一种基于Res2Net模型改进的数学公式识别方法
- 国知局
- 2024-11-06 14:32:56
本发明涉及公式识别,尤其涉及一种基于res2net模型改进的数学公式识别方法。
背景技术:
1、数学公式识别技术是纸质文献电子化转录领域的一项关键技术,其意义和应用价值不容忽视,由于数学公式通常包含复杂的结构和符号,例如上下标、分数线、根号以及各种数学符号的组合,使得数学公式难以被直接录入电子设备,尤其是当涉及到手写或印刷体文献中的公式时,传统的文本输入方法和光学字符识别技术往往难以准确识别和处理。
2、数学公式识别研究不仅在学术和教育领域内具有重要价值,也为其他领域的光学字符识别技术的进步提供了宝贵的经验和技术积累。手写体识别技术面临的挑战包括字迹多样性、书写风格的个性化差异等,这些问题的解决对于提高光学字符识别技术的准确性和鲁棒性具有指导意义,也促进了整个光学字符识别领域的技术进步。
3、传统的数学公式识别通常包括字符分割、字符识别和结构重组三个主要步骤。首先,字符分割阶段旨在将复杂的数学表达式分解成单个字符,为后续的识别过程提供输入。其次,字符识别阶段对每个分割出来的字符进行识别,并尝试将其映射到对应的数学符号或字符。最后,识别到的字符将被重新组装成完整的数学公式,完成整个数学公式识别的过程。
4、数学公式的latex序列通常比图像描述任务中的文字要长得多。这种差异主要源于数学公式的复杂性和灵活性。相较于自然语言描述的对象,数学公式通常包含更多的符号、运算符和结构。因此,为了准确地表示数学公式,需要更长的序列长度来捕捉其丰富的信息和结构,这是与图像描述任务相比的一个显著特点,常规的编码器解码器框架通常很难应对长序列问题,注意力机制则可以很好的应对这种情况,因为注意力机制可以使模型在解码时注意应该注意的地方,尽管注意力机制可以在一定程度上缓和长序列给编码器解码器模型带来的问题,但是常规的注意力机制可能会出现过度注意或缺失注意的问题,也就是模型在解码阶段重复注意了某个特征,使得模型做了错误的解码输出。
5、基于深度学习的数学公式识别模型通常采用编码器解码器框架。在这种框架下,模型利用卷积神经网络从数学公式图像中提取特征,并将其转换为固定维度的中间向量。这些中间向量被传递到解码器中,解码器将中间向量解码成latex序列,即最终的数学公式表示。这种编码器解码器框架能够有效地处理数学公式识别任务,使得模型能够端到端地完成从数学公式图像到latex序列的转换。数学公式的复杂结构、多样的符号类型和不同长度,特征提取的精确程度很大概率上决定了最终数学公式识别模型的效果,因此对于用来提取特征的编码器设计是数学公式识别任务的重点。目前常用的图像特征提取网络通常使用卷积神经网络及其变体,包括alexnet、vggnet、densenet、resnet等。
6、尽管不同的识别方法可能存在一定的差异,但是数学公式识别过程中普遍面临的挑战主要源于数学符号的多样性和大小,以及数学公式相对复杂和灵活的层次结构。数学符号可能具有不同的形状、尺寸和风格,这增加了识别的难度。此外,数学公式的层次结构通常较为复杂,包含多个嵌套的子表达式和运算符,同时数学公式本身的组成结构不仅包含了左右结构,还有上下结构如指数下标等和内外嵌套的包围型结构如根号等,一个数学表达式的组成形式非常灵活,因此怎样关注并正确识别这种二维结构的数学公式也是一个难题。所以需要准确地捕捉和表示其结构,其中数学公式识别技术也存在如下挑战:其一,数学符号的多样性和复杂性以及层次结构的灵活性导致识别难度巨大,因此如何准确地捕捉和表示其结构是一个急需的解决的问题;其二,用于提取特征的编码器设计是数学公式识别任务的重要环节,如何改进编码器是当前和未来的一个重要研究课题。
7、众所周知,resnet又称为深度残差网络,是一个当前用于图像特征提取网络的最重要方法之一,其方法正是为了解决网络退化问题而提出,并且也可以缓解过拟合和梯度消失或爆炸的问题,对随后的深层神经网络的设计产生了深远影响,无论是卷积类网络还是全连接类网络,几乎现在所有的网络都会用到,因为只有这样才能够让网络搭建的更深,因此已经被广泛用于各个领域,res2net是resnet的变体,通过改进resnet中的残差模块,增加更小的残差连接,从而扩大每层残差块的感受野,在几乎不改变计算量的前提下,提高了网络提取多尺度特征的能力,res2net结构通过其特有的残差连接方式和多尺度特征表示,有效地提取了图像中的全局和局部特征,非常适合具有多尺度特征的数学公式识别任务,但是数学公式具有明显的二维结构特,即横向和纵向特征,然而res2net不考虑横向和纵向特征,因此仅仅使用res2net作为数学公式识别任务中的编码器来提取特征是不够的。综上所述,如何针对现有的res2net模型进行改进、提高数学公式识别能力,成为了本领域技术人员亟待解决的技术问题。
技术实现思路
1、本发明所要解决的技术问题是克服现有技术中存在的不足,提供一种基于res2net模型改进的数学公式识别方法。
2、本发明是通过以下技术方案予以实现:
3、一种基于res2net模型改进的数学公式识别方法,包括如下步骤:
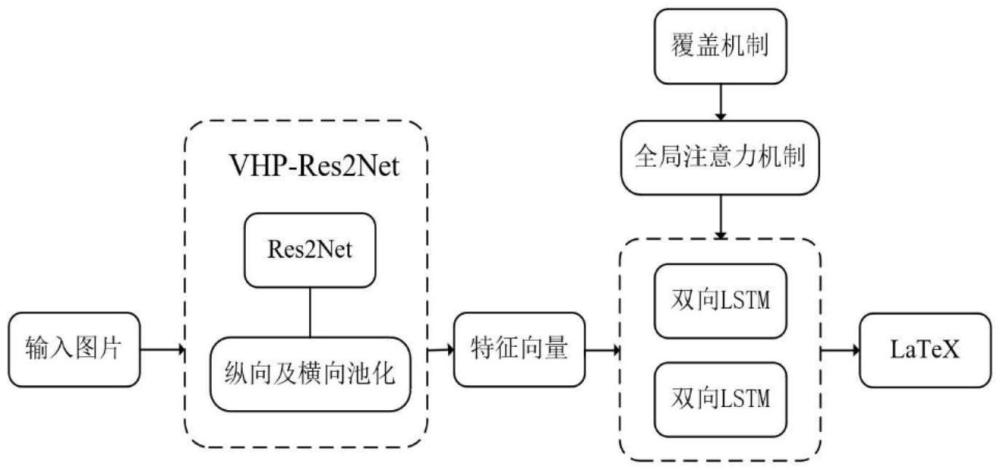
4、s1.输入待识别的数学公式图像;
5、s2.基于res2net模型提取所述数学公式图像中水平、垂直方向的特征信息,获取一系列特征向量,作为解码器的输入特征序列;
6、s3.基于lstm作为解码器,利用注意力机制,对所述输入特征序列解码成latex序列,即最终的数学公式表示。
7、根据上述技术方案,优选地,步骤s1中,对所述数学公式图像进行字符分割,分解成单个字符。
8、根据上述技术方案,优选地,步骤s2包括:
9、对所述数学公式图像分别进行纵向池化和横向池化,并将其相加作为后续残差块的输入;
10、在编码器中提取所述残差块的全局和局部特征,得到一系列特征向量。
11、根据上述技术方案,优选地,步骤s3中,所述解码器采用两个前向层和两个反向层的4层lstm堆叠作为解码器的模型架构。
12、根据上述技术方案,优选地,步骤s3包括:
13、利用注意力机制,根据当前的解码状态动态地从输入序列中选择与当前生成的目标词元最相关的信息,计算出位置的权重;
14、结合步骤s2中的特征向量得到新的向量,输入解码器中进行解码,输出latex形式的数学公式。
15、根据上述技术方案,优选地,步骤s3中,引入注意力机制后,在每个解码时间步t时,可以动态的从源特征序列中v={v1,...,vi}计算相关的注意力权重;
16、在解码时间步t时,上下文向量ct的计算公式为:
17、
18、其中,表示在解码器时间步t时,源位置i处的特征vi对上下文向量ct贡献的权重大小,为t时刻的注意力权重分布,定义为:
19、
20、其中,ht表示解码器在时间步t时lstm隐状态,score(vi,ht)用来度量vi和ht之间的相关性,并且
21、wa1,wa1分别表示对应vi和ht权重。
22、根据上述技术方案,优选地,步骤s3中,引入覆盖机制,机制通过记录每一步解码时已经关注过的输入特征序列位置的历史信息,来调整后续步骤的对齐位置。
23、本发明的有益效果是:
24、本发明基于res2net改进,对res2net中的初始的最大池化操作进行替换,即先分别进行纵向池化与横向池化再相乘,这样可以在一定程度上加强数学公式中的纵向及横向特征,从而提升模型性能,即形成本发明改进后的模型编码器vhp-res2net,可以有效的提取数学公式中的多尺度特征,能够对数学公式中的微小特征进行有效的识别;
25、解码器层使用了双向长短时记忆网络,这可以使得模型在数学公式识别任务中不仅可以利用到历史的信息,同样也要利用未来的信息。并且为了进一步提升解码性能,使用两个双向长短时记忆网络堆叠;
26、本发明的模型中引入了全局注意力机制,使得模型在解码输出时可以注意到应该注意的地方,加强了模型在应对长序列数学公式时的性能,并且提出了覆盖机制来抑制已经被注意过的特征的权重,进而缓解了过度注意或缺失注意的问题。
本文地址:https://www.jishuxx.com/zhuanli/20241106/322757.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表