一种基于多目标强化学习的无人机控制方法与流程
- 国知局
- 2024-11-06 15:04:14
本发明属于无人机飞行控制,具体而言,涉及一种基于多目标强化学习的无人机控制方法。
背景技术:
1、复杂六自由度无人机模型有着强非线性以及状态变量耦合的特点,传统控制方法需要对模型在配平点处进行线性化,利用得到的线性化模型来设计控制器,由于线性化模型引入的误差,这些控制器仅在配平点附近保证了收敛性,为了保证全包线范围内的控制效果,还需要在各种不同的配平点处重新调节控制器参数,导致控制器的设计费时费力,另外针对具体无人机构型发展的控制方法在其它无人机构型上也没有办法直接使用。
2、近年来,应用强化学习技术解决无人机控制问题得到了越来越多的关注,强化学习方法不仅可以绕开控制器设计对模型的依赖,而且控制效果上限高。
3、现有基于强化学习的无人机控制方法将奖励设计为多个不同控制目标奖励的加权求和,为了寻找适合控制任务的奖励需要对权重系数进行手动试错寻优,耗费大量时间。
4、多目标强化学习用以解决存在多个目标的学习问题,不同目标可能具有不同的重要性,因此需要在不同目标之间进行权衡,找到满足要求的最优解,故如何根据无人机控制要求定义多目标优化结构并基于多目标强化学习自适应的调节各控制目标的权重系数是目前需要解决的问题。
技术实现思路
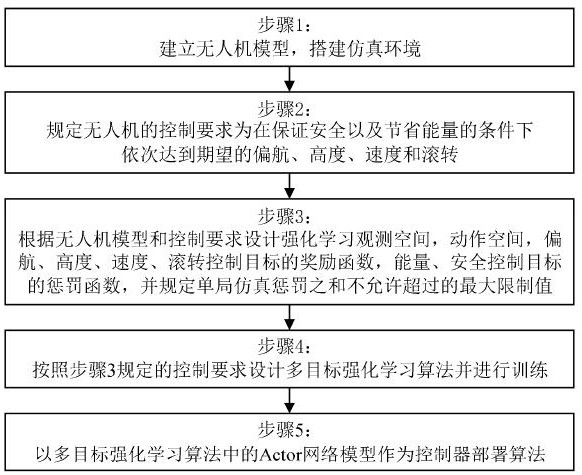
1、针对以上缺陷,本发明提供了一种基于多目标强化学习的无人机控制方法,包括以下步骤:
2、s1、建立无人机模型,并搭建仿真环境:
3、s1-1、定义坐标系;
4、s1-2、模型的构建,包括六自由度固定翼模型的平动动力学模型的构建、六自由度固定翼模型的转动动力学模型的构建、六自由度固定翼模型的平动运动学模型的构建、六自由度固定翼模型的转动运动学模型和发动机建模为一阶延迟模型的构建;
5、s1-3、搭建仿真环境,包括初始化模块、算法动作输出模块、模型解算模块和仿真结束判断模块;
6、s2、规定无人机的控制要求为在保证安全以及节省能量的条件下依次达到期望的偏航、高度、速度和滚转;
7、s3、根据无人机模型和控制要求设计强化学习观测空间,动作空间,偏航、高度、速度、滚转控制目标的奖励函数,能量、安全控制目标的惩罚函数,并规定单局仿真惩罚之和不允许超过的最大限制值;
8、s4、按照步骤s2规定的控制要求设计多目标强化学习算法并进行训练;
9、s4-1、按照步骤s2的控制要求,定义多目标强化学习的优化问题;
10、s4-2、选择多目标强化学习依赖的基础强化学习算法;
11、s4-3、采用拉格朗日松弛技术求解多目标强化学习优化问题的无约束对偶问题;
12、s5、以多目标强化学习算法actor网络模型作为控制器部署算法。
13、进一步地,所述步骤s1-2中的六自由度固定翼模型的平动动力学模型为:
14、;
15、上述式中,分别为的微分形式,分别为固定翼体轴系下的速度分量,其中是前进速度,是横向速度,是垂直速度,为固定翼体轴系下的角速度分量,其中是绕x轴的角速度,是绕y轴的角速度,是绕z轴的角速度,为重力加速度,为偏航角,为滚转角,为来流动压,为机翼参考面积,为机体轴三个方向的气动力系数,为发动机推力,为固定翼质量;
16、六自由度固定翼模型的转动动力学模型为:
17、;
18、上述式中,为转动惯量,、、和、、分别为在x、y、z轴方向和在xz、xy、yz平面上的转动惯量,,,分别为的微分形式,为固定翼体轴系下的角速度分量,其中是绕x轴的角速度,是绕y轴的角速度,是绕z轴的角速度,为机翼平均几何弦长,为来流动压,分别为机体轴三个方向的气动力矩系数,为发动机旋转质量的角动量大小,为机翼参考面积,为机翼展长;
19、与的关系如下:
20、;
21、上述式中,为空速,分别为迎角和侧滑角,分别为固定翼体轴系下的速度分量,其中是前进速度,是横向速度,是垂直速度;
22、六自由度固定翼模型的平动运动学模型为:
23、;
24、上述式中,分别为平面大地坐标系下的北向位置、东向位置和高度,分别为的微分形式,分别为固定翼体轴系下的速度分量,其中是前进速度,是横向速度,是垂直速度;
25、六自由度固定翼模型的转动运动学模型为:
26、;
27、上述式中,为固定翼体轴系下的角速度分量,其中是绕x轴的角速度,是绕y轴的角速度,是绕z轴的角速度,为偏航角,为俯仰角,为滚转角,,,分别为,,的微分形式;
28、发动机建模为一阶延迟模型:
29、,
30、,
31、,
32、,
33、,
34、上述式中,为发动机期望推力水平,为发动机延迟推力水平,为的微分形式,为变量,为油门,为平面大地坐标系下的高度,为马赫数,为发动机推力,为发动机时间常数。
35、进一步地,所述步骤s1-3中的初始化模块用于设置仿真开始时无人机的初始状态变量值和期望控制输出,算法动作输出模块经过多目标强化学习算法计算得到无人机的控制变量,模型解算模块以当前无人机的状态变量和控制变量作为输入得到下一时刻的状态变量,仿真结束判断模块用于判断当前仿真是否结束。
36、本发明与现有技术相比具有以下有益效果:
37、1、基于多目标强化学习方法,按照设计的无人机控制要求,自适应的调节无人机控制中存在的多目标权重,减少了奖励函数设计对专家知识的依赖,避免了奖励函数设计中对多目标权重反复尝试的过程,能够快速得到控制器;
38、2、基于多目标强化学习方法绕开了控制器设计对模型的依赖,能够应用于固定翼和多旋翼控制器设计,而且控制效果上限高。
技术特征:1.一种基于多目标强化学习的无人机控制方法,其特征在于:包括以下步骤:
2.如权利要求1所述的一种基于多目标强化学习的无人机控制方法,其特征在于:所述步骤s1-2中的六自由度固定翼模型的平动动力学模型为:
3.如权利要求1所述的一种基于多目标强化学习的无人机控制方法,其特征在于:所述步骤s1-3中的初始化模块用于设置仿真开始时无人机的初始状态变量值和期望控制输出,算法动作输出模块经过多目标强化学习算法计算得到无人机的控制变量,模型解算模块以当前无人机的状态变量和控制变量作为输入得到下一时刻的状态变量,仿真结束判断模块用于判断当前仿真是否结束。
技术总结本发明公开了一种基于多目标强化学习的无人机控制方法,包括模型的构建和仿真环境的搭建、规定无人机控制要求、根据控制要求设计多目标强化学习进行训练以及以多目标强化学习算法Actor网络模型作为控制器部署算法的步骤;通过规定无人机的控制要求为在保证安全以及节省能量的条件下依次达到期望的偏航、高度、速度和滚转,提出多目标强化学习算法自适应的调整各控制目标权重,以满足规定的控制要求。本发明解决了在无人机控制场景中,强化学习奖励函数设计存在的多目标权重确定问题,减少了奖励函数设计对专家知识的依赖,避免了对多目标权重反复尝试的过程,能够快速得到控制器。技术研发人员:周尧明,张超越,于智行,杨帆,石含玥,李少伟,林成浩受保护的技术使用者:天目山实验室技术研发日:技术公布日:2024/11/4本文地址:https://www.jishuxx.com/zhuanli/20241106/325168.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表