一种基于分层索引、混合检索的大模型RAG方法与流程
- 国知局
- 2024-10-21 15:26:44
本发明属于rag大模型,具体涉及一种基于分层索引、混合检索的大模型rag方法。
背景技术:
1、在当前的自然语言处理(nlp)领域,检索增强生成(retrieval-augmentedgeneration,简称rag)技术是提升模型生成质量和准确性的关键策略之一。随着大模型技术的进展,有效利用大规模文本数据源以生成更加精准和详尽的回答变得尤为重要。
2、传统的rag技术主要通过以向量库的形式来存储和检索嵌入在向量库中的知识,早期实践中,大量文档被编码为连续向量,并存储在能够快速进行相似度计算和信息检索的索引结构中。当接收到用户问题时,系统通过计算问题向量与语料库中文档向量的相似度来检索相关信息。然而,这种方法在处理大规模、多样化的文档内容和跨领域应用时显示出几个局限性:
3、1.检索速度瓶颈:随着语料库规模的急剧增长,向量检索可能会变得相当耗时。由于需要计算并排序与查询向量相似的所有文档向量,这会导致响应延迟,影响用户体验。
4、2.定位准确性下降:单一的向量化检索机制可能难以精确捕捉到文本的细微语义差别和复杂概念关联。即使是在高维向量空间中,也存在“语义鸿沟”问题,即相似度高的向量不一定在语义上完全匹配,这可能导致检索结果与实际需求存在一定偏差。
5、3.多领域适应性问题:传统的单一向量化检索机制常因无法精确捕捉复杂的概念关联和专业术语差异而受限。
6、4.动态学习和更新:在传统rag技术的应用中,系统的静态性是一个显著的局限。一旦知识库建立,其内容的更新频率往往不足,导致模型难以适应快速变化的信息需求。
技术实现思路
1、本发明的目的是克服现有技术的不足而提供一种具有提高检索速度、保证检索精准、多领域适应及动态学习和更新的基于分层索引、混合检索的大模型rag方法。
2、本发明的技术方案如下:
3、一种基于分层索引、混合检索的大模型rag方法,包括如下步骤:
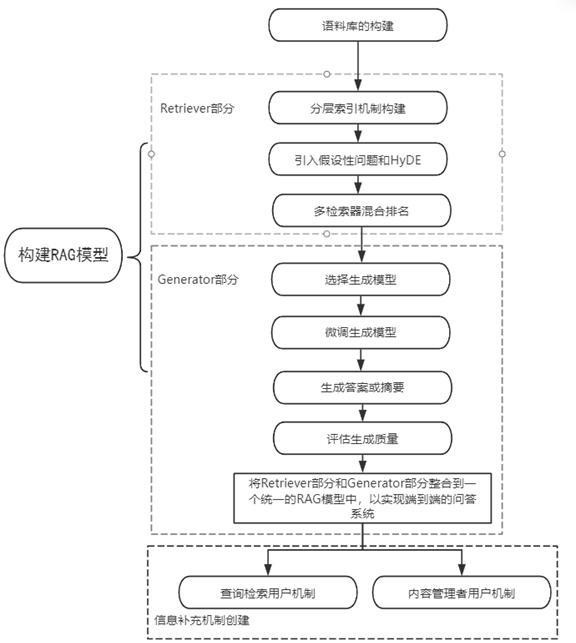
4、s1、语料库的构建;
5、s2、构建rag模型:将rag模型分为retriever和generator两部分,其中retriever部分包括分层索引机制的构建、引入假设性问题和hyde以及多检索器混合排名,generator负责生成答案或摘要;
6、s3、信息补充机制创建,建立仅支持查询的检索用户和内容管理者用户的两种用户使用方式,所述检索用户仅支持对语料库的查询检索,所述内容管理者用户能够对现有知识库内容进行标注、修改、补充。
7、进一步,所述步骤s1中的语料库的构建过程如下:
8、对语料库进行预处理,包括分词、去除停用词、词干提取;
9、所述分词的处理通过分词工具实现;
10、去除停用词的处理为除了常规的停用词列表外,根据具体语料库特点,可引入领域相关的停用词列表。
11、进一步,所述步骤s2中的分层索引机制的构建包括:创建两个索引且两个索引分别包含摘要和所有的文档块,并先利用摘要筛选相关文档,再在这些相关文档中进行具体搜索。
12、进一步,所述步骤s2中的引入假设性问题和hyde包括利用大语言模型的语义理解和生成能力为语料库的每个块生成一个预设问题,并根据查询生成一个假设性回应,然后使用假设性回应向量与查询向量共同进行搜索。
13、进一步,所述步骤s2中的多检索器混合排名包括通过结合多个检索器进行结果的重新排名,在获取检索结果后,通过过滤、重新排名或特定的转换方法来优化检索结果,获取最终知识匹配结果。
14、进一步,所述步骤s2中的generator部分包括:
15、选择生成模型:选择合适的生成模型,用于根据检索到的文档或段落生成答案或摘要;
16、微调生成模型:收集或准备相关的训练数据,训练数据包括输入和相应的输出或标签,确保数据质量和数量足以支持模型的微调,明确定义任务和模型的输入输出,根据任务的特点和要求,设计好输入的格式和输出的内容,之后通过训练数据进行训练生成模型,使得生成模型符合后续任务的需求,并使用验证集及交叉验证等方法对微调后的模型进行评估;
17、生成答案或摘要:使用微调后的生成模型,根据检索到的文档或段落生成答案或摘要,生成的答案或摘要应该尽可能准确地回答用户的问题或总结文档内容;
18、评估生成质量:对生成的答案或摘要进行评估,以确保其质量和准确性,之后使用自动评估结合人工评估来评估生成质量;
19、整合retriever和generator:将retriever和generator部分整合到一个统一的rag模型中,以实现端到端的问答系统。
20、进一步,所述步骤s3中的内容管理者用户机制包括:内容管理者用户拥有相较于检索用户更高权限,能够对问答系统提出问题、添加注释或修改现有回答,问答系统支持文本标注和注释标注两种类型,文本标注用于生成和优化回答,注释标注用于进一步解释问题和回答,所述文本标注和注释标注的信息自动整合到知识库中。
21、与现有技术相比,本发明的有益效果是:
22、1、本发明提出的分层索引机制的构建,通过摘要索引+全文索引的定位机制,有效提升了本地知识融入大模型过程中的快速定位、精准回答的能力。
23、2、本发明通过引入假设性问题和hyde,生成预设问题和假设性回应,并使用假设性回应向量与查询向量共同搜索,有效提高搜索相关性和搜索质量。
24、3、本发明通过引入除向量搜索外的其他搜索机制,结合多检索器进行融合排名,得出最终知识匹配结果。
25、4、本发明通过设置信息补充机制可以对知识库中知识进行进一步的更新与补充,可以实现大模型对于特定场景或者特定词汇补充,且可以避免多文件对同一内容的解释存在歧义。
技术特征:1.一种基于分层索引、混合检索的大模型rag方法,其特征在于,包括如下步骤:
2.根据权利要求1所述的一种基于分层索引、混合检索的大模型rag方法,其特征在于:所述步骤s1中的语料库的构建过程如下:
3.根据权利要求1所述的一种基于分层索引、混合检索的大模型rag方法,其特征在于:所述步骤s2中的分层索引机制的构建包括:创建两个索引且两个索引分别包含摘要和所有的文档块,并先利用摘要筛选相关文档,再在这些相关文档中进行具体搜索。
4.根据权利要求1所述的一种基于分层索引、混合检索的大模型rag方法,其特征在于:所述步骤s2中的引入假设性问题和hyde包括利用大语言模型的语义理解和生成能力为语料库的每个块生成一个预设问题,并根据查询生成一个假设性回应,然后使用假设性回应向量与查询向量共同进行搜索。
5.根据权利要求1所述的一种基于分层索引、混合检索的大模型rag方法,其特征在于:所述步骤s2中的多检索器混合排名包括通过结合多个检索器进行结果的重新排名,在获取检索结果后,通过过滤、重新排名或特定的转换方法来优化检索结果,获取最终知识匹配结果。
6.根据权利要求1所述的一种基于分层索引、混合检索的大模型rag方法,其特征在于:所述步骤s2中的generator部分包括:
7.根据权利要求6所述的一种基于分层索引、混合检索的大模型rag方法,其特征在于:所述步骤s3中的内容管理者用户机制包括:内容管理者用户拥有相较于检索用户更高权限,能够对问答系统提出问题、添加注释或修改现有回答,问答系统支持文本标注和注释标注两种类型,文本标注用于生成和优化回答,注释标注用于进一步解释问题和回答,所述文本标注和注释标注的信息自动整合到知识库中。
技术总结本发明提供了一种基于分层索引、混合检索的大模型RAG方法。主要包括以下步骤:S1、语料库构建;S2、构建RAG模型,将RAG模型分为Retriever和Generator两部分,其中Retriever基于分层索引机制、引入假设性问题、HyDE以及多检索器混合排名负责快速定位相关文档或段落,而Generator负责生成答案或摘要;S3、信息补充机制,旨在为系统提供及时动态的知识更新能力。该机制能够及时收集用户在查询过程中提出的注释、修改的查询问题及其对应的回答调整。通过这一机制,内容管理者可以对系统反馈进行及时的信息标注和修改,从而确保知识库内容的准确性和时效性。技术研发人员:聂志锋,张琳,赵瑞,范军,王祎童,金杨,房璐,张廷彪受保护的技术使用者:北京市大数据中心技术研发日:技术公布日:2024/10/17本文地址:https://www.jishuxx.com/zhuanli/20241021/321560.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表