针对大型语言模型的自动化缺陷检测系统及方法与流程
- 国知局
- 2024-10-15 10:08:35
本发明属于人工智能,涉及一种针对大型语言模型的缺陷检测系统及方法,尤其涉及一种针对大型语言模型的自动化缺陷检测系统及方法。
背景技术:
1、近年来,大型语言模型(llm)取得了令人瞩目的发展,在越来越多的任务上表现出了强大的能力。但它们仍然存在许多缺陷,可能在一些简单的任务上出现意想不到的错误。例如,llm能够完成一些复杂的算法问题,但在基础操作中会错误地在集合中加入重复元素。这些意料之外的错误可能导致llm在实际部署生产中带来严重的隐患。因此,系统识别并解决llm的缺陷,对于提升llm的性能和可靠性有着重要意义。
2、为了掌握llm在各种任务上的效果,目前存在各种评估基准,例如gsm8k,humaneval,treeeval等。然而这些评估基准的设计目的并非发掘模型缺陷,而是公平地对比各个模型,这让它们无法全面又针对性地执行缺陷发掘任务。此外,静态评估基准往往更新周期长,容易出现数据泄漏和区分度较小的问题;而动态评估基准不够通用,很难适用于各类任务。这些问题都导致它们难以充分发掘特定llm的潜在缺陷。
3、红队攻击是安全领域的一种常用的手段,即通过尝试各类输入诱导llm犯错,发现其潜在的各种安全漏洞。早期的红队攻击同样主要依赖人工精心设计各种对抗性输入,虽然这样的攻击成功率较高,但是需要雇佣大量专业标注人员,使其难以大规模应用。因此,使用语言模型进行自动化红队攻击的方法逐渐得到广泛的应用,并在安全攻击方面取得了许多显著的成效。然而,在通用任务上执行缺陷发掘的方法还没有被探索。此外,安全任务的覆盖类型较少,搜索空间较小。因此当红队攻击方法扩展到指令遵从、数学等通用任务时,很难取得理想的效果。
4、因此,现有的识别llm缺陷的方法均存在明显的不足。人工检查llm的缺陷涉及到大量人类专家的参与,需要大量的人力物力,难以规模化扩展。现有的自动检查llm缺陷的方式主要依赖评估基准,但评估基准的构建目的主要是公平地对比一系列模型的表现强弱,无法彻底地,有针对性地发掘特定模型的缺陷。同时,评估基准大多存在更新周期长、数据泄漏、区分度较小等问题,这些都不利于依赖评估基准对llm进行全面的、有针对性的缺陷发掘。
5、基于此,针对上述现有技术中存在的缺陷,需要研发一种新型的针对大型语言模型的自动化缺陷检测系统及方法。
技术实现思路
1、为了克服现有技术的缺陷,本发明提出一种针对大型语言模型的自动化缺陷检测系统及方法,其能够在多个大型语言模型上实现可观的发现缺陷的成功率,并且从这些缺陷中学习能进一步帮助大型语言模型提升其性能。
2、为了实现上述目的,本发明提供如下技术方案:
3、一种针对大型语言模型的自动化缺陷检测系统,其特征在于,包括:
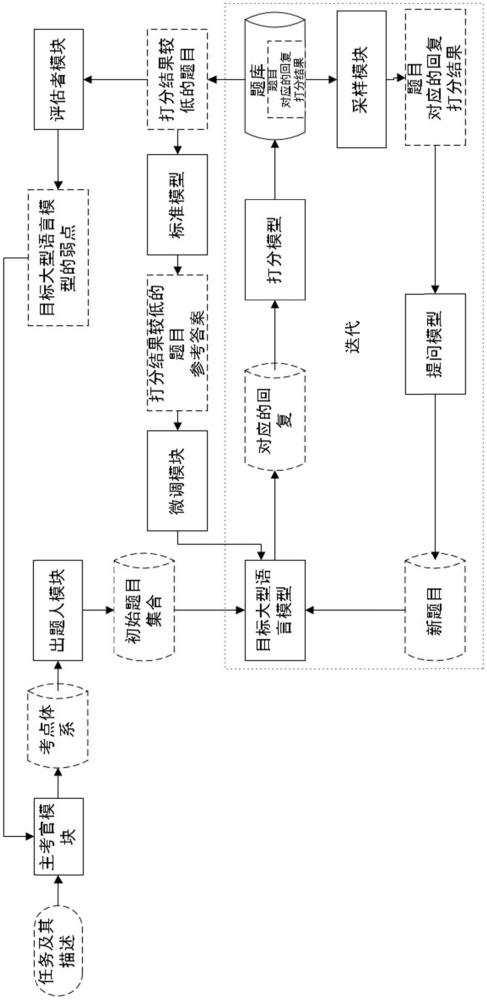
4、主考官模块,其用于基于任务及其描述生成考点体系;
5、出题人模块,其用于基于所述考点体系生成初始题目集合并将所述初始题目集合中的每个初始题目都输入目标大型语言模型中,由所述目标大型语言模型生成对应的回复;
6、打分模型,其用于对所述目标大型语言模型生成的回复进行打分以获得打分结果;
7、评估者模块,其用于基于打分结果较低的初始题目发掘所述目标大型语言模型的弱点并将所述弱点发送给所述主考官模块,使所述主考官模块基于所述弱点更新所述考点体系。
8、优选地,所述针对大型语言模型的自动化缺陷检测系统,其特征在于,进一步包括:
9、题库,每个初始题目及其对应的回复和打分结果都存入所述题库中。
10、优选地,所述针对大型语言模型的自动化缺陷检测系统,其特征在于,进一步包括:
11、采样模块,其用于从所述题库中采样多个初始题目及其对应的回复和打分结果并按照打分结果的高低对所述多个初始题目进行排序;
12、提问模型,其用于基于所述多个初始题目生成一个新题目并将所述新题目输入所述目标大型语言模型中,由所述目标大型语言模型生成对应的回复;
13、所述打分模型还用于对所述新题目对应的回复进行打分以获得打分结果,并且,所述评估者模块还用于基于打分结果较低的新题目生成所述目标大型语言模型的弱点并将所述弱点发送给所述主考官模块,使所述主考官模块基于所述弱点更新所述考点体系。
14、优选地,每个新题目及其对应的回复和打分结果也都存入所述题库中,并且,所述采样模块还用于从所述题库中采样多个新题目及其对应的回复和打分结果并按照打分结果的高低对所述多个新题目进行排序,所述提问模型还用于基于所述多个新题目生成一个更新的题目并将所述更新的题目输入所述目标大型语言模型中,由所述目标大型语言模型生成对应的回复。
15、优选地,所述针对大型语言模型的自动化缺陷检测系统,其特征在于,进一步包括:
16、标准模型,其用于基于所述新题目生成对应的参考答案;
17、微调模块,其用于基于所述新题目及其对应的参考答案对所述目标大型语言模型进行微调。
18、优选地,所述主考官模块、出题人模块和评估者模块均为大语言模型。
19、此外,本发明还一种针对大型语言模型的自动化缺陷检测方法,其特征在于,其采用了上述的针对大型语言模型的自动化缺陷检测系统,并包括以下步骤:
20、主考官模块基于任务及其描述生成考点体系;
21、出题人模块基于所述考点体系生成初始题目集合并将所述初始题目集合中的每个初始题目都输入目标大型语言模型中,由所述目标大型语言模型生成对应的回复;
22、打分模型对所述目标大型语言模型生成的回复进行打分以获得打分结果;
23、评估者模块基于打分结果较低的初始题目发掘所述目标大型语言模型的弱点并将所述弱点发送给所述主考官模块,使所述主考官模块基于所述弱点更新所述考点体系。
24、优选地,所述针对大型语言模型的自动化缺陷检测方法,其特征在于,进一步包括以下步骤:
25、将每个初始题目及其对应的回复和打分结果都存入题库中。
26、优选地,所述针对大型语言模型的自动化缺陷检测方法,其特征在于,进一步包括以下步骤:
27、采样模块从所述题库中采样多个初始题目及其对应的回复和打分结果并按照打分结果的高低对所述多个初始题目进行排序;
28、提问模型基于所述多个初始题目生成一个新题目并将所述新题目输入所述目标大型语言模型中,由所述目标大型语言模型生成对应的回复;
29、所述打分模型还用于对所述新题目对应的回复进行打分以获得打分结果,并且,所述评估者模块还用于基于打分结果较低的新题目发掘所述目标大型语言模型的弱点并将所述弱点发送给所述主考官模块,使所述主考官模块基于所述弱点更新所述考点体系。
30、优选地,所述针对大型语言模型的自动化缺陷检测方法,其特征在于,进一步包括以下步骤:
31、标准模型基于所述新题目生成对应的参考答案;
32、微调模块基于所述新题目及其对应的参考答案对所述目标大型语言模型进行微调。
33、与现有技术相比,本发明的针对大型语言模型的自动化缺陷检测系统及方法具有如下有益技术效果中的一者或多者:
34、1、本发明是是目前为止第一个在通用任务上系统探索llm缺陷发掘过程的系统,并且在指令遵从、数学、代码等任务上进行了充分的验证。
35、2、相比现有技术,本发明能够对llm的缺陷进行针对性、高效的搜索,在gpt-3.5、claude-3-sonnet等多个主流llm上有着高于30%的缺陷检测成功率。
36、3、本发明还可以帮助llm提升性能,通过从缺陷中学习,可以让llm在多个任务上产生10%左右的性能提升。
本文地址:https://www.jishuxx.com/zhuanli/20241015/316574.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表