正负样本标签进行分离,换句话说,即使是负样本也不一定与目标输出不相关;
43、在解码器端通过束搜索算法得到u个多样化的输出嵌入,然后结合目标输出嵌入以及当前批次内其余样本的输出一起构建对比样本集合w={k1,k2,...,kt},并创建样本对(k+,k-)∈w,其中,k表示每一个样本的嵌入表示,+和-由样本的排名决定,该排名是通过与目标输出计算序列级分数得到,用于反映对比样本之间的相对差异;全局信息的对比学习损失计算过程如下所示:
44、
45、其中,ex表示目标输出的嵌入表示,为样本的嵌入表示,表示边际,cos(·)表示相似性计算。
46、进一步,所述步骤4利用交叉验证模块对演绎和溯因步骤进行相互验证,从支持性的角度增强证明步骤的可靠性具体包括以下步骤:对演绎和溯因推理器每一步生成的候选步骤作交叉验证,从支持性的角度增强单个证明步骤的可靠性;
47、步骤4.1,将训练数据中黄金树的步骤转换为溯因步骤,分别构建演绎对和溯因对。
48、步骤4.2,通过微调预训练的albert预训练语言模型联合学习演绎与溯因验证器,对于每一组步骤对,将其表示为(x1,x2,y),然后将前两个句子拼接,与最后一个句子计算的相关性分数作为该步骤的分数,计算过程如下公式所示:
49、
50、其中,σ是sigmoid激活函数,mlpded和mlpabd分别是演绎和溯因的多层感知机,stepded和stepabd分别是演绎和溯因步骤;将黄金证明步骤视作正例,反例则通过随机替换事实集合中的一个前提为非黄金事实来构建,正负比例设定为1:1,验证器的损失函数采用二元交叉熵损失。
51、进一步,所述步骤5通过证明搜索模块将双向推理获得的候选结构树进行对齐,并设计融合算法获得最佳结构树具体包括以下步骤:将演绎和溯因生成器分别得到的树对齐到一个证明图中,并根据每个节点的得分搜索最佳的结构树,其中,图的节点来自两棵候选树的节点,边是每个证明步骤的前提节点指向结论节点。
52、步骤5.1,基于步骤2.2中演绎生成器获得的演绎树构建初始图,该演绎树的叶节点和中间结论节点均作为初始图的节点;
53、步骤5.2,然后将步骤2.2中溯因生成器获得的溯因树置信度大于阈值的部分融入初始图,扩充证明图的节点和边,同时为每个节点分配分数;叶节点分数设置为1.0,中间结论节点的分数为自回归语言模型的置信分数和交叉验证器分数之和;
54、步骤5.3,最后根据证明图及各个节点的分数,通过在图上探索不同的路径抽取出最佳的结构树。
55、一种电子设备,包括至少一个处理器,以及至少一个与处理器通信连接的存储器,所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行权利要求1~6任意一项所述基于事实检索和验证增强的可解释问答方法。
56、一种存储有计算机指令的非暂态计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行所述事实检索和验证增强的可解释问答方法。
57、与现有技术相比本发明具有以下优点:
58、(1)本发明提出一种基于事实检索和验证增强的可解释问答方法及系统,通过事实检索动态过滤与目标假设不相关的知识事实,有效减小了搜索空间。
59、(2)本发明设计了基于演绎-溯因推理的双向证明生成方法,并提出交叉验证和多视图对比学习机制,从支持性和相似性两个角度增强了单个证明步骤的可靠性。
60、(3)本发明通过优化学习各子任务,能够准确生成问题回答的结构化推理链,增强了问答系统的可解释性。
本文地址:https://www.jishuxx.com/zhuanli/20241015/315092.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。