一种基于置信掩膜引导对比学习的半监督医学图像分割方法
- 国知局
- 2024-11-21 11:39:01
本发明涉及医学图像处理,具体为一种基于置信掩膜引导对比学习的半监督医学图像分割方法。
背景技术:
1、医学图像分割是在医学图像处理中的一个重要任务,其目标是识别图像中的目标区域,如器官、病灶或细胞等,可应用于疾病的诊断、手术的规划等方面,辅助医生进行临床治疗。在早期,医学图像分割主要依赖于专家的经验和人工操作,这种方法虽然较为准确,但是效率低下,且易受主观因素影响。因此,开发出分割精度高的自动化分割技术有着重要的意义。随着深度学习技术的发展,人们开发出了一系列基于深度学习的医学图像分割技术,使用卷积神经网络(cnn)提取图像的特征信息,经过训练得到的基于cnn的神经网络分割模型具有较高的准确度。然而,早期基于深度学习的医学图像分割技术主要基于全监督学习方式,这些分割模型往往需要使用大量的标注数据训练才能获得不错的性能,这在医学图像处理任务中不易实现,因为医学图像数据具有隐私性、稀缺性特点,且对其进行标注需要专家复出大量的精力和时间。
2、为了解决上述问题,半监督学习技术吸引了人们的关注。与基于全监督范式的医学图像分割方法相比,半监督学习技术可以利用有限的标签数据和大量的无标签数据训练网络,使得分割模型获得优秀的分割性能,非常适合医学图像分割任务。主流的半监督医学图像分割技术大多都使用mean-教师框架,这种框架包含两个分支:学生分支和教师分支,并且两个分支使用相同的网路结构,其中教师分支的权重参数由学生分支的指数移动平均权重构成。这种框架可以使得网络更加稳定。然而,基于mean-教师框架的半监督医学图像分割也存在问题:(1)在监督学习过程中,学生分支使用少量的标签数据训练,这会导致学生分支学习到有限的、不可靠的特征信息,这些特征信息随后被更新到教师分支,导致教师分支在进行无监督学习过程中,生成不可靠的伪标签,影响整个网络的分割准确度。(2)在监督学习过程中,学生分支仅仅使用数量有限的标签数据,而忽略了无标签数据的价值,这会导致学生分支学习到的特征信息不够全面,容易产生过拟合问题。
技术实现思路
1、本发明的目的在于提供一种基于置信掩膜引导对比学习的半监督医学图像分割方法,用于提高医学图像自动化分割的性能。
2、为解决上述技术问题,本发明的技术方案为:一种基于置信掩膜引导对比学习的半监督医学图像分割方法,包括以下步骤:
3、s1:收集医学图像数据集并对图像进行预处理,构建训练集和测试集;
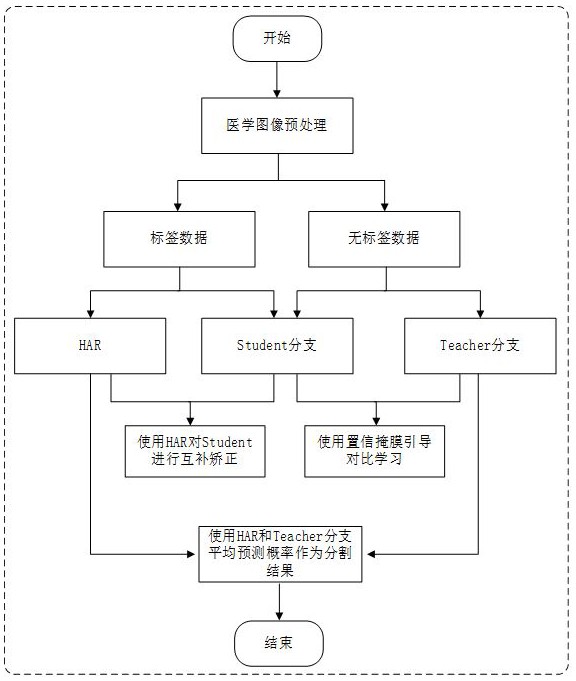
4、s2:搭建半监督医学图像分割网络模型,所述半监督医学图像分割网络模型包括:基础mean-教师网络模型、异构辅助矫正网络分支(har)。
5、所述基础mean-教师网络模型包括一个学生分支和一个教师分支,学生分支和教师分支使用相同的网络结构,采用v-net作为mean-教师网络模型的骨干网络,并且使用学生分支的exponential moving average(ema)权重更新教师分支的权重。
6、所述har分支采用与v-net相同的encoder,而decoder采用resnet34网络的decoder。
7、在三个分支的decoder的第二层后,分别添加一个分类器,分类器使用相同的网络结构。在学生分支和教师分支中decoder的第二层还分别添加一个投影器,两个投影器使用相同的网络结构。
8、s3:监督学习阶段,对有标签数据与无标签数据交叉动量混合,然后输入到学生网络和har分支,使用har分支监督学生网络训练,纠正学生分支的预测错误,并且为其提供互补信息;
9、s4:无监督学习阶段,对无标签数据使用cutout强扰动,然后输入到三个分支,通过分类器得到的置信掩膜以及投影器选取正/负样本对,进行对比学习;
10、s5:将训练集输入到所述半监督医学图像分割网络模型进行训练,获得训练好的半监督医学图像分割网络模型;
11、s6:将测试集输入到训练好的半监督医学图像分割网络模型,获取医学图像分割结果。
12、本发明的有益效果为:
13、本方案利用基于置信掩膜引导对比学习的半监督医学图像分割模型对医学图像进行自动化分割,设计了一种三分支半监督医学图像分割模型,引入了
14、一个har分支到mean-教师框架中,以解决现有基于mean-teache框架的半监督医学图像分割模型中由于ema更新策略导致分割精度差的问题。此外,本发明还开发了一种新的基于置信掩膜引导的对比学习采样策略,另外,还设计了一种交叉动量混合技术,以解决传统半监督医学图像分割技术中忽略对无标签数据利用的问题。最后,在无监督学习阶段引入了cutout技术,进一步在无监督学习阶段充分挖掘无标签数据的价值。
15、进一步的,所述预处理具体过程为:对收集到医学图像数据随机裁切为统一尺寸,并进行随机旋转、随机高斯噪声数据增强,扩增数据集;
16、进一步的,所述半监督医学图像分割网络模型采用的损失函数由监督损失函数和无监督损失函数组成。监督损失函数包括dice损失函数、交叉熵损失函数互补矫正损失函数;无监督损失函数包括一致性损失函数和对比损失函数;
17、进一步的,所述的交叉动量混合方法用于在监督学习阶段利用无标签数据提供更全面的特征信息,具体过程为:计算一个batch中每个无标签数据的均值μ和方差σ,使用动量更新方式获取该batch的动量均值μb和动量方差σb:
18、
19、式中,表示batch中i-1个无标签数据的动量均值,表示batch中i-1个无标签数据的动量方差。在获取动量均值μb和动量方差σb后,与标签数据进行交叉动量混合:
20、
21、式中,il'表示当前标签数据更新后的特征图,il表示当前标签数据的原始特征图,μl、σl分别表示当前标签数据的均值和方差。
22、进一步的,所述的使用har分支监督学生网络训练,纠正学生分支的预测错误,并且为其提供互补信息,具体过程为:
23、将经过交叉动量混合的有标签数据输入到学生分支和har分支,分别得到两个预测:通过两个预测结果可以得到学生网络对标签数据的预测结果的潜在区域:
24、
25、其中,rpot为潜在区域,包含由异构网络提供的互补信息和可能的错误预测信息。计算互补矫正损失lmr来优化学生网络对潜在区域的预测准确度:
26、
27、其中,式中e表示逐元素相乘,表示学生网络对标签数据的预测结果中对应于rpot区域的概率图,异构辅助矫正网络对标签数据的预测结果中对应于rpot区域的概率图,ypot表示对应于rpot区域的ground truth。
28、学生网络和异构辅助矫正网络分支可以对同一个数据生成不完全相同的预测结果,那么对于有差异的预测部分,这部分可作为潜在区域,潜在区域可能存在一些错误预测,同时异构辅助矫正网络分支还可以针对潜在区域为学生网络提供补充信息;
29、进一步的,所述的无监督学习阶段,对无标签数据使用cutout强扰动,然后输入到三个分支,通过分类器得到的置信掩膜以及投影器选取正/负样本对,进行对比学习,具体过程为:在无监督学习过程中,我们首先对无标签数据使用cutout强扰动,然后输入到学生网络、har分支和教师网络。我们在三个分支网络的decoder中第三层分别添加了一个分类器,在学生分支和教师分支的decoder第二层卷积层后分别添加一个投影器。分类器的输入是上一层卷积层的输出的特征图,三个分类器分别输出三个掩膜——pseudo-mask,将得到的三个psudo-mask进行逻辑与操作,得到一个新的mask——confidence positive mask(cpm),接着对cpm进行逻辑非操作得到confidence negative mask(cnm)。投影器的输入是上一层卷积层输出的特征图,学生分支和教师分支的投影器分别输出两个特征图:fs,ft。将cpm分别于fs,ft逐元素相乘,在fs,ft上分别获取对应于cpm的区域,分别记为:我们从上的采取正样本,对应位置像素为正样本对。接着将cnm与ft逐元素相乘,在ft上获取对应于cnm的区域,记为我们在上选择负样本对,它们之间的像素均为负样本。在对正负样本对进行采样后,我们使用体素级对比损失将正样本拉到一起,并扩大负样本之间的边缘,从而提高相似体素之间的紧凑性和不同类别体素之间的可分离性。给定一个锚点体素j,计算对比损失:
30、
31、其中,k+表示从中提取的正样本,表示从选取的负样本,n是采样的负样本数量,τ是一个温度参数。
32、进一步的,所述的将测试集输入到训练好的半监督医学图像分割网络模型,计算har分支和教师分支的平均预测结果,作为最终的医学图像分割结果。
本文地址:https://www.jishuxx.com/zhuanli/20241120/332213.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。