一种可执行sql语句的sql元素解析方法与流程
- 国知局
- 2024-11-21 11:37:06
本发明涉及数据分析,尤其涉及一种可执行sql语句的sql元素解析方法。
背景技术:
1、在现代数据仓库环境中,sql是处理和管理数据的主要工具,数据仓库中的sql任务往往涉及复杂的查询、插入、更新和删除操作,这些操作会影响多个数据表和字段,因此,跟踪数据流向和记录sql任务中引用的数据表信息是至关重要的,这些信息可以用于调试、优化和审计等目的;传统上,数据流向和数据表引用的记录是通过手动注释和日志记录来完成的,但这种方法效率低下且容易出错;为了自动化和简化这一过程,可以使用sql解析技术来自动提取sql语句中的关键元素,并记录相关信息。
2、公开号为cn104199831b的专利文献公开了一种信息处理方法及装置,该方法包括:基于第一策略识别出sql代码中的基本元素;对从所述sql代码中解析出的基本元素进行组合操作,得到sql语句,构建语法树;遍历所述语法树中的sql语句,基于所遍历的sql语句中的基本元素的类型,以及所述基本元素的类型与节点的对应关系,为所遍历的sql语句中的基本元素对应构建节点,得到所述语法树的中间语言描述;基于所述语法树的中间语言描述,构建对应所述sql代码的数据流图;由此可见,现有的sql解析技术中缺乏自动提取sql语句中的表名、字段等关键信息,并记录数据流向和数据表引用的信息,使人为错误的可能性较高和解析sql语句效率低。
技术实现思路
1、为此,本发明提供一种可执行sql语句的sql元素解析方法,用以克服现有技术中缺乏多阶段计算相似度和自动提取sql语句中最匹配的表名、字段等关键信息,并记录数据流向和数据表引用的信息,使解析sql语句准确率低的问题。
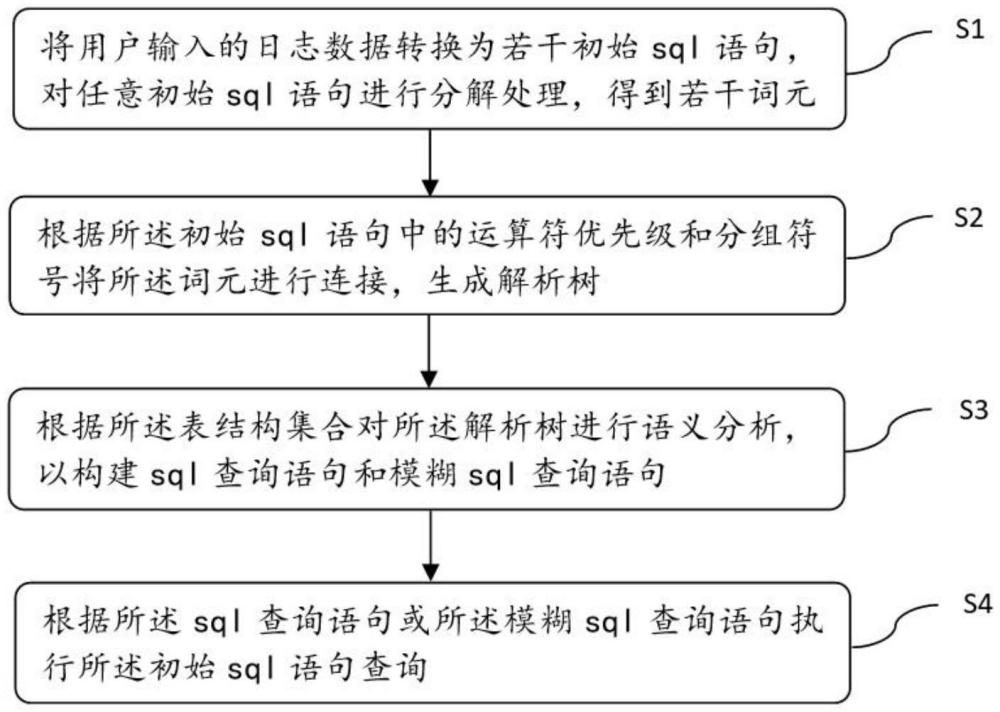
2、为实现上述目的,本发明提供一种可执行sql语句的sql元素解析方法,包括,
3、将用户输入的日志数据转换为若干初始sql语句,对任意初始sql语句进行分解处理,得到若干词元;
4、根据预定义的语法规则分析所述词元的顺序和结构排列是否正确,以根据所述初始sql语句中的运算符优先级和分组符号将所述词元进行连接,生成解析树;
5、访问数据库中的元数据视图,以提取表结构集合,根据所述表结构集合对所述解析树进行语义分析,根据所述语义分析结果识别表名和投影字段,并根据识别出的表名和投影字段构建sql查询语句,所述sql查询语句为目标sql查询语句或模糊sql查询语句;
6、根据所述sql查询语句生成查询步骤列表,以指示所述数据库执行所述初始sql语句查询并输出查询结果,根据所述查询结果确定是否对标准相似度进行调整。
7、进一步地,所述表结构集合包括若干表名集和若干列名集,根据所述表结构集合对所述解析树进行语义分析包括,
8、提取所述解析树中的关键词,将所述解析树的关键词与各所述表名集中的单词或所述列名集中的单词进行匹配;
9、根据匹配结果计算匹配相似度、集合相似度和关联相似度。
10、进一步地,所述匹配相似度包括列名匹配相似度和表名匹配相似度,计算所述匹配相似度包括,
11、将与所述关键词匹配的单词标记为匹配字段;
12、获取存在匹配字段标记的各所述表名集作为候选表名集,或获取存在匹配字段标记的各所述列名集作为候选列名集;
13、分别计算各所述候选表名集中匹配字段个数占所述候选表名集中总词数的百分比,得到对应的表名匹配相似度,分别计算各所述候选列名集中匹配字段个数占所述候选列名集中总词数的百分比,得到对应的列名匹配相似度。
14、进一步地,所述集合相似度包括表名集合相似度和列名集合相似度,计算所述集合相似度包括,
15、在不存在表名匹配相似度大于等于标准相似度,或不存在列名匹配相似度大于等于标准相似度时,根据所述解析树的关键词构建关键词集合;
16、计算所述关键词集合和所述候选表名集的表名集合相似度,或计算所述关键词集合和所述候选列名集的列名集合相似度。
17、进一步地,所述关联相似度包括表名关联相似度和列名关联相似度,计算关联相似度包括,
18、在不存在表名集合相似度大于等于标准相似度,或不存在列名集合相似度大于等于标准相似度时,在所述数据库中获取所述关键词的关联实体,将所述关联实体与所述候选表名集中的单词或与所述候选列名集中的单词进行匹配;
19、计算修正表名个数和匹配字段个数之和占所述候选表名集中总词数的百分比,得到表名关联相似度;
20、或计算修正表名个数和匹配字段个数之和占所述候选列名集中总词数的百分比,得到列名关联相似度。
21、进一步地,根据所述语义分析结果识别表名和投影字段包括,
22、根据匹配相似度、集合相似度或关联相似度选取所述sql查询语句的表名、投影字段、待检测表名和待检测投影字段。
23、进一步地,根据所述表名和投影字段构建所述目标sql查询语句,获取执行所述目标sql查询语句的实时响应时长,在实时响应时长大于标准响应时长时,对所述标准相似度进行调整,调整为修正第一相似度。
24、进一步地,根据所述待检测表名和所述待检测投影字段构建模糊sql查询语句;
25、获取执行所述模糊sql查询语句的实时响应时长;
26、在实时响应时长小于等于标准响应时长时,判定查询结果符合预期,对所述标准相似度进行调整,调整为修正第二相似度,将所述待检测表名和所述待检测投影字段储存在所述数据库中。
27、进一步地,获取执行所述模糊sql查询语句的实时响应时长,在实时响应时长大于标准响应时长时,初步判定查询结果不符合预期,输出错误提示。
28、进一步地,将用户输入的日志数据转换为初始sql语句包括,
29、对所述日志数据进行预处理,生成输入文本;
30、根据问号的位置将所述输入文本分割为若干初始sql语句。
31、与现有技术相比,本发明的有益效果在于,通过自动将用户输入的自然语言问句通过一定的转化规则转换成在数据库中可以执行的sql查询语句,通过对sql语句进行分词处理,将整个sql语句分解为各个词元,自动提取sql语句中的表名、字段等关键信息,并记录数据流向和数据表引用的信息,解析用户输入的sql查询语句,根据预定义的sql语法规则检查词元是否按照正确的顺序和结构排列,避免输入格式错误的数据,以实现快速查询和精准分析数据,通过动态生成并执行sql查询语句,确保查询结果的实时性和准确性,通过构建和优化查询,提高生成sql查询语句的准确率,进而提高查询的精准性和查询效率。
32、进一步地,由于有些问句未指定sql语句的所有必要组成成分,例如表名或者投影字段,则通过将解析树中的关键词与数据库中的单词进行文本匹配,以预测和构建sql查询语句,进而确保将用户输入的查询准确地转换为可执行的sql查询,从而提高系统的适用性。
33、进一步地,通过关联识别别称,修正sql语句的表达方式,以提取匹配的词汇作为表名或投影字段,避免遗漏匹配项,从而提高生成sql查询语句的准确性,进而提高查询效率。
34、进一步地,通过对构建的sql查询语句的执行情况进行分析,以优化sql查询语句的生成方法,通过在初步判定查询结果不符合预期时,将标准相似度调大,以使落入生成目标sql查询语句的可能性减小,使落入生成模糊sql查询语句的可能性增大,以提高选取表名和投影字段的精准性,从而提高查询质量。
35、进一步地,通过对执行模糊sql查询语句的实际时长进行分析,以确定生成的待检测表名和待检测投影字段的精准性,若判定实时响应时长小于等于标准响应时长,表示查询结果符合预期,表示生成的待检测表名和待检测投影字段的精准性较高,则将待检测表名和待检测投影字段作为新增数据储存在数据库中,通过适应性调小标准相似度,减少不必要的严格判定,节省时间和计算资源,使整个检测过程更加灵活和高效,验证查询结果的准确性,提高数据质量。
本文地址:https://www.jishuxx.com/zhuanli/20241120/332051.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。